




一、论文概述
关于这篇论文代码已经复现出来,有需要可以找我
1. 研究背景与问题
遥感图像分割面临两大核心挑战:类内异质性(如不同纹理的云)和类间同质性(如农田与草地),尤其在细粒度任务(如云厚度区分、草地覆盖度分级)中,现有方法依赖 “隐式特征学习”,无法根据输入上下文动态调整语义嵌入,导致分割精度不足。
1. 什么是隐式特征学习?
隐式特征学习(implicit representation learning)是一种模型设计范式,其中类别语义信息(如“云”“草地”的嵌入表示)是通过网络隐含学习的,而非显式建模。具体来说:
-
运作方式:模型通过卷积或注意力机制直接从数据中学习特征表示,但类别嵌入(class embeddings)是固定的或隐含在整体参数中,不会根据输入图像的具体内容(如场景变化、形态差异)进行动态调整。
-
论文中的描述:现有方法(如CNN或Transformer模型)依赖隐式学习,它们模型无法针对输入图像的独特特征(如云层纹理变化)自适应优化类别表示,导致在类内异质性(同一类别的不同形态)和类间同质性(不同类别的相似外观)场景中表现不佳。
-
示例:在遥感图像中,隐式学习可能无法区分薄云与厚云,因为它们的嵌入是静态的,无法捕捉细微形态差异。
2. “无法根据输入上下文动态调整语义嵌入”的含义
这一局限性指模型不能根据输入图像的上下文信息(如场景结构、物体形态)动态优化类别语义嵌入,从而导致:
-
缺乏适应性:语义嵌入(例如,类ID的向量表示)在训练后固定不变,无法响应输入特定特征。例如,同一类别(如“农田”)在不同图像中可能呈现不同纹理,但静态嵌入无法捕捉这些变化。
-
后果:在细粒度分割任务中(如云厚度区分),模型容易混淆相似类别,因为嵌入无法根据上下文细化。
-
与显式方法对比:隐式学习依赖全局参数,而显式方法(如论文提出的动态字典)会主动构建和迭代调整类别嵌入,使其更具判别力。
2. 核心贡献
- 提出动态字典学习框架:显式建模类 ID 嵌入,通过对比损失增强类内紧凑性与类间分离性,优化细粒度分割性能。
这是框架的总体思想,旨在创建和优化一个显式的、具有高度判别性的语义字典。
-
1. 显式建模类 ID 嵌入(Explicitly Modeling Class ID Embeddings):
-
是什么:与传统隐式学习不同,该方法显式地定义了一个字典 D∈RN×C′,其中 N是类别数量,C′是嵌入维度。字典中的每一行 D[i]就是一个类别(如“类别i”)的语义表示向量。这个向量在网络训练过程中作为可学习参数被共同优化。
-
为什么有效:这相当于为每个类别创建了一个“原型”或“标准模板”。在解码阶段,模型通过计算图像特征与这些原型之间的相似度来生成分割结果,使学习过程更加透明和可控。
-
-
2. 对比损失增强判别性(Contrastive Loss for Discriminability):
-
问题:仅仅显式定义字典还不够。如果不同类别的嵌入在向量空间里距离很近(即类间相似度高),模型仍然会混淆相似类别。
-
解决方案:论文为动态分支的损失函数引入了字典对比损失(Lcon),它由两部分组成:
-
