



 本文介绍了一个基于Fashion MNIST数据集的深度学习模型。该模型使用深度可分离卷积网络,通过自编码器结构进行图像分类任务。模型在60000个训练样本和10000个验证样本上进行了训练,最终达到了90.84%的训练准确率和89.47%的验证准确率。文中详细展示了数据预处理、模型构建、训练过程及结果分析。
本文介绍了一个基于Fashion MNIST数据集的深度学习模型。该模型使用深度可分离卷积网络,通过自编码器结构进行图像分类任务。模型在60000个训练样本和10000个验证样本上进行了训练,最终达到了90.84%的训练准确率和89.47%的验证准确率。文中详细展示了数据预处理、模型构建、训练过程及结果分析。
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import tensorflow as tf
import numpy as np
import pandas as pd
import os
(X_train,y_train),(X_test,y_test)=tf.keras.datasets.fashion_mnist.load_data()
X_train.shape,X_test.shape,y_train.shape,y_test.shape
((60000, 28, 28), (10000, 28, 28), (60000,), (10000,))
将60000×28×28的数据变成二维数,组然后用sklearn的StandardScaler进行数据预处理 ,sklearn不能直接处理图片张量
X_train_1 = StandardScaler().fit_transform(X_train.astype(np.float32).reshape(-1,1))
X_train_1.shape
(47040000, 1)
X_train_2 = X_train_1.reshape(-1,28,28)
X_train_2.shape
(60000, 28, 28)
X_train_2.shape[1:]
(28, 28)
X_test_2 = StandardScaler().fit_transform(X_test.astype(np.float32).reshape(-1,1)).reshape(-1,28,28)
X_test_2.shape
(10000, 28, 28)
X_train = np.expand_dims(X_train_2,-1)
X_test = np.expand_dims(X_test_2,-1)
X_train.shape,X_test.shape
((60000, 28, 28, 1), (10000, 28, 28, 1))
y_train = y_train.astype(np.int32)
y_test = y_test.astype(np.int32)
y_train.shape,y_test.shape
((60000,), (10000,))
深度可分离卷积网络,自编码器结构
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(filters=64,kernel_size=(3,3),
padding='same',activation='selu',
input_shape=(X_train.shape[1:])))
model.add(tf.keras.layers.MaxPool2D())
model.add(tf.keras.layers.SeparableConv2D(filters=32,kernel_size=(3,3),padding='same',activation='selu'))
model.add(tf.keras.layers.MaxPool2D())
model.add(tf.keras.layers.SeparableConv2D(filters=16,kernel_size=(3,3),padding='same',activation='selu'))
model.add(tf.keras.layers.MaxPool2D())
model.add(tf.keras.layers.SeparableConv2D(filters=32,kernel_size=(3,3),padding='same',activation='selu'))
model.add(tf.keras.layers.MaxPool2D())
model.add(tf.keras.layers.SeparableConv2D(filters=64,kernel_size=(3,3),padding='same',activation='selu'))
model.add(tf.keras.layers.GlobalAveragePooling2D())
model.add(tf.keras.layers.Dense(10,activation='softmax'))
保存模型
logdir = './cnn_selu_callbacks'
if not os.path.exists(logdir):
os.mkdir(logdir)
output_model_file = os.path.join(logdir,"fashion_minist_model_1.h5")
设置自动下降学习率,早停
callbacks = [
#tf.keras.callbacks.TensorBoard(log_dir=logdir), #log_dir将输出的日志保存在所要保存的路径中
tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss',
patience=3,
factor=0.5,
min_lr=0.00001),
#tf.keras.callbacks.ModelCheckpoint(output_model_file,save_best_only=True)
tf.keras.callbacks.EarlyStopping(patience=6, min_delta=0.000001),
tf.keras.callbacks.ModelCheckpoint(output_model_file,
save_best_only=True,
save_weights_only=True,monitor='val_loss')]
model.compile(optimizer='Adam',
loss='sparse_categorical_crossentropy',
