




 本文介绍了三种使用Python查找电脑中重复文件的方法:通过文件哈希值、文件名出现次数以及字符串相似度算法。提供了详细代码实现,帮助清理和管理电脑存储空间。
本文介绍了三种使用Python查找电脑中重复文件的方法:通过文件哈希值、文件名出现次数以及字符串相似度算法。提供了详细代码实现,帮助清理和管理电脑存储空间。

一、案例
当电脑中重复文件过多,各种聊天软件中获取的各种重复文件,又都自动下载在电脑中,不断占用电脑内存,同时又不容易通过每个关键字来搜索重复文件,删除重复文件以减小内存的情况。
可以通过获取文件的哈希值进行对比查找重复文件,并展示哈希值以及重复文件路径,只需要按照搜索的目录来进行检索,通过计算的哈希值,可快速查找到文件名重复度很高的文件,并将其文件路径进行归类展示,便于后续的删除等操作,具体代码如下:
import os
import hashlib
from collections import defaultdict
from typing import List, Dict, Any, Tuple
def get_file_hash(file_path: str, block_size: int = 65536) -> str:
"""获取文件的哈希值"""
hasher = hashlib.sha256()
with open(file_path, 'rb') as file:
while True:
data = file.read(block_size)
if not data:
break
hasher.update(data)
return hasher.hexdigest()
def find_duplicate_files(starting_directory: str) -> List[Tuple[str, List[str]]]:
"""查找重复文件"""
file_hashes: Dict[str, List[str]] = defaultdict(list)
for root, _, files in os.walk(starting_directory):
for file_name in files:
file_path = os.path.join(root, file_name)
try:
file_hash = get_file_hash(file_path)
file_hashes[file_hash].append(file_path)
except Exception as e:
print(f"Error hashing {file_path}: {e}")
return [(file_hash, file_paths) for file_hash, file_paths in file_hashes.items() if len(file_paths) > 1]
def display_duplicate_files(duplicate_files: List[Tuple[str, List[str]]]):
"""显示重复文件"""
if not duplicate_files:
print("未找到重复文件。")
return
print("以下文件可能是重复的:")
for file_hash, file_paths in duplicate_files:
print(f"哈希值:{file_hash}")
print("文件路径:")
for file_path in file_paths:
print(f" - {file_path}")
print()
