



介绍
句法
本节介绍在每种执行模式下执行 Leiden 算法所使用的语法。我们描述了该语法的命名图变体。要了解有关一般语法变体的更多信息,请参阅语法概述。
- 流模式
- 统计模式
- 变异模式
- 写入模式
CALL gds.leiden.stream(
graphName: String,
configuration: Map
)
YIELD
nodeId: Integer,
communityId: Integer,
intermediateCommunityIds: List of Integer| 姓名 | 类型 | 默认 | 选修的 | 描述 |
|---|---|---|---|---|
| 图名 | 细绳 |
| 不 | 存储在目录中的图表的名称。 |
| 配置 | 地图 |
| 是的 | 算法特定和/或图形过滤的配置。 |
| 姓名 | 类型 | 默认 | 选修的 | 描述 |
|---|---|---|---|---|
| 1.分辨率越高,社区越多,分辨率越低,社区越少。 | ||||
| 字符串列表 |
| 是的 | 使用给定的节点标签过滤命名的图表。具有任何给定标签的节点都将包括在内。 | |
| 字符串列表 |
| 是的 | 使用给定的关系类型过滤命名图。将包括具有任何给定类型的关系。 | |
| 整数 |
| 是的 | 用于运行算法的并发线程数。 | |
| 细绳 |
| 是的 | 可以提供一个ID来更轻松地跟踪算法的进度。 | |
| 布尔值 |
| 是的 | 如果禁用,则不会记录进度百分比。 | |
| 细绳 |
| 是的 | 用作权重的关系属性的名称。如果未指定,则算法运行时不加权。 | |
| 最大等级 | 整数 |
| 是的 | 图形聚类然后压缩的最大级别数。 |
| 伽马 | 漂浮 |
| 是的 | 计算模块度时使用的分辨率参数。在内部,该值除以无权图的关系数,否则除以所有关系的权重总和。[1] |
| 西塔 | 漂浮 |
| 是的 | 在将一个社区划分为更小的社区的同时控制随机性。 |
| 漂浮 |
| 是的 | 迭代之间模块度的最小变化。如果模块度变化小于容差值,则认为结果稳定,算法返回。 | |
| 包括中级社区 | 布尔值 |
| 是的 | 指示是否写入中间社区。如果设置为 false,则仅保留最终社区。 |
| 细绳 |
| 是的 | 用于设置节点的初始社区。属性值必须是非负数。 | |
| 最小社区规模 | 整数 |
| 是的 | 仅返回社区内大于或等于给定值的节点。 |
| 姓名 | 类型 | 描述 |
|---|---|---|
| 节点编号 | 整数 | 节点ID。 |
| 社区编号 | 整数 | 最终层的社区ID。 |
| 中间社区 ID | 整数列表 | 每个级别的社区 ID。 |
例子
|
以下所有示例都应在空数据库中运行。 这些示例以Cypher 投影为标准。未来版本中将不再使用原生投影。 |
在本节中,我们将展示在具体图表上运行 Leiden 社区检测算法的示例。目的是说明结果是什么样子,并提供如何在实际环境中使用该算法的指南。我们将在一个由少数几个以特定模式连接的节点组成的小型社交网络图上执行此操作。示例图如下所示:
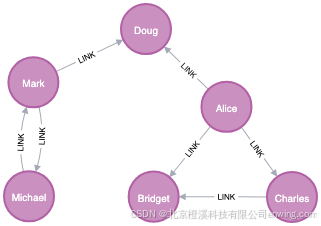
CREATE
(nAlice:User {name: 'Alice', seed: 42}),
(nBridget:User {name: 'Bridget', seed: 42}),
(nCharles:User {name: 'Charles', seed: 42}),
(nDoug:User {name: 'Doug'}),
(nMark:User {name: 'Mark'}),
(nMichael:User {name: 'Michael'}),
(nAlice)-[:LINK {weight: 1}]->(nBridget),
(nAlice)-[:LINK {weight: 1}]->(nCharles),
(nCharles)-[:LINK {weight: 1}]->(nBridget),
(nAlice)-[:LINK {weight: 5}]->(nDoug),
(nMark)-[:LINK {weight: 1}]->(nDoug),
(nMark)-[:LINK {weight: 1}]->(nMichael),
(nMichael)-[:LINK {weight: 1}]->(nMark);该图有两个紧密相连的用户集群。这些集群通过一条边连接。关系属性weight 决定了节点之间各自关系的强度。
现在我们可以投影图形并将其存储在图形目录中。我们加载LINK关系并将方向设置为,UNDIRECTED因为这最适合莱顿算法。
MATCH (source:User)-[r:LINK]->(target:User)
RETURN gds.graph.project(
'myGraph',
source,
target,
{
sourceNodeProperties: source { .seed },
targetNodeProperties: target { .seed },
relationshipProperties: r { .weight }