类内紧凑性损失(Lintra): 最小化同一类别内不同样本嵌入(如不同图像中的“厚云”嵌入)与它们的类别中心之间的平均距离。这迫使同一类的嵌入向量在向量空间中“聚拢”。
-
类间分散性损失(Linter): 最大化不同类别中心之间的平均距离。这相当于在向量空间中推开不同类别的嵌入。
-
-
作用:通过这项约束,字典学习到的不仅仅是类别特征,更是具有高度判别性的特征。它确保了“厚云”和“薄云”的嵌入向量在向量空间中相距甚远,从而极大改善了细粒度分割的性能。
-
-
设计调制器:将静态字典转换为动态字典,利用输入特异性注意力图捕获类内形态差异。
这是实现字典“动态化”的关键模块,使字典能根据输入图像内容进行自适应调整。
-
1. 静态字典的局限性:如果字典 D在整个训练和推理过程中完全固定不变,那么它就无法捕捉同一类别在不同输入图像中的形态变化(例如,不同纹理的“农田”)。
-
2. 调制器的工作机制:调制器的作用是根据当前输入图像的特征,生成一个注意力图,来“调制”或“变换”静态字典。
-
输入:编码器提取的高层语义特征 F。
-
过程:特征 F被分成两半,分别通过全局平均池化(GAP) 和全局最大池化(GMP) 来聚合全局信息,然后经由MLP处理。两个分支的结果拼接后再通过一个MLP和Softmax,生成一个输入特定的注意力图 A∈RN×r。
-
输出:动态字典通过 D0=Ds⊗A计算得到,其中 ⊗是矩阵乘法。这意味着,对于每一张输入图片,静态字典 Ds都会被一个独特的注意力图 A进行加权调整,从而生成一个适应本图片内容的动态字典 D0。
-
-
3. 核心优势:此机制使模型能够捕获类内形态差异。例如,对于一张以“薄云”为主的图片,调制器会自动调整“云”这个类别的嵌入,使其更偏向“薄云”的特征表示,从而提升分割精度。
-
构建多阶段交替交叉注意力解码器:迭代优化图像特征与语义字典,实现双向互促,提升分割鲁棒性。
这是框架的执行引擎,通过迭代式的交互,同时优化图像特征和字典嵌入。
-
1. 交替交叉注意力(Alternating Cross-Attention):
-
解码过程不是一步完成的,而是进行了 L个阶段(通常 L=3)。在每个阶段 l,发生两次交叉注意力查询:
-
图像特征查询字典(Feature-to-Dictionary): 以当前图像特征 El−1作为 Query,以当前动态字典 Dl−1作为 Key 和 Value。目的是让图像特征从字典中“汲取”最相关的语义信息,来更新自己(得到 El)。这可以理解为“让图像特征弄清楚每个位置应该关注哪个类别”。
-
字典查询图像特征(Dictionary-to-Feature): 然后,角色互换。以更新后的动态字典 Dl−1作为 Query,以更新后的图像特征 El作为 Key 和 Value。目的是让每个类别的嵌入向量根据图像的具体细节进行自我 refinement(得到 Dl)。这可以理解为“让类别原型根据实际图像调整得更准确”。
-
-
-
2. 迭代优化与双向互促(Iterative Refinement and Mutual Promotion):
