 Kettle数据抽取与转换详解
Kettle数据抽取与转换详解








 Kettle,又称PDI,是一款开源ETL工具,提供数据抽取、转换和装载功能。通过图形化界面Spoon进行操作,包含转换(Transformation)和作业(Job)两大核心,支持多种数据源操作。转换由步骤组成,数据以行形式流动,实现并发执行。Kettle还涉及数据建模和定时任务执行。了解Kettle,可助力高效数据管理。
Kettle,又称PDI,是一款开源ETL工具,提供数据抽取、转换和装载功能。通过图形化界面Spoon进行操作,包含转换(Transformation)和作业(Job)两大核心,支持多种数据源操作。转换由步骤组成,数据以行形式流动,实现并发执行。Kettle还涉及数据建模和定时任务执行。了解Kettle,可助力高效数据管理。
一、Kettle简介
Kettle是一个开源的ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程)项目。 项目名很有意思,水壶。按项目负责人Matt的说法:把各种数据放到一个壶里,然后呢,以一种你希望的格式流出。
Kettle 也叫 PDI,在2006年 Kettle 加入了开源的 BI 组织 Pentaho, 正式命名为PDI,英文全称为Pentaho Data Integeration。
Spoon是一个图形用户界面,它允许你运行转换或者任务,其中转换是用Pan工具来运行,任务是用Kitchen来运行。Pan是一个数据转换引擎,它可以执行很多功能,例如:从不同的数据源读取、操作和写入数据。Kitchen是一个可以运行利用XML或数据资源库描述的任务。通常任务是在规定的时间间隔内用批处理的模式自动运行。
Kettle官网:Pentaho+ Platform for Complete Data Management | Pentaho
二、Kettle架构
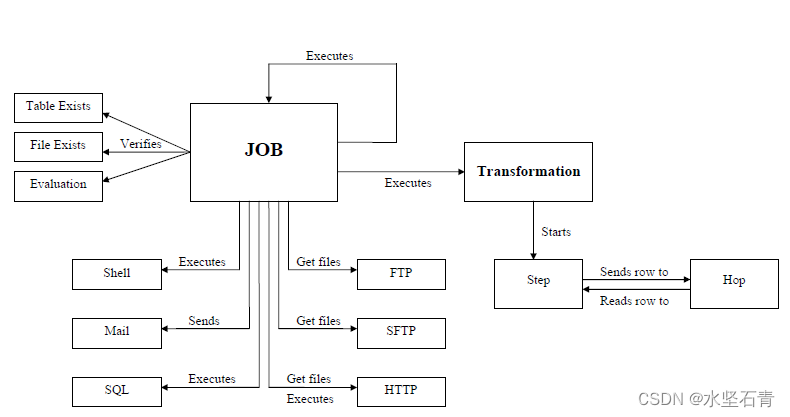
transformation完成针对数据的基础转换,好比工厂里的生产流水线,每个组件相当于一个员工;job则完成整个工作流的控制,好比工厂里的管理。
三、Kettle功能
1. 转换:Transformation :ETL的所有操作;
2. 作业:Job 定时执行,可以包含多个转换;
3. 模型:Model(早期版本单独作为一个模块) 数据建模,便于交流。
转换包括一个或多个步骤,步骤之间通过跳(hop)来连接。跳定义了一个单向通道,允许数据从一个步骤流向另一个步骤。在Kettle中,数据的单位是行,数据流就是数据行从一个步骤到另一个步骤的移动。 步骤:是转换的基本组成部分,以图标的形式出现。如(表输入、文本文件输出)。步骤将数据写到与之相连的一个或多个输出跳,再传送到跳的另一端的步骤。这说明,跳是步骤之间带箭头的连线,其实是两个步骤之间的,被称为行集(rowset)的,数据行缓存。(行集的大小可以在转换里定义)
一个步骤的数据发送分复制和分发两种模式;分发:把一份数据平均分配给后面步骤;复制发送:把一份数据复制成多份,后面步骤各占一份。(shift + 鼠标左键 可以快速地新建一个跳) 在Kettle中,所有的步骤都以并发的方式执行,当转换启动后,所有的步骤都同时启动,从它们的输入跳中读取数据,并把处理过的数据写到输出跳,直到输入跳里不再有数据,就中止步骤的运行。当所有的步骤都中止了,整个转换就中止了。 数据行:一个数据行是零到多个字段的集合。
四、Kettle核心
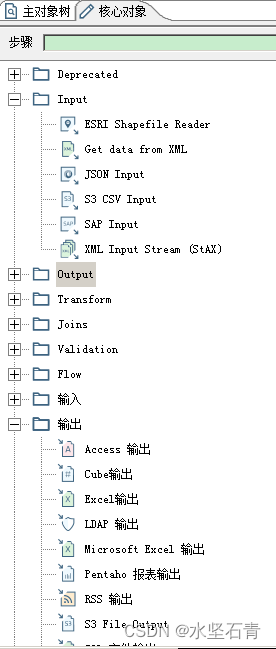
1.转化核心对象

