



一、目的
1.掌握视图&索引定义;
2.理解视图&索引作用及原理
二、实验内容与设计思想(设计思路、主要数据结构、主要代码结构、主要代码段分析)
(一)实验内容
1.定义视图;
2.定义索引;
(二)设计性实验
1. 创建视图V_A包括学号,姓名,性别,课程号,课程名、成绩;
USE STU039
GO
CREATE VIEW V_A039 AS
SELECT S.SNO,SNAME,SSEX,CNAME,C.CNO,DEGREE
FROM student039 s join score039 sc on sc.sno=s.sno join course039 c on c.cno=sc.cno
GO
SELECT * FROM V_A039
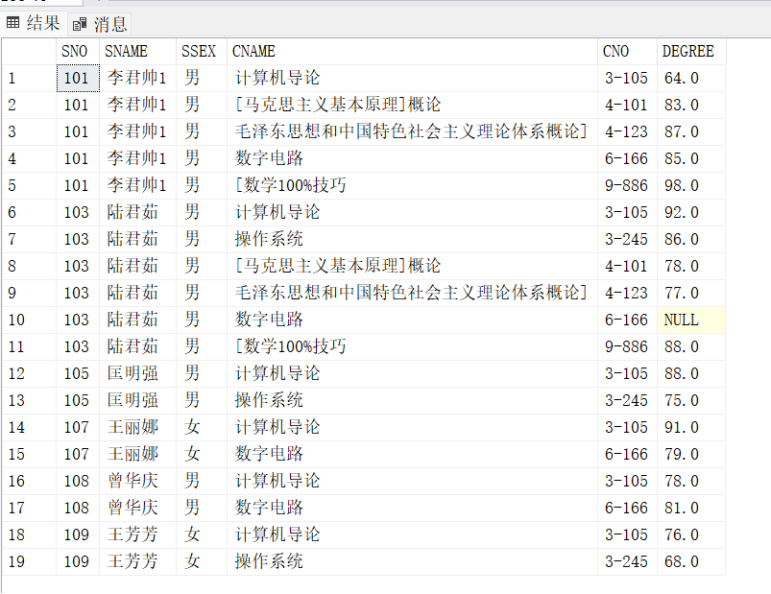
---一个语句把学号103 课程号3-105 的姓名改为陆君茹1,性别为女 ,然后查看学生表的信息变化
USE STU039
UPDATE V_A039 SET SNAME='陆君茹1',SSEX='女'
WHERE SNO='103'AND CNO='3-105'
