




 本文详细讲解计算机二级Python考试的真题,涵盖基本编程、简单应用和综合应用题。涉及random库的使用、字符串处理、turtle库绘图、字典统计方法以及文件操作。通过实例解析,帮助考生掌握考试重点。
本文详细讲解计算机二级Python考试的真题,涵盖基本编程、简单应用和综合应用题。涉及random库的使用、字符串处理、turtle库绘图、字典统计方法以及文件操作。通过实例解析,帮助考生掌握考试重点。
基本编程题【15 分】
- 考生文件夹下存在一个文件 PY101.py,请写代码替换横线,不修改其他代码,实现以下功能:【5 分】
题目:
import __________ brandlist = ["诺基亚", "苹果", "诺基亚", "OPPO", "小米"] random.seed(0) __________ print(name)随机选择一个手机品牌屏幕输出。
解析:
常考考点 random 库,首先第一个横线上导入 random库。根据题目要求,选用 random.sample(list, k) 函数,它的作用是返回一个长度为 k 新列表 list。
答案:
import random
brandlist = ["诺基亚", "苹果", "诺基亚", "OPPO", "小米"]
random.seed(0)
name = random.sample(brandlist, 1)
print(name)
- 考试文件夹下存在一个文件 PY102.py,请写代码替换横线。实现以下功能:【5 分】
题目:
import jieba s = input("请输入一个字符串") n = ___________ m = ___________ print("中文字符数为{},中文词语数为{}。".format(n, m))键盘输入一段文本,保存在一个字符串变量 s 中,分别用 Python 内置函数及 jieba 库中已有函数计算字符串 s 的中文字符个数及中文词语个数。
注意:中文字符包含中文标点符号。
例如,键盘输入:俄罗斯举办世界杯 ,屏幕输出:中文字符数为 8,中文词语数为 3。
解析:
本题考察的是 len 函数、jieba 库中的重要函数 lcut(),它的功能是自动划分字符串为列表,列表元素为组成字符串的词语。根据题目要求,首先用 len 函数统计字符串长度,然后用 len 函数统计列表长度——即词语数。
答案:
import jieba
s = input("请输入一个字符串")
n = len(s)
m = len(jieba.lcut(s))
print("中文字符数为{},中文词语数为{}。".format(n, m))
- 考试文件夹下存在一个文件 PY103.py,请写代码替换横线。实现以下功能:【5 分】
题目:
n = eval(input("请输入数量:")) ··· print("总额为:", cost)某商店出售某品牌运动鞋,每双定价 160,1 双不打折,2 双(含)到 4 双(含)打九折,5 双(含)到 9 双(含)打八折,10 双(含)以上打七折,键盘输入购买数量,屏幕输出总额(保留整数)。
示例格式如下:输入:1 输出:总额为 160
解析:
本题考察的是多分支流与数值类型转换,根据题目要求,使用 if-elif-else 多分支流,最后考察了 int 函数将浮点数数值类型转换为整数数值类型。
答案:
n = eval(input("请输入数量:"))
if n>=10:
cost = n*160*0.7
elif 5<=n<=9:
cost = n*160*0.8
elif 2<=n<=4:
cost = n*160*0.9
else:
cost = n*160
cost = int(cost)
print("总额为:", cost) #保留整数
简单应用题【25 分】
- 考生文件夹下存在一个文件 PY201.py,请写代码替换横线,不修改其他代码,实现以下功能:【10 分】
题目:
import turtle turtle.pensize(2) d = _________ for i in range (4): turtle.seth(d) d += __________ turtle.fd(__________)
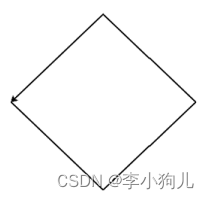
使用 turtle 库的 turtle.fd()函数和 turtle.seth()函数绘制一个边长为 200 的正菱形,菱形 4 个内角均为 90 度。效果如下图所示,箭头与下图严格一致。
解析:
本题考察 turtle 库中的两个函数 fd()和 seth(),turtle.fd()是前进函数,turtle.seth()函数可以改变海龟的行进方向(角度按逆时针),其中参数 angle 为绝对度数。第一道横线上填写45 度或者-45 度,又因为它要求箭头一致,所以选择-45 度。第二道横线上肯定填写 90 度。第三道横线肯定填写 200 像素。
答案:
import turtle