if __name__ == "__main__":
starting_directory = input("请输入要搜索的起始目录:")
if os.path.exists(starting_directory):
duplicate_files = find_duplicate_files(starting_directory)
display_duplicate_files(duplicate_files)
else:
print("指定的起始目录不存在。")
二、案例
思路和案例一的思路雷同,不同的是:并未通过计算文件的哈希值来查找重复文件,而是通过遍历计算机上的所有文件,并记录它们的文件名,统计文件名的出现次数,找到重复度很高的文件名,具体代码如下:
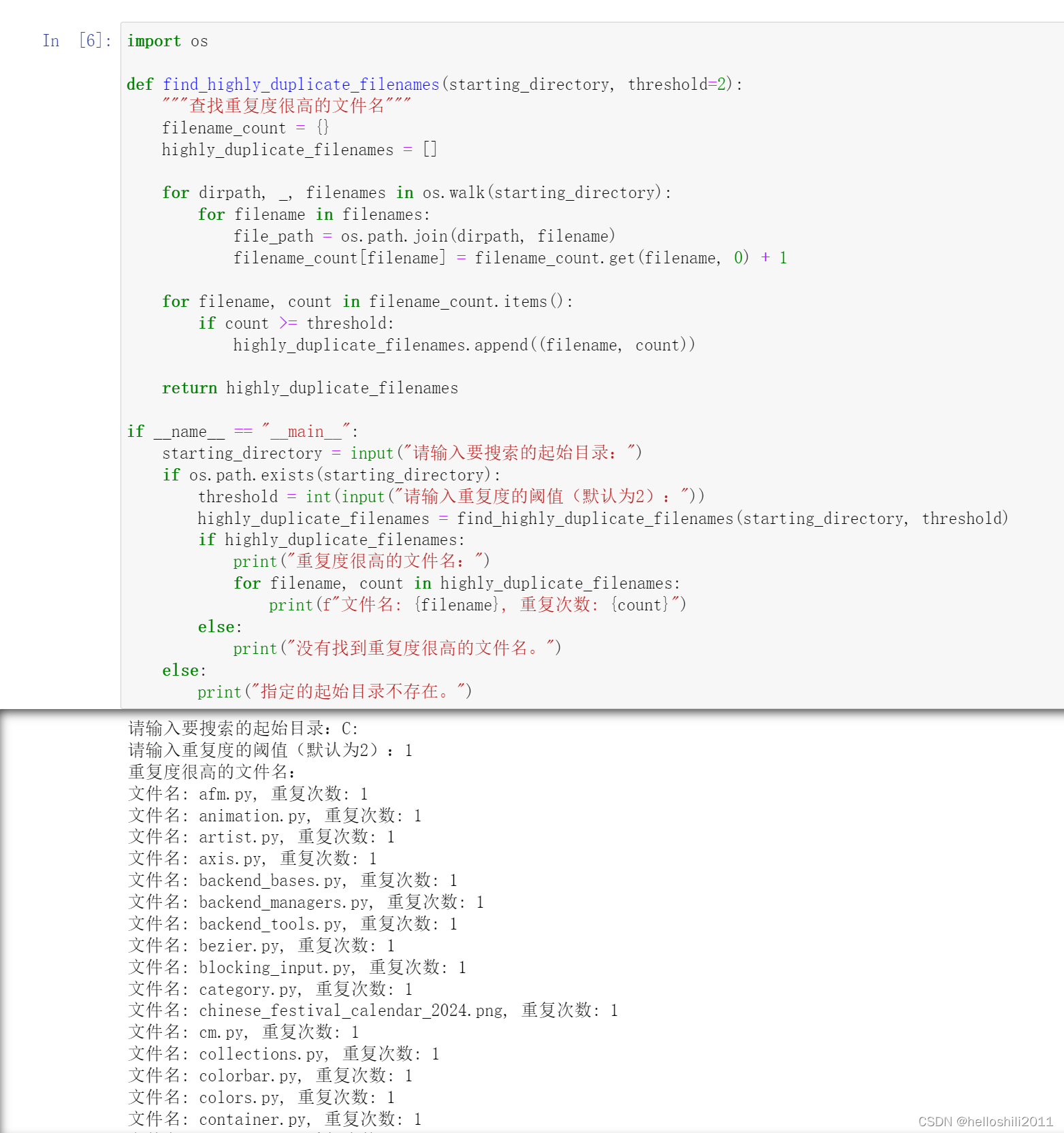
import os
def find_highly_duplicate_filenames(starting_directory, threshold=2):
"""查找重复度很高的文件名"""
filename_count = {}
highly_duplicate_filenames = []
for dirpath, _, filenames in os.walk(starting_directory):
for filename in filenames:
file_path = os.path.join(dirpath, filename)
filename_count[filename] = filename_count.get(filename, 0) + 1
for filename, count in filename_count.items():
if count >= threshold:
highly_duplicate_filenames.append((filename, count))
return highly_duplicate_filenames
if __name__ == "__main__":
starting_directory = input("请输入要搜索的起始目录:")
if os.path.exists(starting_directory):
threshold = int(input("请输入重复度的阈值(默认为2):"))
highly_duplicate_filenames = find_highly_duplicate_filenames(starting_directory, threshold)
if highly_duplicate_filenames:
print("重复度很高的文件名:")
for filename, count in highly_duplicate_filenames:
print(f"文件名: {filename}, 重复次数: {count}")
else:
print("没有找到重复度很高的文件名。")
else:
print("指定的起始目录不存在。")
三、案例
还可以通过使用字符串相似性算法(如Levenshtein距离)来比较它们的相似程度。这样可以找到即使文件名不完全相同但相似的文件。这个方法也能检测到文件名基本相同但末尾数字不同的情况,具体代码如下:
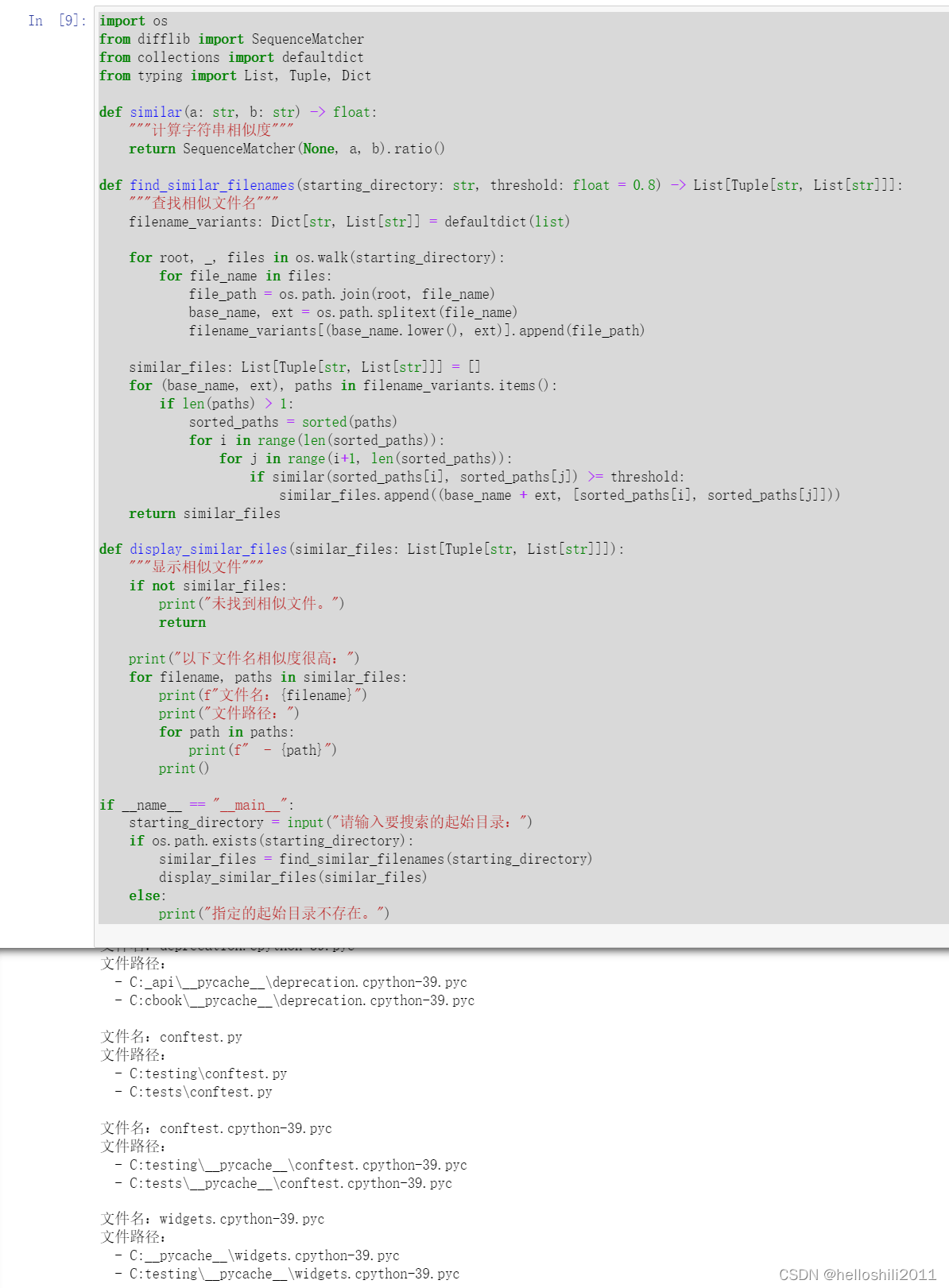
import os
from difflib import SequenceMatcher
from collections import defaultdict