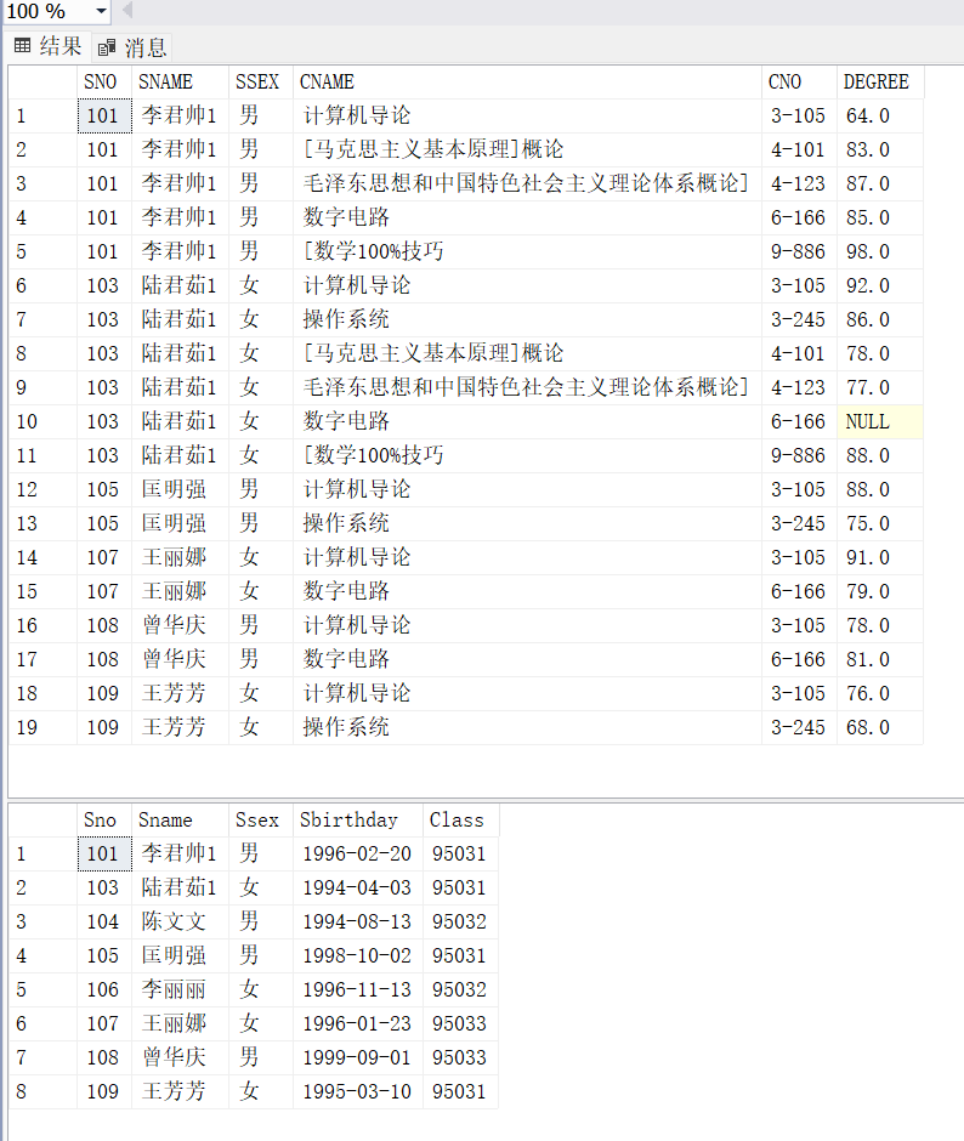
--再把上述数据改为原值
UPDATE student039
SET sname = '陆君茹',ssex = '男'
WHERE sno = '103'
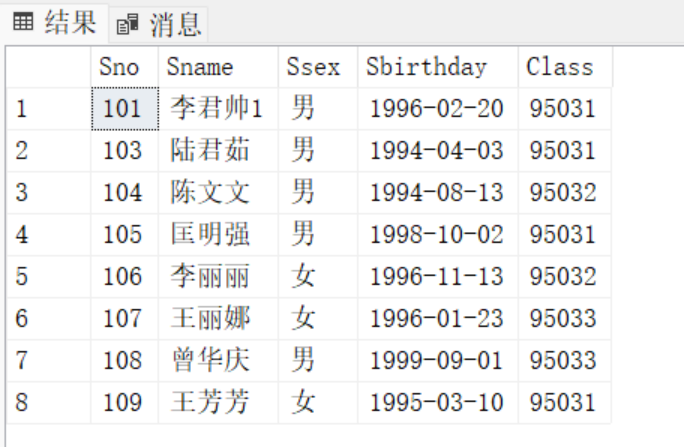
--一个语句把学号101 课程号4-101 的姓名改为李君帅1,课程名为[马克思主义基本原理]概论]?如何才能完成修改
--再把上述数据改为原值
USE STU039
UPDATE student039
SET sname = '李君帅'
WHERE sno = '101';
SELECT * FROM student039
-- 添加一行数据 --??
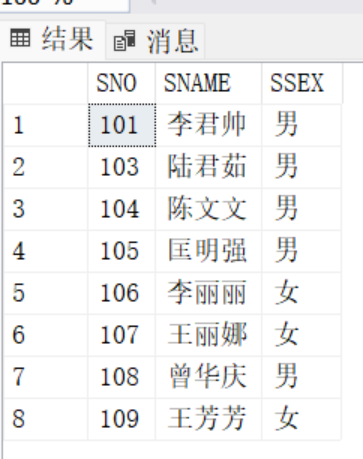
创建视图V_A1包括学号,姓名,性别
USE STU039
GO
CREATE VIEW V_A1039 AS
SELECT SNO,SNAME,SSEX FROM student039
GO
SELECT * FROM V_A1039
-- 添加一行数据 --??