- 这种“你一次,我一次”的交替机制,创造了图像特征和语义字典之间双向的、相互促进的优化循环。图像特征在字典的指导下变得更纯净、更具语义性;同时,字典嵌入在图像特征的反馈下变得更精确、更具代表性。
二、算法模型详解(核心部分)
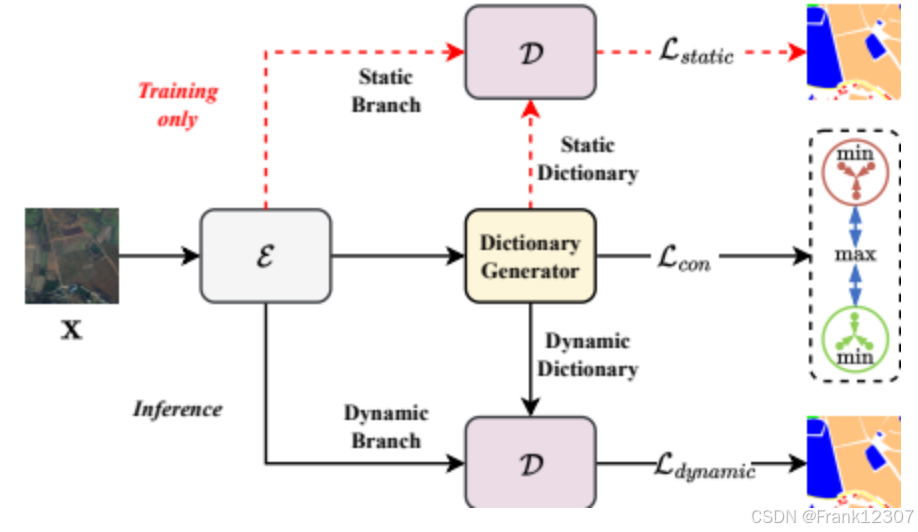
下图(Figure 1)清晰地展示了模型的整体训练流程,其中编码器(E)提取特征,然后分别输入到静态分支和动态分支,两个分支共享同一个解码器(D),并通过加权损失进行联合优化。
下图(Figure 2)则提供了网络架构的详细示意图,我们将以此为基础,逐一分解每个核心模块。
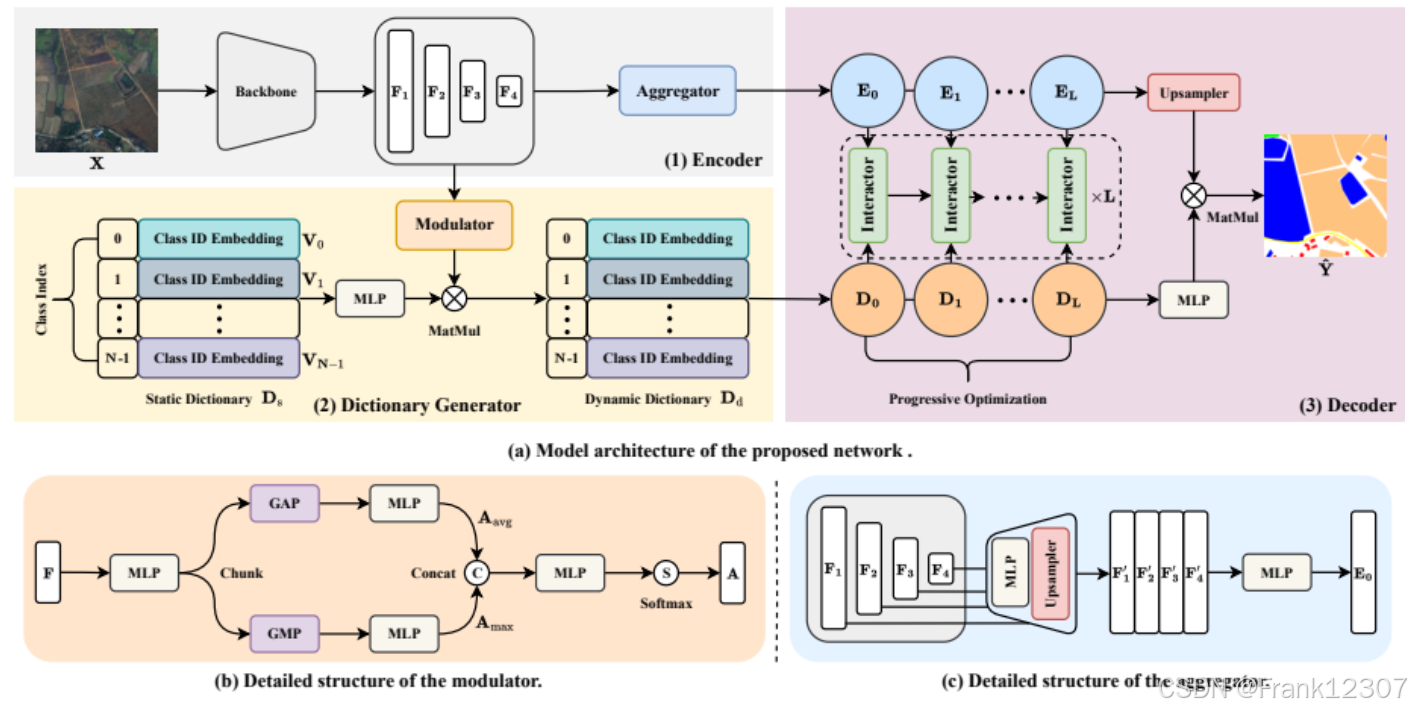
算法模型框架图详细解析
该网络架构主要由三大部分组成:编码器(Encoder)、字典生成器(Dictionary Generator) 和解码器(Decoder)。下面我们详细说明每个部分的结构与功能。
1. 编码器(Encoder)
-
功能:负责从输入图像中提取多层次、多尺度的特征表示。
-
详细工作流程:
-
骨干网络(Backbone):输入图像 X∈R3×H×W首先通过一个预训练的卷积神经网络(如论文中使用的ConvNeXt-Base),生成四个不同尺度的特征图 {Fi∈RCi×Hi×Wi}i=14。其中,随着层级加深,特征图的空间尺寸(Hi,Wi)逐渐减小,通道数(Ci)逐渐增加。
-
特征映射与聚合器(Aggregator):
-
特征映射(Feature Mapping):每个尺度的特征图 Fi通过一个多层感知机(MLP)进行通道变换,并上采样插值到统一的尺寸 H′×W′(通常是 F1的尺寸),得到 {Fi′∈RC′×H′×W′}i=14。
-
特征聚合(Feature Aggregation):将四个变换后的特征图沿通道维度拼接(Concat),再通过一个MLP进行融合,最终输出聚合后的高级语义特征图 E0∈RC′×H′×W′。公式为:E0=MLP(ϕ(F1′)∥ϕ(F2′)∥ϕ(F3′)∥ϕ(F4′))。
-
-
-
输出:聚合后的特征图 E0被同时送入字典生成器和解码器。
2. 字典生成器(Dictionary Generator)
这是整个框架的核心创新点,负责生成代表不同语义类别的嵌入向量(Embeddings)。
-
功能:创建并维护一个可学习的字典,其中每个“词条”对应一个语义类别(如建筑、道路、厚云等)。它包含静态和动态两种字典。
-
详细工作流程:
-
静态字典(Static Dictionary, Ds):
-
结构:一个可学习的参数矩阵 Ds∈RN×C′,其中 N是类别总数,C′是嵌入向量的维度。
-
作用:每个类别有一个固定的嵌入向量 Vi。在训练初期,它为模型提供稳定的类别初始表示。在推理时,静态字典不直接使用,但其知识被整合到动态字典中。
-
-
动态字典(Dynamic Dictionary):
-
调制器(Modulator):这是生成动态字典的关键部件。它从编码器输出的高层特征 F=F4中提取输入图像的特定信息,并生成一个注意力图(Attention Map)A。