},
{ undirectedRelationshipTypes: ['*'] }
)在下面的例子中,我们将演示如何在该图上使用莱顿算法。
内存估计
首先,我们将使用该过程估算运行算法的成本estimate。这可以使用任何执行模式来完成。我们将write在本例中使用该模式。估算算法有助于了解在图形上运行算法对内存的影响。当您稍后在某种执行模式下实际运行算法时,系统将执行估算。如果估算显示执行超出内存限制的可能性非常高,则禁止执行。要了解有关此内容的更多信息,请参阅自动估算和执行阻止。
有关更多详细信息estimate,请参阅内存估计。
CALL gds.leiden.write.estimate('myGraph', {writeProperty: 'communityId', randomSeed: 19})
YIELD nodeCount, relationshipCount, requiredMemory| 节点数 | 关系计数 | 所需内存 |
|---|---|---|
| 6 | 14 | “[551 KiB...551 KiB]” |
数据流
在stream执行模式下,算法会返回每个节点的社区 ID。这样我们就可以直接检查结果,或者在 Cypher 中对其进行后处理,而不会产生任何副作用。
有关该模式的更多详细信息stream,请参阅Stream。
CALL gds.leiden.stream('myGraph', { randomSeed: 19 })
YIELD nodeId, communityId
RETURN gds.util.asNode(nodeId).name AS name, communityId
ORDER BY name ASC| 姓名 | 社区编号 |
|---|---|
| “爱丽丝” | 1 |
| “布里奇特” | 1 |
| “查尔斯” | 1 |
| “道格” | 5 |
| “标记” | 5 |
| “迈克尔” | 5 |
我们对过程配置参数使用默认值。maxLevels设置为 10,gamma参数theta分别设置为 1.0 和 0.01。
统计资料
在stats执行模式下,算法返回一行,其中包含算法结果的摘要。此执行模式没有任何副作用。通过检查返回项,它可用于评估算法性能。在下面的示例中,我们将省略返回时间。可以在语法部分computeMillis中找到该过程的完整签名。
CALL gds.leiden.stats('myGraph', { randomSeed: 19 })
YIELD communityCount| 社区数量 |
|---|
| 2 |
合变
执行mutate模式扩展了该stats模式,但有一个重要的副作用:使用包含该节点社区 ID 的新节点属性更新命名图。使用强制配置参数指定新属性的名称mutateProperty。结果是单个摘要行,类似于stats,但带有一些附加指标。mutate当结合使用多种算法时,该模式特别有用。
有关该模式的更多详细信息mutate,请参阅Mutate。
myGraph:
CALL gds.leiden.mutate('myGraph', { mutateProperty: 'communityId', randomSeed: 19 })
YIELD communityCount| 社区数量 |
|---|
| 2 |
在mutate模式下,该过程仅返回一行。结果包含元信息,例如已识别社区的数量。结果写入 GDS 内存图,而不是 Neo4j 数据库。
写
执行write模式扩展了该stats模式,并产生了一个重要的副作用:将每个节点的社区 ID 作为属性写入 Neo4j 数据库。新属性的名称使用强制配置参数指定writeProperty。结果是单个摘要行,类似于stats,但包含一些附加指标。该write模式允许将结果直接持久保存到数据库。
有关该模式的更多详细信息write,请参阅写入。
CALL gds.leiden.write('myGraph', { writeProperty: 'communityId', randomSeed: 19 })
YIELD communityCount, nodePropertiesWritten| 社区数量 | 节点属性 |
|---|---|
| 2 | 6 |
在write模式下,该过程仅返回一行。结果包含元信息,例如已识别社区的数量。结果写入 Neo4j 数据库,而不是 GDS 内存图中。
加权
Leiden 算法也可以在加权图上运行,在计算模块度时考虑给定的关系权重。
CALL gds.leiden.stream('myGraph', { relationshipWeightProperty: 'weight', randomSeed: 19 })
YIELD nodeId, communityId
RETURN gds.util.asNode(nodeId).name AS name, communityId
ORDER BY name ASC| 姓名 | 社区编号 |
|---|---|
| “爱丽丝” | 4 |
| “布里奇特” | 1 |
| “查尔斯” | 1 |
| “道格” | 4 |
| “标记” | 5 |