metrics=['acc'])
history = model.fit(X_train, y_train,epochs=30,
shuffle=True,
batch_size=128,
validation_data=(X_test, y_test),
callbacks=callbacks)
Train on 60000 samples, validate on 10000 samples
Epoch 1/30
60000/60000 [==============================] - 11s 182us/sample - loss: 0.9925 - acc: 0.6357 - val_loss: 0.6348 - val_acc: 0.7541
Epoch 30/30
60000/60000 [==============================] - 5s 89us/sample - loss: 0.2477 - acc: 0.9084 - val_loss: 0.3021 - val_acc: 0.8947
XX = X_test[0].reshape(28,28)
XX.shape
(28, 28)
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 64) 640
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 64) 0
_________________________________________________________________
separable_conv2d (SeparableC (None, 14, 14, 32) 2656
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 32) 0
_________________________________________________________________
separable_conv2d_1 (Separabl (None, 7, 7, 16) 816
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 3, 3, 16) 0
_________________________________________________________________
separable_conv2d_2 (Separabl (None, 3, 3, 32) 688
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 1, 1, 32) 0
_________________________________________________________________
separable_conv2d_3 (Separabl (None, 1, 1, 64) 2400
_________________________________________________________________
global_average_pooling2d (Gl (None, 64) 0
_________________________________________________________________
dense (Dense) (None, 10) 650
=================================================================
Total params: 7,850
Trainable params: 7,850
Non-trainable params: 0
_________________________________________________________________
可训练参数只有7850个,远远小于普通的卷积神经网络
plt.imshow(XX)
<matplotlib.image.AxesImage at 0x1b9f3c49400>
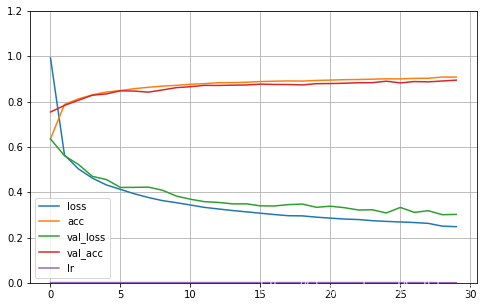
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize = (8,5))
plt.grid(True)
plt.gca().set_ylim(0,1.2)
plt.show()
plot_learning_curves(history)
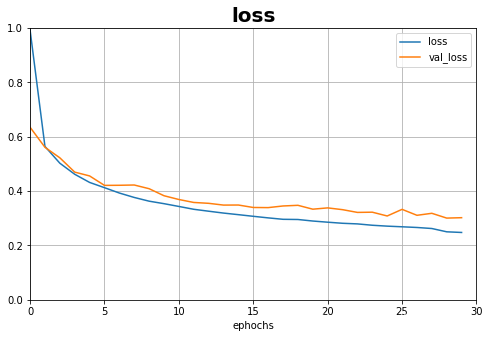
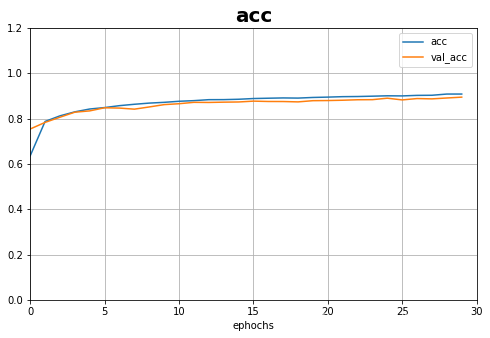
分开画图:
def plot_learning_curves_1(history,label,ephochs,min_value,max_value,title):
data = {}
data[label] = history.history[label]
data['val_'+label] = history.history['val_'+label]
pd.DataFrame(data).plot(figsize = (8,5))
plt.grid(True)
plt.axis([0, ephochs, min_value, max_value])
plt.xlabel('ephochs')
plt.title(title,fontsize=20,fontweight='heavy')
plt.show()
plot_learning_curves_1(history,'acc',30,0,1.2,title='acc')
plot_learning_curves_1(history,'loss',30,0,1,title='loss')
plt.plot(history.epoch,history.history.get(‘loss’),label=‘loss’,color=‘limegreen’,linewidth=‘2’)
plt.plot(history.epoch,history.history.get(‘val_loss’),label=‘val_loss’,color=‘tomato’,linewidth=‘2’)
plt.legend(loc=‘best’)
plt.title(“dasdasdas”)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











