






 本文主要分析了Druid数据源的初始化过程,特别是连接对象如何在三个数组中管理。重点讨论了可重入锁在连接池中的应用,以及如何通过empty和notEmpty两个条件锁来控制线程在达到最大连接数或无可用连接时的阻塞与唤醒。此外,还提到了过滤器采用的责任链模式,通过串联多个过滤器实现高效执行。
本文主要分析了Druid数据源的初始化过程,特别是连接对象如何在三个数组中管理。重点讨论了可重入锁在连接池中的应用,以及如何通过empty和notEmpty两个条件锁来控制线程在达到最大连接数或无可用连接时的阻塞与唤醒。此外,还提到了过滤器采用的责任链模式,通过串联多个过滤器实现高效执行。
今天小结下,前几天分析的 Druid 源码。
由于每天可投入的有效时间有限,只把 Druid 最基本的流程大概看了下,但还是有些疑惑点的。
最重要的就是获取连接方法中的初始化方法 init(),连接对象保存在3个数组中,后续创建和销毁线层都是通过操作这3个数组来完成的。
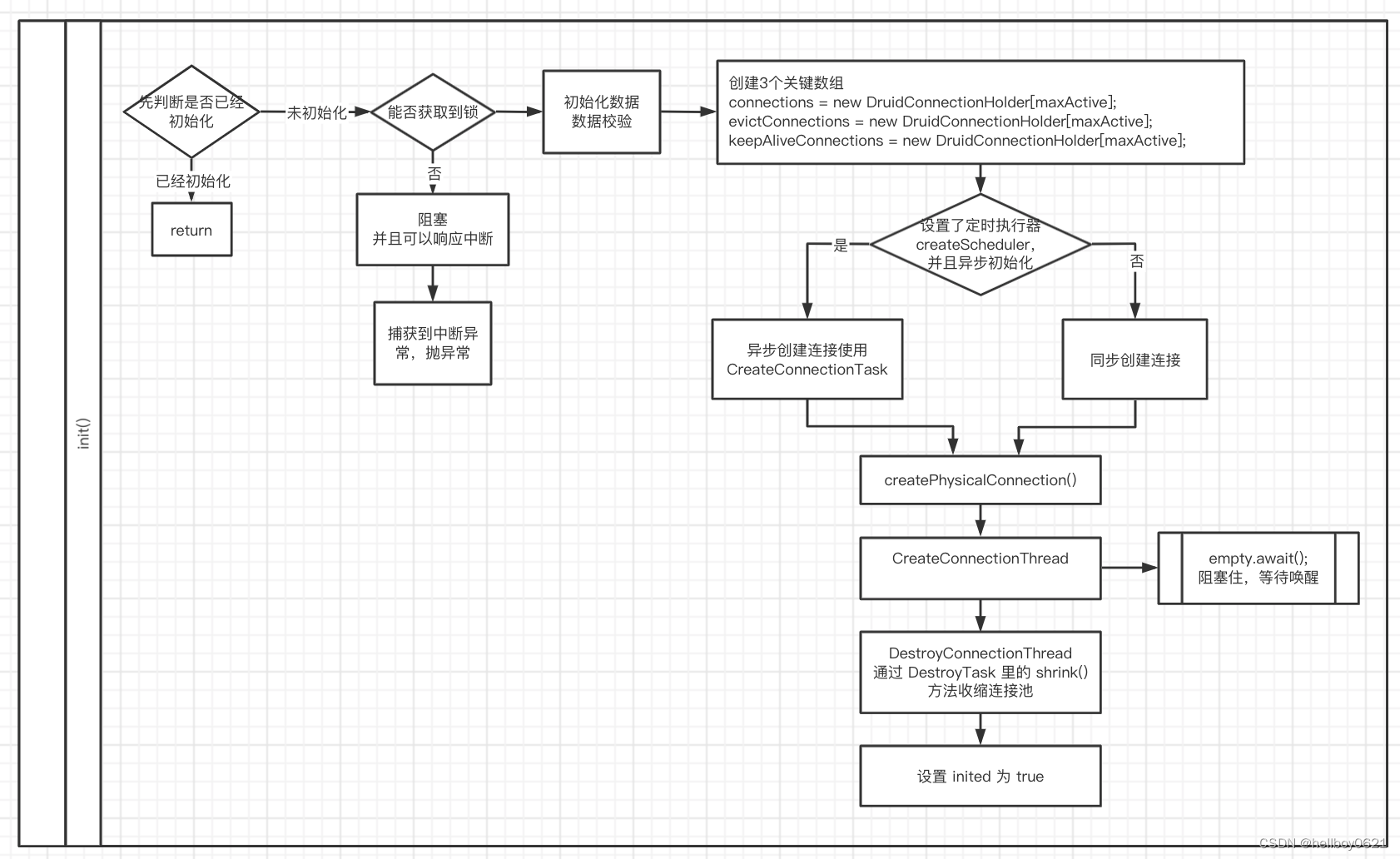 再有就是可重入锁 lock,以及可重入锁上的2个条件 empty 和 notEmpty。
再有就是可重入锁 lock,以及可重入锁上的2个条件 empty 和 notEmpty。
用来控制线程池中
- 如果连接数已经达到最大连接数时,线程阻塞,不再创建新的连接;
- 如果连接池中没有可用连接时,阻塞,并且通知创建线程恢复,待创建连接后,再通知获取连接线程恢复,获取到连接。
还知道了过滤器使用了责任链模式,把多个过滤器串起来执行,最后执行了真正的操作后再反过来依次返回。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