from typing import List, Tuple, Dict
def similar(a: str, b: str) -> float:
"""计算字符串相似度"""
return SequenceMatcher(None, a, b).ratio()
def find_similar_filenames(starting_directory: str, threshold: float = 0.8) -> List[Tuple[str, List[str]]]:
"""查找相似文件名"""
filename_variants: Dict[str, List[str]] = defaultdict(list)
for root, _, files in os.walk(starting_directory):
for file_name in files:
file_path = os.path.join(root, file_name)
base_name, ext = os.path.splitext(file_name)
filename_variants[(base_name.lower(), ext)].append(file_path)
similar_files: List[Tuple[str, List[str]]] = []
for (base_name, ext), paths in filename_variants.items():
if len(paths) > 1:
sorted_paths = sorted(paths)
for i in range(len(sorted_paths)):
for j in range(i+1, len(sorted_paths)):
if similar(sorted_paths[i], sorted_paths[j]) >= threshold:
similar_files.append((base_name + ext, [sorted_paths[i], sorted_paths[j]]))
return similar_files
def display_similar_files(similar_files: List[Tuple[str, List[str]]]):
"""显示相似文件"""
if not similar_files:
print("未找到相似文件。")
return
print("以下文件名相似度很高:")
for filename, paths in similar_files:
print(f"文件名:{filename}")
print("文件路径:")
for path in paths:
print(f" - {path}")
print()
if __name__ == "__main__":
starting_directory = input("请输入要搜索的起始目录:")
if os.path.exists(starting_directory):
similar_files = find_similar_filenames(starting_directory)
display_similar_files(similar_files)
else:
print("指定的起始目录不存在。")
若有问题可私信我,欢迎关注,感谢小主!



















 1553
1553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