- 过程:将特征 F沿通道切分为两半,分别进行全局平均池化(GAP)和全局最大池化(GMP),然后通过两个独立的MLP,将结果拼接后再通过一个MLP和Softmax归一化,得到 A∈RN×r(r为降维后的尺寸,默认为4)。
-
动态化:通过矩阵乘法将静态字典 Ds与注意力图 A相乘,得到初始的动态字典 D0∈RN×C′。公式为:D0=Ds⊗A。
-
作用:动态字典 D0不再是固定的,它会根据当前输入图像的内容进行自适应调整,从而能更好地捕捉类内形态变化(如不同厚度的云)。
-
-
3. 解码器(Decoder)
-
功能:通过图像特征与字典嵌入之间的交互,逐步优化特征表示并生成最终的分割图。
-
详细工作流程:多阶段交替交叉注意力查询(Multi-stage Alternating Cross-Attention Querying)
-
交互器(Interactor):解码器进行 L个阶段(默认 L=3)的迭代优化。在每个阶段 l,进行两种交叉注意力查询:
-
图像特征查询字典(Image-to-Dictionary):使用图像特征 El−1作为查询(Query),动态字典 Dl−1作为键(Key)和值(Value),进行交叉注意力计算。目的是让图像特征从字典中“汲取”最相关的类别语义信息,更新自身得到 El。
-
字典查询图像特征(Dictionary-to-Image):然后,使用更新后的动态字典 Dl−1作为查询(Query),更新后的图像特征 El作为键(Key)和值(Value),再次进行交叉注意力计算。目的是让每个类别的嵌入向量根据图像的具体特征进行细化,得到更精确的 Dl。
-
-
输出分割图:经过 L个阶段的交替优化后,得到最终的精炼图像特征 EL和动态字典 DL。将 EL上采样到原图尺寸 H×W,然后与 DL进行矩阵乘法,并通过Softmax函数,生成最终的分割预测图 Y^∈RN×H×W。
-
该算法框架通过编码器-字典生成器-解码器的协同工作,实现了从隐式学习到显式、动态学习的转变。编码器负责特征提取,字典生成器显式地构建并动态调整类别语义表示,而解码器通过多阶段交替注意力机制,使图像特征和字典嵌入相互优化,最终显著提升了模型在区分形态相似类别(如薄云 vs. 厚云)上的性能。这种设计有效地解决了传统隐式表示学习无法根据上下文动态调整语义嵌入的局限性。
1. 整体框架总览
- 训练阶段:双分支并行(静态分支 + 动态分支),共享编码器与解码器,通过联合损失优化模型参数。
- 推理阶段:仅保留动态分支,利用训练好的动态字典自适应输入图像,输出分割结果。
- 关键设计:以 “动态字典” 为核心,通过 “交替交叉注意力” 实现特征与字典的迭代优化,解决隐式学习的局限性。
2. 各模块详细设计
(1)编码器:多尺度特征提取与聚合
编码器负责将输入图像转换为统一维度的高层语义特征,为后续字典交互与分割提供基础。
| 步骤 | 处理细节 | 公式 / 参数 |
|---|---|---|
| 1. 多尺度特征生成 | 采用 ConvNeXt-Base 作为 backbone,输入图像 x∈R3×H×W,输出 4 个尺度的特征图 {Fi∈RCi×Hi×Wi}i=14,其中 Wi=W/2i、Hi=H/2i、Ci=C×2i(C 为基础通道数)。 | - |