| “迈克尔” | 5 |
利用加权关系,我们看到Alice并Doug形成了他们自己的社区,因为他们的联系比所有其他联系都要强得多。
使用中间社区
如前所述,Leiden 是一种分层聚类算法。这意味着在每个聚类步骤之后,属于同一簇的所有节点都会减少为单个节点。同一簇的节点之间的关系成为自关系,与其他簇的节点的关系连接到簇代表。然后使用此压缩图运行下一级聚类。重复该过程,直到簇稳定。
为了证明这种迭代行为,我们需要构建一个更复杂的图。
CREATE (a:Node {name: 'a'})
CREATE (b:Node {name: 'b'})
CREATE (c:Node {name: 'c'})
CREATE (d:Node {name: 'd'})
CREATE (e:Node {name: 'e'})
CREATE (f:Node {name: 'f'})
CREATE (g:Node {name: 'g'})
CREATE (h:Node {name: 'h'})
CREATE (i:Node {name: 'i'})
CREATE (j:Node {name: 'j'})
CREATE (k:Node {name: 'k'})
CREATE (l:Node {name: 'l'})
CREATE (m:Node {name: 'm'})
CREATE (n:Node {name: 'n'})
CREATE (x:Node {name: 'x'})
CREATE (a)-[:TYPE]->(b)
CREATE (a)-[:TYPE]->(d)
CREATE (a)-[:TYPE]->(f)
CREATE (b)-[:TYPE]->(d)
CREATE (b)-[:TYPE]->(x)
CREATE (b)-[:TYPE]->(g)
CREATE (b)-[:TYPE]->(e)
CREATE (c)-[:TYPE]->(x)
CREATE (c)-[:TYPE]->(f)
CREATE (d)-[:TYPE]->(k)
CREATE (e)-[:TYPE]->(x)
CREATE (e)-[:TYPE]->(f)
CREATE (e)-[:TYPE]->(h)
CREATE (f)-[:TYPE]->(g)
CREATE (g)-[:TYPE]->(h)
CREATE (h)-[:TYPE]->(i)
CREATE (h)-[:TYPE]->(j)
CREATE (i)-[:TYPE]->(k)
CREATE (j)-[:TYPE]->(k)
CREATE (j)-[:TYPE]->(m)
CREATE (j)-[:TYPE]->(n)
CREATE (k)-[:TYPE]->(m)
CREATE (k)-[:TYPE]->(l)
CREATE (l)-[:TYPE]->(n)
CREATE (m)-[:TYPE]->(n);MATCH (source:Node)
OPTIONAL MATCH (source)-[r:TYPE]->(target:Node)
RETURN gds.graph.project(
'myGraph2',
source,
target,
{},
{ undirectedRelationshipTypes: ['*'] }
)流中间社区
CALL gds.leiden.stream('myGraph2', {
randomSeed: 23,
includeIntermediateCommunities: true,
concurrency: 1
})
YIELD nodeId, communityId, intermediateCommunityIds
RETURN gds.util.asNode(nodeId).name AS name, communityId, intermediateCommunityIds
ORDER BY name ASC| 姓名 | 社区编号 | 中间社区 ID |
|---|---|---|
| “A” | 4 | [2, 4] |
| “b” | 4 | [2, 4] |
| “C” | 5 | [7, 5] |
| “d” | 4 | [2, 4] |
| “e” | 5 | [6, 5] |
| “F” | 5 | [7, 5] |
| “G” | 5 | [7, 5] |
| “H” | 5 | [11, 5] |
| “我” | 5 | [11, 5] |
| “j” | 1 | [12, 1] |
| “k” | 1 | [12, 1] |
| “我” | 1 | [12, 1] |
| “米” | 1 | [12, 1] |
| “n” | 1 | [12, 1] |
| “X” | 5 | [6, 5] |
播种
通过提供种子属性,可以逐步运行 Louvain 算法。如果指定,种子属性将为已加载节点的子集提供初始社区映射。该算法将尝试保留种子社区 ID。
CALL gds.leiden.stream('myGraph2', {
randomSeed: 23,
includeIntermediateCommunities: true,
concurrency: 1
})
YIELD nodeId, communityId, intermediateCommunityIds
