




 Lunec是一种用于全文检索的开放源代码引擎工具包,适用于结构化和非结构化数据查询。本文详细介绍了Lunec的全文索引流程,包括数据分类、索引创建、查询步骤以及测试环境的配置,还涉及了分词器的选择和索引库的维护。
Lunec是一种用于全文检索的开放源代码引擎工具包,适用于结构化和非结构化数据查询。本文详细介绍了Lunec的全文索引流程,包括数据分类、索引创建、查询步骤以及测试环境的配置,还涉及了分词器的选择和索引库的维护。
Lunece
全文检索技术
什么是全文检索
数据分类
数据总体分为两类:
- 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
- 非机构化数据:指不定场或无固定格式的数据,入邮件,worf文档等磁盘上的文件
结构化数据查询方法
数据库搜索
数据库中的搜索很容易实现,通常都是使用SQL语句进行查询,而且能很快得得到结果。
为什么数据库搜索很容易?
因为数据库中的数据存储是有规律的,有行有列而且数据格式、数据长度都是固定的。
非结构化数据查询方法
- 顺序扫描法
所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫米啊完所有的文件,如利用windows的搜索也可以搜索文件内容,只是相当的慢。
2.全文检索
将非结果化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
这种先建立索引,再对苏音进行搜索的过程就叫全文索引。
虽然创建索引的过程也是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,所以耗时间创建索引是值得的。
如何实现全文检索
可以使用Lunece实现全文检索。Lunece是apache下的一个开放源代码的全文检索引擎工具包。提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lunece的目的是为软件开发人寰提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能。
Lunece实现全文索引的流程
索引和搜索的流程图
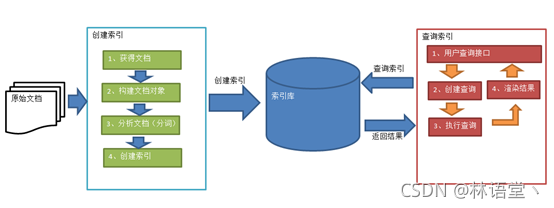
1、绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引口,索引过程包括:
确认原始内容即要搜索的内容采集文档、创建文档、分析文档、索引文档
2、红色表示搜索过程,从索引口中搜索内容,搜索过程包括:
用户通过搜索界面、创建查询、执行搜索,从索引口搜索渲染搜索结果
创建索引
对文档索引的过程,将用户要搜索的文档内容进行索引,索引存储在索引库中。
获取原始文档
原始文档是指要索引的搜索的内容。原始内容包括互联网上的网页,数据库中的数据,磁盘上的文件等。
从互联网上、数据库、文件系统中等获取需要搜索的原始信息,这个过程就是信息采集,信息采集的目的是为了对原始内容进行索引。
在Internet上采集信息的软件通常成为爬虫,也成为网络机器人,爬虫访问互联网上的每一个网页,获取到的网页内容存储起来。
此次,使用构造数据来模拟数据。
创建文档对象
获取原始内容的目的是为了索引,在索引前需要将原始内容创建成文档(Document)、文档中包括一个一个的域(Field),域中存储内容。
这里我们可以将磁盘上的一个文件当成一个document,Document中包括一些Field(file_name文件名称、file_path文件路径、file_size文件大小、file_content文件内容),如下:

注意:每个Document可以有多个Field,不同的Document可以有不同的Field,同一个Document可以有相同Field(域名和域值都相同)
每个文档都有一个唯一的编号,就是文档Id。
分析文档
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程最终的语汇单元,可以将语汇单元理解为一个一个的单词。
比如下边的文档经过分析如下:
原始文档内容:
Lunece is a Java full-text search rngine. Lunch is not a comlete application, but rather a code library and API that can easily be used to add search capabilities to applications.
分析后得到的语汇单元:
Lunece、Java、full、search、engine 。。。
每个单词叫做一个Term,不同的域中拆分出来的相同的单词是不同的term。term中包含两部分一部分是文档的路径,另一部分是单词的内容。
例如:文件名中包含apache和文件内容中包含apache是不同的term。
创建索引
对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到Document(文档)
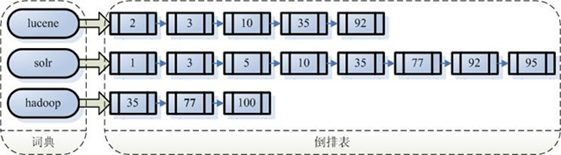
注意:创建索引是对语汇单词索引,通过词语找文档,这种索引的结构叫倒排索引结构。
传统方法是根据文件找到该文件内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大,搜索慢。
倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。
查询索引
查询索引也是搜索的过程,搜索就是用户输入关键字,从索引(index)中进行搜索的过程。根据关键字搜索索引,根据索引找到对应的文档,从而找到要搜索的内容。
用户查询接口
全文检索系统提供用户搜索界面供用户提交关键字,搜索完成展示搜索结果。
Lunece不提供制作用户搜索界面的功能,需要根据自己的需求开发搜索界面
创建查询
用户输入查询关键子执行搜索之前需要先构建一个查询对象,查询对象中可以指定要查询要搜索的Field文档域,查询关键字等,查询对象会生成具体的查询语法,
例如:
语法“filename:Lunece“表示要搜索Field域的内容为”Lunece“的文档
执行查询
搜索索引过程:
根据查询语法在倒排索引词典表中分别找出对应搜索的索引,从而找到索引所链接的文档列表。
比如搜索语法为“fileName:lunece”表示搜索出fileName域中包含Lunece的文档。
搜索过程就是在索引上查找域为filename,并且关键字为Lunece的term,并根据term找到文档id列表。
渲染结果
以一个友好的界面将查询结果展示给用户,用户根据搜索结果找到自己想要的信息,为了帮助用户很快找到自己的结果,提供了很多展示的效果,比如搜索结果中将关键字高亮显示,百度提供的酷爱等。
测试案例——配置开发环境
Lunece是开发全文检索功能的工具包,从官方网站上下载lunece-7.4.0,并解压
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-neafLoJH-1635609658982)(img/MyLunece/image-20201220195413939.png)]
官方网站:http://lucene.apache.org/
版本:lunece-7.4.0
jdk要求:1.8以上
或者使用maven
<!--核心包-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>5.3.1</version>
</dependency>
<!--一般分词器,适用于英文分词-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>5.3.1</version>
</dependency>
<!--编码转换 -->
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.0</version>
</dependency>
入门程序
需求:
实现一个搜索功能,通过关键字搜索文件。
模拟数据:
// 模拟数据
public static final List<Student> list =new ArrayList<Student>(
Arrays.asList(new Student("1","张三",18,"北京市海淀区温泉镇","法外狂徒"),
new Student("2","李四",19,"北京市海底区东升镇","唱、跳、rap"),
new Student("3","王武",20,"北京市海淀区上庄镇","吸烟、喝酒、烫头"),
new Student("4","王五",21,"北京市海淀区苏家坨镇","点烟、倒酒、给别人烫头"),
new Student("5","麻六",18,"北京市海淀区西北旺镇","吃饭、喝酒"),
new Student("6","酸菜",17,"统一老坛酸菜牛肉面","带着酸菜"),
new Student("7","麻辣",10,"统一麻辣牛肉面","带着没有牛肉的牛肉面"),
new Student("8","老母鸡",14,"康师傅老母鸡汤面","没有老母鸡的老母鸡面"),
new Student("9","酱香",15,"酱香味小龙虾","88元一斤"),
new Student("10","蒜蓉",19,"蒜蓉味小龙虾","100元一斤")));
创建索引
1、创建一个Java程序。
2、创建一个indexWriter对象。
指定索引库的存放位置Directory对象(FSDirectory.open 来获取)
指定一个IndexWriterConfig对象(IndexWriterConfig需要analyzer对象)。
3、创建document对象。
4、创建field对象,将field对象添加到document对象中。
5、使用indexWriter对象将document对象写入索引库,此过程进行索引创建,并将索引和docuemnt对象写入索引库
6、关闭indexWriter对象。
代码:
// 2、创建一个indexWriter对象。
IndexWriter indexWriter=new IndexWriter(FSDirectory.open(Paths.get(CreateIndexes.path)),new IndexWriterConfig(new StandardAnalyzer()));
// 指定索引库的存放位置Directory对象
// 指定一个IndexWriterConfig对象(IndexWriterConfig需要analyzer对象)。
// 3、创建document对象。
Document document=null ;
// 4、创建field对象,将field对象添加到document对象中。
List<Student> list1 = CreateIndexes.list;
for (Student stu : list1) {
document= new Document();
// Field 参数: 域的名称、域的内容、是否存储
document.add(new TextField("id" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6354
6354




 到【灌水乐园】发言
到【灌水乐园】发言