USE STU039
GO
-- 添加数据到student039表
INSERT INTO V_A1039 (sno, sname, ssex)
VALUES ('102', '蔡潍鑫', '男');
GO
SELECT * FROM V_A1039
2. 创建视图V_B, 优秀学生(所有成绩不低于80),包括姓名,课程名、成绩 (WITH ENCRYPTION)
-- 检查WITH ENCRYPTION 效果
USE STU039
GO
CREATE VIEW V_B039 WITH ENCRYPTION AS
SELECT SNAME,CNAME,DEGREE
FROM student039 S JOIN Score039 SC ON S.SNO=SC.SNO JOIN Course039 C ON SC.CNO=C.CNO
WHERE S.SNO NOT IN (SELECT SNO FROM Score039 WHERE DEGREE<80)
GO
SELECT * FROM V_B039
EXEC sp_helptext 'V_B039'
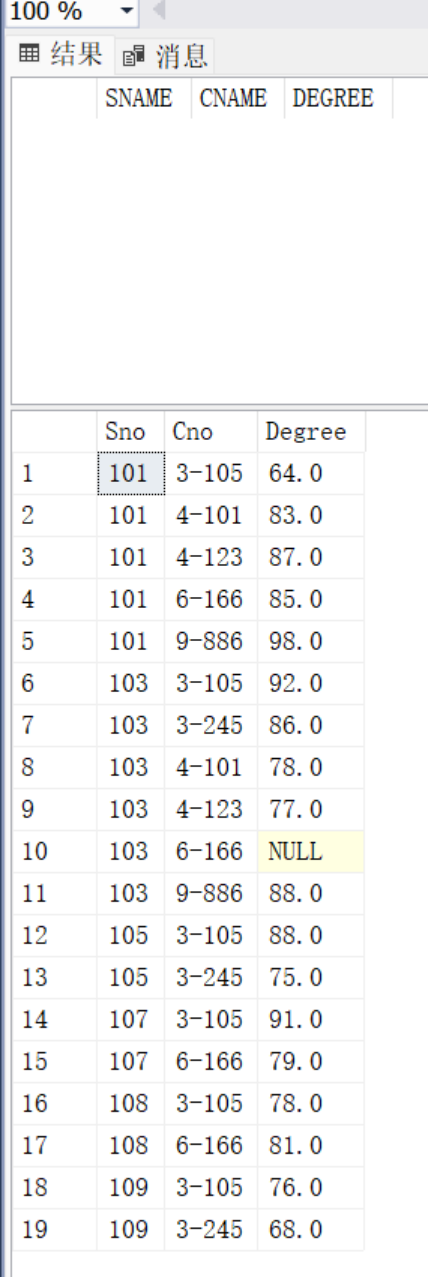
--把王丽娜 的计算机导论 成绩(91)改为80,并查看成绩表和V_B中的数据
USE STU039
UPDATE V_B039
SET DEGREE=80
WHERE SNAME='王丽娜' AND CNAME='计算机导论'
SELECT * FROM V_B039
SELECT * FROM Score039
----再把上述数据改为原值
USE STU039
UPDATE V_B039
SET DEGREE=91
WHERE SNAME='王丽娜' AND CNAME='计算机导论'
SELECT * FROM V_B039
SELECT * FROM Score039
3.创建视图V_C, 优秀学生(所有成绩不低于80),包括姓名,课程名、成绩 (WITH check option)
USE STU039
GO
CREATE VIEW V_C039 WITH CHECK OPTION AS
SELECT S.SNAME,C.CNAME,SC.DEGREE
FROM student039 S JOIN Score039 SC ON S.SNO=SC.SNO JOIN Course039 C ON SC.CNO=C.CNO
WHERE S.SNO NOT IN (SELECT SNO FROM Score039 WHERE DEGREE<80)
GO
SELECT * FROM V_C039

--检查WITH check option效果
--把王丽娜 的计算机导论 成绩(91)改为85,并查看成绩表和V_C中的数据
----再把王丽娜 的计算机导论 成绩改为78,并查看成绩表和V_C中的数据 ???
4.对教师表按姓名创建唯一性索引;
USE STU039
CREATE UNIQUE INDEX TNAME_IND ON TEACHER039(TNAME)

5.对课程表按课程名创建聚集索引;???
![]()
6.创建索引视图V_D,包括学号,姓名,性别,课程号,课程名、成绩,并按姓名创建索引
USE STU039
GO
-- 创建视图V_D039
CREATE VIEW V_D039 WITH SCHEMABINDING AS
SELECT S.SNO, S.SNAME, S.SSEX, C.CNAME, C.CNO, SC.DEGREE
FROM dbo.student039 s
JOIN dbo.score039 sc ON sc.sno = s.sno
JOIN dbo.course039 c ON c.cno = sc.cno;
GO
-- 创建唯一聚集索引
CREATE UNIQUE CLUSTERED INDEX idx_vd_sno_cno ON V_D039(sno, cno);
GO
-- 按姓名创建非聚集索引
CREATE NONCLUSTERED INDEX idx_vd_sname ON V_D039(sname);
7. 删除上述建的全部索引
USE STU039
DROP INDEX TNAME_IND ON TEACHER039
DROP INDEX IF EXISTS cname_IND ON course039;
DROP INDEX IF EXISTS idx_vd_sno_cno ON V_D039;
DROP INDEX IF EXISTS idx_vd_sname ON V_D039;
(三)思考题
1.视图的作用是什么?