| 2. 特征映射(Feature Mapping) | 对每个 Fi 执行: ① MLP 进行通道转换,将 Ci 统一为 C′(默认 256); ② 上采样(插值函数 ϕ(⋅)),将 Hi×Wi 对齐到 H1×W1(即 H′×W′=H/2×W/2); 输出对齐后的特征图 {Fi′∈RC′×H′×W′}i=14。 | Fi′=MLP(Fi)∘ϕ(Fi)(∘ 表示上采样) |
| 3. 特征聚合(Feature Aggregation) | ① 沿通道维度拼接 4 个 Fi′; ② 输入 MLP 进行特征融合,输出最终聚合特征图 E0∈RC′×H′×W′,传递给字典生成器与解码器。 | E0=MLP(Concat(F1′,F2′,F3′,F4′)) |
(2)字典生成器:静态→动态字典转换
字典生成器是模型核心,负责将 “固定类 ID 嵌入” 转换为 “输入自适应的动态字典”,实现显式语义建模。
① 静态字典(Static Dictionary Ds)
- 定义:可学习的类 ID 嵌入集合,维度为 RN×C′(N 为语义类别数,C′=256),每个元素 Vi∈RC′ 对应第 i 类的语义嵌入。
- 特性:训练阶段学习优化,训练结束后固定不变,仅用于静态分支。
- 作用:为动态字典提供初始类语义锚点,避免动态分支训练不稳定。
② 动态字典(Dynamic Dictionary Dd)
动态字典通过调制器(Modulator) 生成,随输入图像自适应调整,核心是 “注意力图调制静态字典”,步骤如下:
- 输入特征选择:取编码器输出的最高层语义特征 F4∈RC4×H4×W4(含全局场景信息,最适合语义调制)。
- 特征分块与池化:
- 将 F4 沿通道维度分为 2 个等大分块:Favg∈R(C4/2)×H4×W4 和 Fmax∈R(C4/2)×H4×W4。
- 对 Favg 执行全局平均池化(GAP),对 Fmax 执行全局最大池化(GMP),分别得到通道级特征 Aavg∈RC4/2 和 Amax∈RC4/2。
- 注意力图生成:
- 对 Aavg 和 Amax 分别通过 MLP 降维与非线性变换;
- 沿通道维度拼接两者,输入另一 MLP 后通过 Softmax 归一化,生成注意力图 A∈RN×r(r 为降维后的维度,控制调制粒度)。
- 动态字典计算:
- 静态字典 Ds 先通过 MLP 进行通道适配,再与注意力图 A 执行矩阵乘法,得到初始动态字典 D0∈RN×C′。
- 公式:D0=MLP(Ds)⊗A(⊗ 表示矩阵乘法)。
(3)解码器:多阶段交替交叉注意力优化
解码器通过 L 个阶段的交替交叉注意力,迭代优化动态字典 Dd 与图像特征 E,实现 “语义 - 特征双向校准”,步骤如下:
- 初始输入:解码器接收编码器的聚合特征 E0 和字典生成器的初始动态字典 D0。
- L 阶段迭代优化(默认 L=3,平衡性能与效率):
-
阶段 l(l∈[1,L]):D 查询 E(字典校准特征)
动态字典 Dl−1 作为查询,与图像特征 El−1 计算交叉注意力,更新字典为 Dl,确保字典贴合当前图像语义:Dl=softmax(dkDl−1⋅El−1⊤)⋅El−1
(dk=C′ 为注意力缩放因子,避免梯度消失)。