RETURN gds.util.asNode(nodeId).name AS name, communityId, intermediateCommunityIds
ORDER BY name ASC| 姓名 | 社区编号 | 中间社区 ID |
|---|---|---|
| “爱丽丝” | 四十二 | 无效的 |
| “布里奇特” | 四十二 | 无效的 |
| “查尔斯” | 四十二 | 无效的 |
| “道格” | 四十五 | 无效的 |
| “标记” | 四十五 | 无效的 |
| “迈克尔” | 四十五 | 无效的 |
可以看出,使用种子图,节点Alice保留其初始社区 ID 42。另一个社区已被分配一个新的社区 ID,该 ID 保证大于最大种子社区 ID。请注意,consecutiveIds配置选项不能与种子结合使用,以保留种子值
变异中间社区
CALL gds.leiden.stream('myGraph2', {
randomSeed: 23,
includeIntermediateCommunities: true,
concurrency: 1
})
YIELD nodeId, communityId, intermediateCommunityIds
RETURN gds.util.asNode(nodeId).name AS name, communityId, intermediateCommunityIds
ORDER BY name ASC| 社区数量 | 模块化 | 模块化 |
|---|---|---|
| 3 | 0.3624 | [0.3296, 0.3624] |
CALL gds.leiden.stream('myGraph2', {
randomSeed: 23,
includeIntermediateCommunities: true,
concurrency: 1
})
YIELD nodeId, communityId, intermediateCommunityIds
RETURN gds.util.asNode(nodeId).name AS name, communityId, intermediateCommunityIds
ORDER BY name ASC| 姓名 | 中级社区 |
|---|---|
| “A” | [2, 4] |
| “b” | [2, 4] |
| “C” | [7, 5] |
| “d” | [2, 4] |
| “e” | [6, 5] |
| “F” | [7, 5] |
| “G” | [7, 5] |
| “H” | [11, 5] |
| “我” | [11, 5] |
| “j” | [12, 1] |
| “k” | [12, 1] |
| “我” | [12, 1] |
| “米” | [12, 1] |
| “n” | [12, 1] |
| “X” | [6, 5] |
撰写中间社区
CALL gds.leiden.stream('myGraph2', {
randomSeed: 23,
includeIntermediateCommunities: true,
concurrency: 1
})
YIELD nodeId, communityId, intermediateCommunityIds
RETURN gds.util.asNode(nodeId).name AS name, communityId, intermediateCommunityIds
ORDER BY name ASC| 社区数量 | 模块化 | 模块化 |
|---|---|---|
| 3 | 0.3624 | [0.3296, 0.3624] |
CALL gds.leiden.stream('myGraph2', {
randomSeed: 23,
includeIntermediateCommunities: true,
concurrency: 1
})
YIELD nodeId, communityId, intermediateCommunityIds
RETURN gds.util.asNode(nodeId).name AS name, communityId, intermediateCommunityIds
ORDER BY name ASC| 姓名 | 中级社区 |
|---|---|
| “A” | [2, 4] |
| “b” | [2, 4] |
| “C” | [7, 5] |
| “d” | [2, 4] |
| “e” | [6, 5] |
| “F” | [7, 5] |
| “G” | [7, 5] |
| “H” | [11, 5] |
| “我” | [11, 5] |
| “j” | [12, 1] |
| “k” | [12, 1] |
| “我” | [12, 1] |
| “米” | [12, 1] |
| “n” | [12, 1] |
| “X” | [6, 5] |


















 2303
2303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