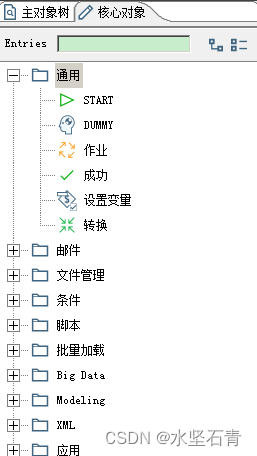
2.作业核心对象

五、Kettle实例
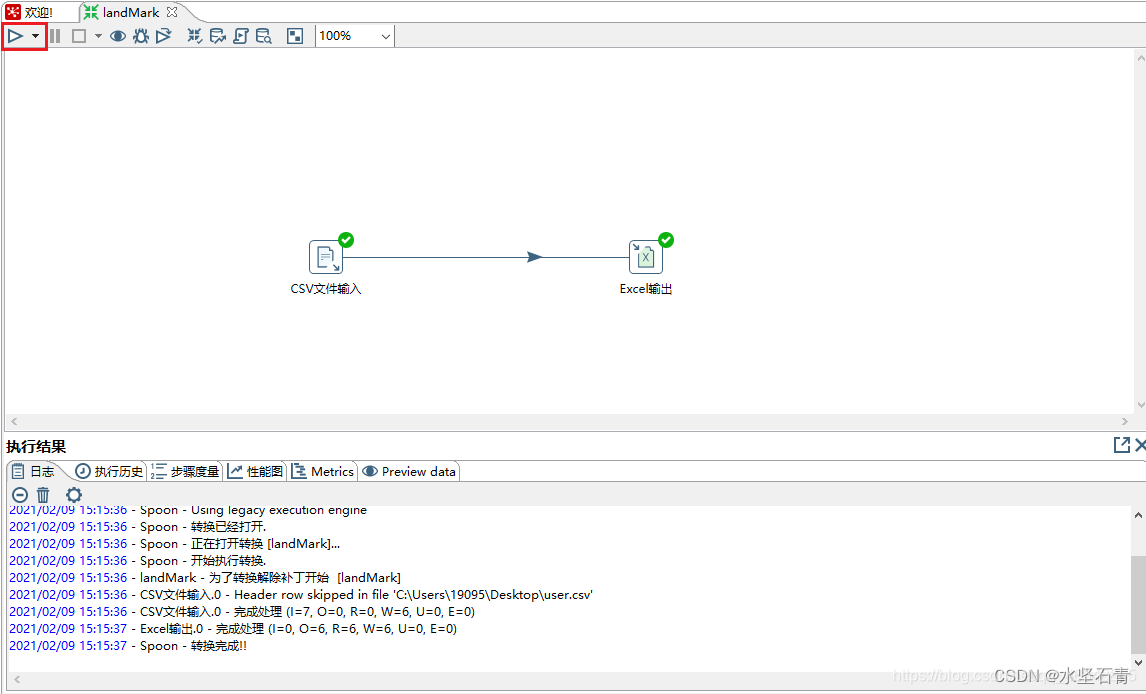
六、其他事宜
1.系列文章
2.侵权事宜
如有侵权请联系我删除。
3.支持博主
如果您觉得此文对您有帮助,请点赞、关注、收藏。祝您生活愉快!


















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











