



Hive:数据仓库;
Hive:解释器,编译器,优化器等;
Hive运行时,元数据存储在关系型数据库里面。
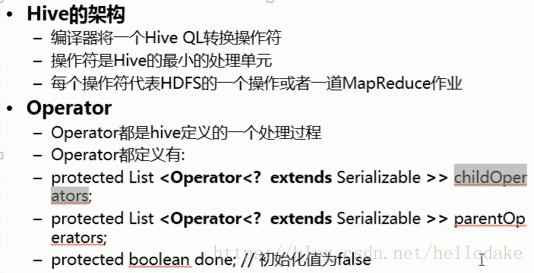
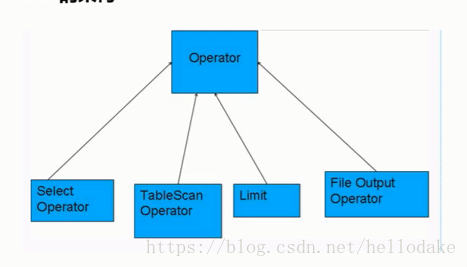
Hive的架构

通过命令行接口接入Hive;
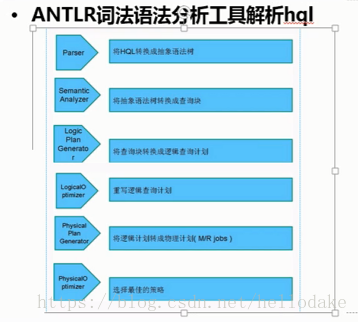
把SQL翻译成map-reduce。数据存在HDFS中,元数据(表信息,表字段)放在关系型数据库中,任务转化成map-reduce任务。
PS.元数据不放在HDFS上,因为慢,而且元数据很小,所以可以放在关系型数据库上。
Hive又是一个数据仓库,只用于查询的数据库。
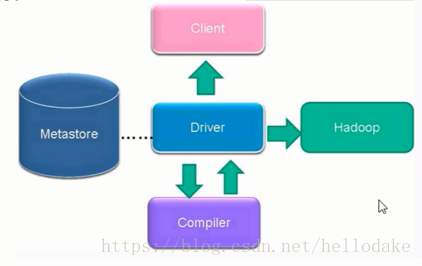
表是建在Hive里,但是表的元数据信息存在关系型数据库中,数据存在HDFS上。
Hive的三种模式
- 单用户模式。此模式连接到一个In-memory的数据库Derby,一般用于Unit Test。
hive-site.xml配置:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=metastore_db;create=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>
注:使用derby存储方式时,运行hive会在当前目录生成一个derby文件和一个metastore_db目录。这种存储方式的弊端是在同一个目录下同时只能有一个hive客户端能使用数据库。
- 单用户模式。通过网络连接到一个数据库中,是最经常使用到的模式。是存到mysql里面。
这种存储方式需要在本地运行一个mysql服务器,并作如下配置(下面两种使用mysql的方式,需要将mysql的jar包拷贝到$HIVE_HOME/lib目录下)。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/hive_remote?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
</property>
</configuration>
- 多用户模式。远程服务器模式。用于非java客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。
命令
show databases;

















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