-
阶段 l:E 查询 D(特征校准字典)
更新后的字典 Dl 作为查询,与图像特征 El−1 再次计算交叉注意力,更新特征为 El,增强特征的类判别性:El=softmax(dkEl−1⋅Dl⊤)⋅Dl。
-
- 最终分割输出:
- 对迭代后的最终特征 EL 执行上采样(恢复至输入图像分辨率 H×W);
- 上采样后的特征与最终字典 DL 执行矩阵乘法,得到分割预测图 Y^∈RN×H×W。
三、损失函数设计(模型优化核心)
模型通过 “双分支损失 + 对比损失” 联合优化,确保分割精度与语义判别性,具体如下:
1. 静态分支损失(Lstatic)
仅用于训练阶段,基于静态字典的分割输出 Os 计算,解决基础分割问题与类别不平衡:Lstatic=Lce(Os,Y)+Ldice(Os,Y)
- Lce:交叉熵损失(Cross-Entropy),优化逐像素分类精度。
- Ldice:Dice 损失,聚焦预测与真值的重叠区域,缓解长尾类别(如细粒度云)的不平衡问题。
- Y∈RN×H×W:ground truth 分割标签。
2. 动态分支损失(Ldynamic)
训练阶段核心损失,基于动态字典的分割输出 Od 计算,额外加入对比损失增强语义判别性:Ldynamic=Lce(Od,Y)+Ldice(Od,Y)+Lcon
其中,对比损失 Lcon 是关键,分为 “类内紧凑损失” 和 “类间分散损失”:
-
① 类内紧凑损失(Lintra):最小化同类样本到类中心的欧氏距离,确保类内特征一致性:Lintra=B⋅N1∑i=1N∑b=1BDd(b,i)−μi22(B 为批次大小,Dd(b,i) 为第 b 个样本第 i 类的动态嵌入,μi=B1∑b=1BDd(b,i) 为第 i 类中心)。
-
② 类间分散损失(Linter):最大化不同类中心的欧氏距离,确保类间特征分离:Linter=N(N−1)1∑i=1N∑j=iN∥μi−μj∥22。
-
最终对比损失:Lcon=Lintra−λinter⋅Linter(λinter 为权重,论文中默认平衡两者)。
3. 总损失(Ltotal)
加权融合双分支损失,优先优化动态分支(因动态分支性能更优):Ltotal=λstatic⋅Lstatic+λdynamic⋅Ldynamic
- 超参数默认:λstatic=0.4,λdynamic=1.0。
四、完整运行流程(从输入到输出)
1. 训练流程(模型参数优化)
Step 1:数据预处理
- 输入:遥感图像(如 LoveDA 的 512×512 像素、UAVid 的 1024×1024 像素)与对应分割标签。
- 预处理:随机翻转、缩放、归一化(遵循各数据集标准协议,如 LoveDA 参考 [24,46],Grass 参考 [53])。
Step 2:编码器特征提取
- 输入图像 x 送入 ConvNeXt-Base backbone,生成 4 个多尺度特征图 F1∼F4。
- 特征聚合器对 F1∼F4 执行 “通道转换 + 上采样对齐 + 拼接融合”,输出聚合特征 E0。
Step 3:双分支并行计算
-
静态分支:
- 调用训练好的静态字典 Ds;