turtle.pensize(2)
d = -45
for i in range (4):
turtle.seth(d)
d += 90
turtle.fd(200)
- 考生文件夹下存在一个文件 PY202.py,请在该文件中作答,实现以下功能:【15 分】
题目:
names = input("请输入各个同学行业名称,行业名称之间用空格间隙(回车结束输入)") ··· d ={} ··· ls = list(d.items()) ls.sort(key = lambda x:x[1], reverse = True) for k in ls: print("{}:{}".format())键盘输入某班各个同学就业的行业名称,行业名称之间用空格间隔(回车结束输入)。完善 Python 代码,统计各行业就业的学生数量,按数量从高到低方式输出。例如:输入:交通 金融 计算机 交通 计算机 计算机输出参考格式如下,其中冒号为英文冒号:
计算机: 3
交通: 2
金融: 1
思路:
这个题目考察的是经典的字典统计方法,给出的框架中第 5行已经有了 input 输入,第 7 行有了空字典 d,并将这个 d 字典经过处理后,在第 9-12 行做了列表转换并且按照出现次数进行反向排序(从大到小)并且 for循环输出。其中需要需要填写的有两个部分,第一部分是对于输入 names 的处理,第二部分是行业统计,即经典的字典统计方法。
解析:
第一部分将输入的 names 转换为列表,使用的是 split()函数,” ”的含义是以空格为分隔符;定义空字典 d 之后,即使用字典统计方法:用一个 for 循环对 ls 列表中的每个元素进行处理,相应的元素会在字典 d 中更新:如果字典中存在 name,则返回关键字对应的值同时+1;如果字典 d 中不存在 name,则返回 0 同时+1——这也是 d[name] = d.get(name, 0) + 1 语句的含义。循环列表中每个元素,直到循环结束。
答案:
names = input("请输入各个同学行业名称,行业名称之间用空格间隙(回车结束输入)")
ls = names.split(" ")
d ={}
for name in ls:
d[name] = d.get(name, 0) + 1
ls = list(d.items())
ls.sort(key = lambda x:x[1], reverse = True) # 按照数量排序
for k in ls:
print("{}:{}".format())
综合应用题【20 分】
- 考生文件夹下存在两个 Python 源文件,分别对应两个问题,请按照文件内说明修改代码,实现以下功能:
下面所示为一套由公司职员随身佩戴的位置传感器采集的数据,文件名称为“sensor.txt”,其内容示例如下
2016/5/31 0:05, vawelon001,1,1
2016/5/31 0:20, earpa001,1,1
2016/5/31 2:26, earpa001,1,6
… (略)
第一列是传感器获取数据的时间,第二列是传感器的编号,第三列是传感器所在的楼层,第四列是传感器所在的位置区域编号。
问题 1【10 分】:
··· for line in ________: ··· fo.write('{},{},{},{}\n'.format(_________)) ···在 PY301_1.py 文件中修改代码,读入 sensor.txt 文件中的数据,提取出传感器编号为 earpa001 的所有数据,将结果输出保存到“earpa001.txt”文件。
输出文件格式要求:原数据文件中的每行记录写入新文件中,行尾无空格,无空行。参考格式如下:
2016/5/31 7:11, earpa001,2,4
2016/5/31 8:02, earpa001,3,4
2016/5/31 9:22, earpa001,3,4
…(略)
思路:
这个题目的难度一般,考察定位提取,涉及的知识有文件操作、for 循环、if 单分支流、字典索引、format 字符串格式方法。给我们的提示框架是一个 for循环,已经给出是在循环中完成字符串的写入,因此循环前、循环中、循环后皆有代码需要补充,我们为了统一,也称作前处理、中处理、后处理三部分,解套思路清晰。
解析:
前处理:首先在第 18 行使用 open()函数以读入模式”r”并指定encoding=”utf-8”打开 txt 文件,然后在第 19 行使用 open()函数以写入模式”w”新建并打开 txt 文件,最后在第 20 行根据题目要求需要按行处理,所以我们使用 readlines()方法读入文件内容,将整个文件作为一个列表 lines,文件中的每一行字符串作为列表中的元素。
