




3.python基础知识点3
函数
1.初识函数
函数到底是个什么?
函数,一大堆代码,给这一堆的代码再起个名字。
# 定义一个函数
def 函数名()://def hanshu():
print(123)
print(123)
print(123)
print(123)
....
# 执行函数(函数内部代码就会执行)
函数名()
def get_info_data():
print("欢迎使用xxx")
v1 = 123
v2 = 567
v3 = v1 + v3
if True:
print(123)
else:
print(999)
print("END")
get_info_data()
了解函数是什么了,那么他的应用场景是什么?
-
面向过程编码:按照业务逻辑从上到下去累代码。
-
监控系统,监控公司的电脑。
print("欢迎使用xx监控系统") if CPU占用率 > 90%: 发送报警邮件-10行 if 硬盘使用率 > 95%: 发送报警邮件-10行 if 内容使用率 > 98%: 发送报警邮件-10行 -
棋牌游戏扎金花
# 1.生成一副扑克牌6行代码 # 2.洗牌3行代码 # 3.给5个玩家发三张牌 15行代码 # 4.玩家手中牌的大小比较(80行) - 是否是豹子(大小) - 是否是同花顺(大小) - 是否是同花(大小) - 是否是对子(大小) - 是否是单点(大小)
-
-
函数式编程:用函数来写代码。
-
监控系统,监控公司的电脑【增强代码的重用性】【应用场景1】
def 发送邮件(): 发送报警邮件-10行 print("欢迎使用xx监控系统") if CPU占用率 > 90%: 发送邮件() if 硬盘使用率 > 95%: 发送邮件() if 内容使用率 > 98%: 发送邮件() -
棋牌游戏扎金花,【增强代码的可读性】
def 发牌(): ... .. def 是否是豹子(): .. .. def 是否是同花顺(): .. .. def 是否是同花(): .. .. def 是否是对子(): .. .. def 是否是单点(): .. .. # 1.生成一副扑克牌6行代码 # 2.洗牌3行代码 # 3.给5个玩家发三张牌 15行代码 发牌() # 4.玩家手中牌的大小比较(80行) 是否是豹子() 是否是同花顺() ...
-
函数应用场景:
- 反复用到重复代码时,可以选择用函数编程。【增强代码的重用性】
- 业务逻辑代码太长,可以选择用户函数将代码拆分。【增强代码的可读性】
2.Python代码发邮件
-
注册邮箱:网易126、163邮箱。
-
配置
大家需要去获取授权码,通过代码发邮件,再发送邮件时不要告诉我的账号和密码。 所以,Python代码后续需要使用的: - 账号 - 授权码(不是网易邮箱的密码) 保存好自己的授权码。 SMTP服务器: smtp.163.com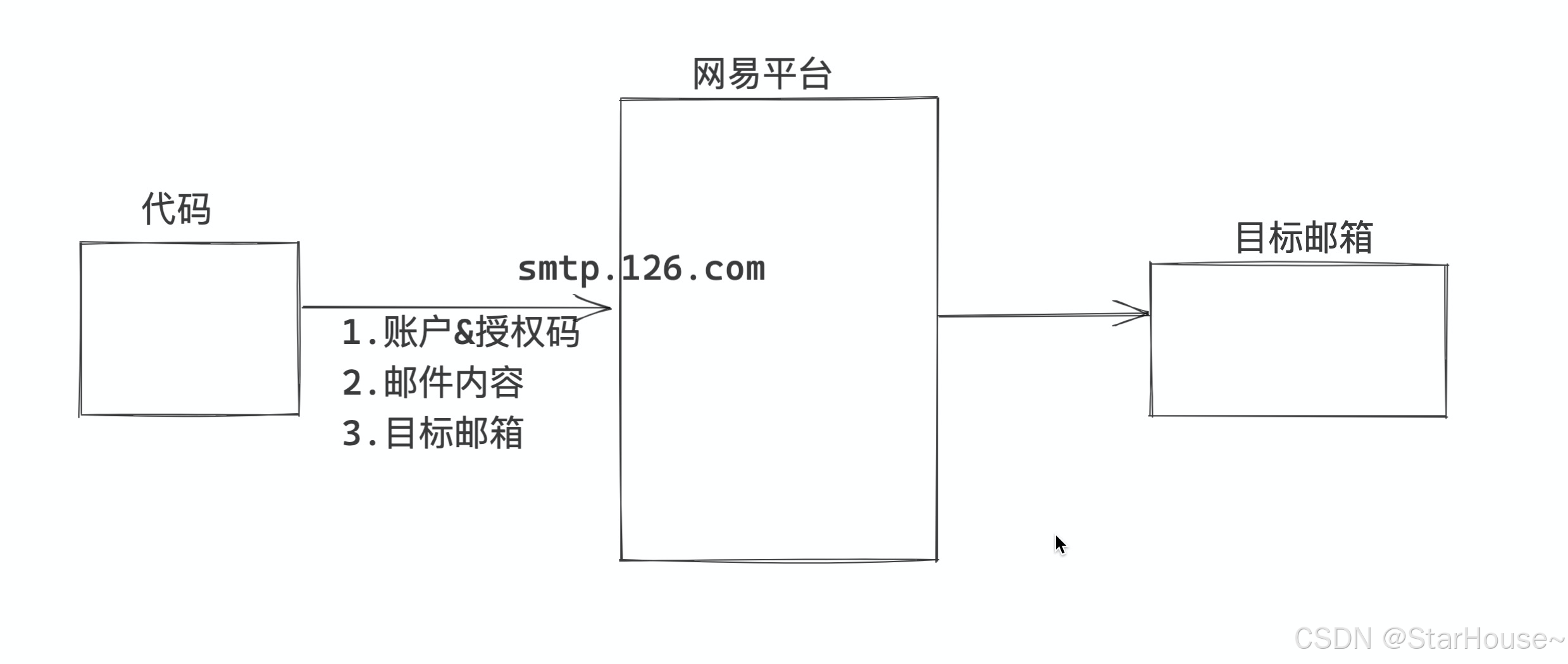
-
代码发邮件
# 1.将Python内置的模块(功能导入)//该文件名不能叫smtplib或者email import smtplib from email.mime.text import MIMEText from email.utils import formataddr # 2.构建邮件内容 msg = MIMEText("领导早上好,领导今天辛苦了。", "html", "utf-8") # 内容,"html", "utf-8"为固定形式 msg["From"] = formataddr(["xqs", "youxiang@126.com"]) # 自己名字/自己邮箱 msg['to'] = "888888888@qq.com" # 目标邮箱 msg['Subject'] = "360一天" # 主题 # 3.发送邮件 server = smtplib.SMTP_SSL("smtp.126.com") server.login("youxiang@126.com", "WOAIJWEKAMDJXIF") # 账户/授权码 server.sendmail("youxiang@126.com", "888888888@qq.com", msg.as_string()) # 自己邮箱/目标邮箱/内容 server.quit()
3.函数的参数
3.1 基本使用
def 函数名(形式参数1,形式参数2,形式参数3): # 简称形参
函数内部代码,将形式参数当做是变量来使用。
# 执行函数时,传入的值:实际参数(实参)
函数名(1,2,3)
def my_func(a1,a2,a3):
result = a1 + a2 - a3
print(result)
# 执行函数
my_func(1,4,1)
# 执行函数
my_func(11,14,99)
在执行函数时,传入参数时候一般有两种模式:
-
位置传参