- E0 与 Ds 直接矩阵乘,上采样得到分割输出 Os;
- 计算 Lstatic=Lce(Os,Y)+Ldice(Os,Y)。
-
动态分支:
- 调制器处理 F4,生成注意力图 A;
- 计算初始动态字典 D0=MLP(Ds)⊗A;
- 解码器执行 L=3 阶段交替交叉注意力:
- 迭代更新 D1∼D3 和 E1∼E3;
- 上采样 E3,与 D3 矩阵乘得到分割输出 Od;
- 计算 Ldynamic=Lce(Od,Y)+Ldice(Od,Y)+Lcon。
Step 4:模型优化
- 计算总损失 Ltotal=0.4⋅Lstatic+1.0⋅Ldynamic;
- 采用 AdamW 优化器(初始学习率 1e-4,权重衰减 0.01),通过余弦退火调度器动态调整学习率;
- 反向传播总损失,更新编码器、字典生成器、解码器的所有可学习参数(静态字典 Ds 在此阶段学习);
- 重复 Step 2~Step 4,直至训练轮次结束(如 300 轮),保存模型权重与静态字典 Ds。
2. 推理流程(生成最终分割结果)
推理阶段仅保留动态分支,避免静态分支的局限性,流程简化如下:
Step 1:输入预处理
- 待分割遥感图像按训练时的归一化参数处理(如均值、标准差),无需数据增强。
Step 2:编码器特征提取
- 同训练 Step 2,输出聚合特征 E0 和最高层特征 F4。
Step 3:动态字典生成
- 调用训练好的静态字典 Ds;
- 调制器处理 F4 生成注意力图 A,计算初始动态字典 D0。
Step 4:解码器迭代优化与输出
- 解码器执行 L=3 阶段交替交叉注意力,得到 E3 和 D3;
- 上采样 E3 至输入分辨率,与 D3 矩阵乘得到分割预测图 Y^;
- 对 Y^ 执行 Argmax 操作,得到逐像素的类别标签(如 “厚云”“薄云”“建筑”),即为最终分割结果。
五、实验与结果生成(验证模型有效性)
1. 实验设置(确保结果可复现)
(1)数据集
分为粗粒度(大场景分割)和细粒度(精细类别区分)两类,覆盖 UAV 到卫星图像:
| 类型 | 数据集 | 任务场景 | 类别数 | 数据规模(示例) |
|---|---|---|---|---|
| 粗粒度 | LoveDA | 跨域土地覆盖(城乡) | 7 | 训练集 3259 张,测试集 815 张 |
| 粗粒度 | UAVid | UAV 城市动态场景 | 8 | 10 个视频序列,共 1000 帧 |
| 粗粒度 | Potsdam | 高分辨率航空影像 | 6 | 38 张 5120×5120 图像 |
| 粗粒度 | Vaihingen | 航空城市语义分割 | 6 | 33 张 1024×1024 图像 |
| 细粒度 | Cloud | 云类型区分(厚 / 薄 / 阴影) | 4 | 2000 张卫星云图 |
| 细粒度 | Grass | 草地覆盖度分级(低 - 高) | 5 | 1500 张草地遥感图 |
(2)硬件与参数
- 硬件:NVIDIA A100 GPU(40GB),Intel Xeon 8375C CPU;
- 超参数:batch size=4,类 ID 嵌入维度 = 256,迭代阶段 L=3,随机种子 = 42;