中处理:for 循环对列表 lines 中的每个字符串元素进行处理,首先使用 strip()函数去掉字符串元素中末尾的换行符\n,再使用 spilt()函数以英文逗号”,”为分隔符对字符串元素进行分割并存入列表 ls,最后以单分支流方式定位出“earpa001”是否在列表 ls 的字符串元素中,如果存在,则将此列表的字符串元素按要求提取写入文件 fo。值得注意的是判断“earpa001”的时候,考官可能故意在 earpa001前面加了一个空格,判断我们应用灵活性,我们使用语句 if “earpa001” in ls[1]:,其中 in 和 ls[1]值得大家仔细揣摩。
后处理:有必要关闭打开的文件以节约内存,考试得分点。
答案:
############################前处理##############################
# 打开txt文件,fi代表file in, fo代表file out
fi = open("sensor.txt", "r", encoding='utf-8') # 打开这个网络文本,必须指定encoding
fo = open("earpa001.txt", "w")
lines = fi.readlines() # 读入txt内容,lines=行内容
############################中处理##############################
# 循环每行内容,从中匹配题目所指定的“ earpa001”字符(注意前面有个空格),并将其写入fo文件
for line in lines:
ls = line.strip("\n").split(",") # 用strip("\n")除去行尾的换行符,同时用split(",")分隔
if "earpa001" in ls[1]:
fo.write('{},{},{},{}\n'.format(ls[0], ls[1], ls[2], ls[3])) #格式化字符串
#############################后处理############################
# 关闭打开的文件,释放内存
fi.close()
fo.close()
问题 2【10 分】:
··· d = {} ··· ls = list(d.items()) ls.sort(key=lambda x:x[1], reverse=True) ··· fo.write('{},{}\n'.format(__________)) ···在 PY301_2.py 文件中修改代码,读入“earpa001.txt”文件中的数据,统计 earpa001 对应的职员在各楼层和区域出现的次数,保存到“earpa001_count.txt”文件,每条记录一行,位置信息和出现的次数之间用英文半角逗号隔开,行尾无空格,无空行。参考格式如下
1-1,5
1-4,3
(略)
含义如下:第 1 行“1-1,5”中 1-1 表示 1 楼 1 号区域,5 表示出现 5 次;第 2行“1-4,3”中 1-4 表示 1 楼 4 号区域,3 表示出现 3 次;
思路:
这个题目看着就头大了,似乎很复杂。不慌,我们还是使用三部曲方法解套,第 6 行之前的前处理、第 7 行到第 9 行中处理、第 10 行到最后的后处理。就算最后得不出正确结果,我们也可以对应得分。
解析:
前处理:与问题(1)相同。
中处理:这是本题的难点,但是万变不离其宗,归根结底还是个字典字符字符统计的问题。唯一的区别是此时的字符不是原来存在的,需要我们构造出来。类似于问题(1)首先使用 strip()函数去掉字符串元素中末尾的换行符\n,再使用spilt()函数以英文逗号”,”为分隔符对字符串元素进行分割并存入列表 li,然后我们使用字符串拼接的方式构造题目要求的字符形式——见第 32 行,最后第 33 行字符次数统计。
后处理:程序最后两行的 for 循环帮助我们写入文件。最后别忘了得分点关闭文件。
答案:
###############前处理###########################
fi = open("earpa001.txt","r")
fo = open("earpa001_count.txt", "w")
lines = fi.readlines()
d = {}
###############中处理###########################
for line in lines:
li = line.strip("\n").split(",")
s = li[2] + "-" + li[3]
d[s] = d.get(s, 0) + 1
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True)
###############后处理###########################
for i in range(len(ls)):
fo.write('{},{}\n'.format(ls[i][0], ls[i][1]))
fi.close()
fo.close()

















 727
727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