def my_func(a1,a2,a3): result = a1 + a2 - a3 print(result) # 执行函数 my_func(1,4,1)//my_func(1,2,3) # 执行函数 my_func(11,14,99) -
关键字传参
def my_func(a1,a2,a3)://my_func(a1 = 1,a2 = 2,a3 = 3) result = a1 + a2 - a3 print(result) my_func(a1=11,a2=99,a3=10) my_func(a2=99,a3=10,a1=10) -
混合使用
def my_func(a1,a2,a3): result = a1 + a2 - a3 print(result) # 位置传参在前面,关键字传参是在后面!!!只能位置传参在前,关键字传参在后 my_func(123,99,a3=10) my_func(123,a2=99,a3=10)
注意:
- 函数要求传入几个参数,你就要传入几个参数。
- 参数可以是任意类型:None、bool、int、str、list、dict…
3.2 默认参数
def func(a1,a2,a3):
pass
func(1,2,3)
在定义函数时,也可以为某个参数设置默认值。
def func(a1,a2=1,a3=123):
pass
# 位置传参
func(9)//没有传参的时候用默认值
func(9,10)
func(9,10,100)
# 关键字传参
func(a1=9)
func(a1=100,a2=9)
func(a1=100,a2=9,a3=123)
# 注意注意:函数定时设置的默认参数,只能放在最后。
3.3 动态参数
def func(a1,a2,a3=123):
pass
func(1,2)
# 参数传入的都是有限的个数。
-
def func(*a1)://*a1为可以传任意个参数 # 用户传来的参数统一会被打包成元组 # a1 = (1,) # a1 = (11,22,33) # a1 = (11,22,33,"xxxx",True) # a1 = (11,22,33,"xxxx",True, [11,22,33],999) # a1 = ( [11,22,33,44,55] , ) # a1 = ( (11,22,33), ) print(a1) # 可以通过位置参数的形式传入n个参数。 func(1) func(11,22,33) func(11,22,33,"xxxx",True) func(11,22,33,"xxxx",True, [11,22,33],999) func( [11,22,33,44,55] ) func( (11,22,33) ) func() -
**
def func(**dt):**dt为可以传任意个参数 # 自动将数据打包整字典 # dt = {"a1":1,"b1":88,"cc":99} print(dt) # 必须用关键字的形式传参 func(a1=1,b1=88,cc=99)//里面代指参数也传进去 func(a1=1,b1=88,cc=99) func() -
,*
def func(*x1,**dt): # x1 = (11,22,3) dt = {"xx":123,"uu":999, "b12":"root"} # x1 = () dt = {} pass func(11,22,3, xx=123,uu=999,b12="root") func() # 注意实现 # 1.定义函数顺序 //只能一个*在前, *x1,**dt # 2.执行函数传参的时,位置传参在前,关键字传参在后。 # 3.当不传参数时,# x1 = () dt = {}空元组,空字典 -
混合之前的使用
def func(a1,a2,a3,*x1,**dt): pass func(11,22,33,44,55,66,77,a1=123)//a1,a2,a3为11,22,33, 44,55,66,77,*x1,
重点:
-
,* 支持传入多个参数,自动会将参数打包成 元组 、字典。
-
【潜规则】在定义动态参数时,*args、**kwargs
def func(*args,**kwargs)://*args **kwargs pass
4.函数的返回值
- print,输出,可以在任何的地方使用。
- 函数的返回值
在以后的开发过程中,定义一个函数,帮助你实现某个功能,希望函数给你产出一个结果。
def func(a1,a2):
res = a1 + a2
return res
# 1.执行func函数
# 2.将函数执行的返回值 赋值给data
data = func(100,200)
关于返回值:
-
返回值可以是任意类型
def f1(): return 123 v1 = f1()def f1(): return [11,22,33,44] v1 = f1()def f1(): return
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