简化查询:将复杂的查询逻辑封装在视图中,用户只需对视图进行查询,无需关注底层多表连接、筛选等复杂操作。比如在涉及多张表关联查询学生成绩信息时,创建视图后,后续查询可直接从视图获取结果,降低使用难度和代码复杂度。
增强安全性:通过视图可限制用户对数据的访问范围。仅将视图暴露给用户,控制用户能看到的列和行,隐藏敏感数据。如员工信息表中,只允许普通员工查看部分基本信息视图,不能直接访问包含薪资等敏感信息的原始表。
逻辑数据独立性:当基础表结构发生变化(如新增列、修改列名 )时,若查询基于视图,只要视图定义适当调整,上层应用程序的查询代码可不改变,使应用程序与基础表结构解耦,增强数据独立性。
2.什么是索引视图?如何创建
含义:索引视图是一种特殊视图,在 SQL Server 中,对视图创建唯一聚集索引后,视图结果集会被物理存储到数据库中 ,类似带有聚集索引的表存储数据方式。它可预先计算并存储结果,后续查询能快速获取数据,提升查询性能,尤其适用于复杂连接、聚合查询场景。
创建方法:
创建视图:使用CREATE VIEW语句并添加WITH SCHEMABINDING选项,将视图绑定到基础表架构,防止基础表结构变化影响视图。视图创建好后,用CREATE UNIQUE CLUSTERED INDEX语句为视图创建唯一聚集索引,确定视图数据物理存储顺序。如:
创建时需注意视图定义满足相关限制,如不能有外部链接、不能包含特定聚合函数等
3.举例说明什么是聚集索引,非聚集索引
聚集索引:好比字典按拼音顺序排列汉字,数据行物理存储顺序与索引顺序一致。以员工表为例,若在员工编号列创建聚集索引,员工数据在磁盘上会按员工编号顺序存储。当查询特定编号范围员工信息时,数据库能快速定位数据页,高效获取数据。因为数据按索引顺序存放,一个表只能有一个聚集索引。
非聚集索引:类似字典的部首检字表,部首顺序与字典正文汉字物理顺序不同。在员工表中,若在员工姓名列创建非聚集索引,索引存储姓名及对应数据行的指针(行定位器 )。查询员工姓名时,先在非聚集索引找到姓名对应指针,再依据指针到数据页获取完整员工信息。非聚集索引可创建多个。
4.简述使用聚集索引,非聚集索引检索数据的过程?
聚集索引检索过程:
数据库定位聚集索引的根节点,根节点存储索引的高层信息。
从根节点开始,通过比较索引键值,沿索引树的分支节点向下查找,直至找到包含目标数据的叶子节点。
叶子节点直接存储数据行,找到叶子节点即获取到目标数据。
非聚集索引检索过程:
先定位非聚集索引的根节点,开始搜索。
沿索引树分支节点查找,根据索引键值比较,找到包含目标键值的叶子节点。
非聚集索引叶子节点存储的是键值及指向数据行的指针(若表有聚集索引,指针是聚集索引键 )。
拿到指针后,利用指针到聚集索引(若存在 )或数据页(无聚集索引的堆表 )获取实际数据行,此过程可能涉及 “回表” 操作。
五、实验小结(实验中遇到的问题及解决过程、实验中产生的错误及原因分析、实验体会和收获)
1.在进行“DROP INDEX sno_ind DROP INDEX v13.sno_ind”这一步操作时,出现了如下图所示的错误提示

错误原因
在使用DROP INDEX语句删除索引时,没有正确指定要删除索引所在的表名以及索引名 。DROP INDEX语句的语法格式要求明确这两个关键信息,否则数据库引擎无法确定要操作的对象,就会抛出此错误。
解决办法
即按照DROP INDEX 索引名 ON 表名的语法结构,准确填写要删除的索引名称以及该索引所属的表名,这样就能正确执行删除索引的操作。
2.在进行“create view V11 WITH SCHEMABINDING --???
as
select s.sno,sname,class,Sbirthday from student s ”这一步时,出现了如下图所示的错误警告
![]()
解决方法:指定架构名
假设表 student039 所属架构为 dbo(常见默认架构) ,修改视图创建语句如下:
create view V11039 WITH SCHEMABINDING
as
select s.sno,sname,class,Sbirthday from dbo.student039 s
如果表在其他架构下,将 dbo 替换为实际架构名即可。这样明确了表的架构,满足架构绑定对对象名称格式的要求。
3.

错误原因:
在 SQL Server 中,要对视图创建索引(非唯一聚集索引之外的其他索引 ),前提是该视图必须先有一个唯一聚集索引。这是因为唯一聚集索引确定了视图数据的物理存储顺序,为后续创建其他索引提供基础结构。如果视图没有唯一聚集索引,就会出现 “无法对视图 ' 视图名 ' 创建索引。它没有唯一聚集索引” 这样的错误提示 。
解决办法
创建唯一聚集索引:使用以下语句为视图创建唯一聚集索引。
USE STU039
CREATE UNIQUE CLUSTERED INDEX idx_v13039 ON v13039 (SNO);
CREATE INDEX sno_ind ON v13039 (sno)
创建成功后,就可以基于该视图继续创建其他非聚集索引了。
4.在进行”CREATE UNIQUE CLUSTERED INDEX sno_UN_clu_ind --??
ON v13 (sno)
‘出现如下图所示报错![]()

















 159
159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