- 优化器:AdamW,初始 lr=1e-4,权重衰减 = 0.01,余弦退火调度(T_max=300)。
2. 评估指标(量化结果质量)
采用遥感分割领域标准指标,均以百分比形式呈现:
- OA(Overall Accuracy):总体准确率,所有像素的分类正确率。
- IoU(Intersection over Union):交并比,单类预测与真值的重叠率。
- F1 score:精确率与召回率的调和平均,平衡漏检与误检。
- mIoU(mean IoU):所有类 IoU 的平均值,核心评价指标。
- mF1(mean F1):所有类 F1 的平均值,细粒度任务关键指标。
3. 结果生成与验证
(1)消融实验(验证各组件必要性)
通过 “移除组件→对比性能”,证明模型设计的合理性,结果来自论文表 1~4:
| 验证目标 | 实验设置 | 关键结果(mIoU 提升) |
|---|---|---|
| 字典生成器有效性 | 有无字典生成器 | LoveDA +0.46%,Grass +1.26%(细粒度提升更显著) |
| 动态分支与对比损失 | 仅静态损失 vs 加动态损失 | Grass +1.00%,Vaihingen +0.17% |
| 迭代阶段 L 的选择 | L=1/2/3/4 | L=3 最优(LoveDA 55.27%,UAVid 70.90%) |
| 各组件(调制器 / 聚合器) | 单独移除某组件 | 移除调制器:Vaihingen mIoU 下降 2.73% |
(2)SOTA 对比(证明性能领先)
与现有最优方法(如 UNetFormer、AerialFormer、SFA-Net)对比,结果来自论文表 5~8:
- 粗粒度任务:LoveDA mIoU 55.3%(超 SFA-Net +0.4%),UAVid mIoU 70.9%(超 SFA-Net +0.5%),Potsdam mF1 94.7%(超 AerialFormer +0.6%)。
- 细粒度任务:Cloud mF1 89.65%(超 SFA-Net +5.01%),Grass mF1 66.27%(超 KTDA +1.26%),验证动态字典对细粒度区分的优势。
(3)可视化结果(定性验证)
论文图 4~5 展示:
- LoveDA:准确分割穹顶建筑,无类别混淆;
- UAVid:捕获微小人体目标,不受植被干扰;
- Cloud:清晰区分厚云 / 薄云 / 云阴影,边界精准;
- Grass:正确分级草地覆盖度,避免 “低 - 中低” 误判。
六、总结
该论文的核心是 “动态字典 + 交替交叉注意力”:通过显式类 ID 嵌入解决隐式学习的局限性,利用输入自适应的动态字典捕捉类内差异,结合对比损失增强类间分离,最终在 6 个遥感数据集上实现 SOTA 性能。其运行流程清晰(训练双分支优化→推理单分支高效),且各组件的有效性通过消融实验充分验证,可复现性强(代码已开源:https://github.com/XavierJiezou/D2LS)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









