




HIVE 生成大量小文件
今天运维人员突然发来了告警,有一张表生成的小文件太多,很疑惑,然后排查记录了下
HIVE的版本 2.x,使用的引擎是 MR;
注意:HIVE ON SPARK 或 SPARK-SQL 生成的小文件的方式不同,该篇文章针对 MR 引擎的 HIVE
小文件的危害
① 增加 TASK 的数量
当我们执行表查询时,每个文件都会生成一个 MapTask,在文件内容比较小的时候,过多的 Task 数量反而会降低查询的性能(因为 MapTask 的启动时间可能大于逻辑执行时间);同时每个JOB 生成的 MAP TASK 的数量是有限制的,可能会影响到其他JOB
② 增加 NameNode 的负担
我们知道,在 HADOOP 启动的时候,会通过 fsImage文件和edits文件 加载出所有文件的元数据信息,然后保存在 NameNode 节点的内存中,每个HDFS文件元信息(位置,大小,分块等)对象约占150字节,如果小文件过多,会占用大量内存,直接影响NameNode的性能。因此大量的小文件会严重占用 NameNode 的内存,有可能影响整个 Hadoop 集群的性能,因此,减少小文件的数量很有必要
为什么会生成多个小文件
HIVE 生成的小文件过多,指的是该表在 HDFS 目录下,有多个文件,且文件的磁盘占用比较小;
表的文件一般是向表插入数据的时候生成的,所以我们应该分析下插入数据的方式
不同的数据加载方式生成文件的区别
① 通过文件向表中加载数据
使用 LOAD 方式可以导入文件或文件夹,当导入一个文件时,HIVE 表就有一个文件,当导入文件夹时,HIVE 表的文件数量为文件夹下所有文件的数量
-- 导入文件
load data local inpath '/opt/data/cust_info.txt' overwrite into table cust_info
-- 导入文件夹
load data local inpath '/opt/data/cust_info' overwrite into table cust_ifno
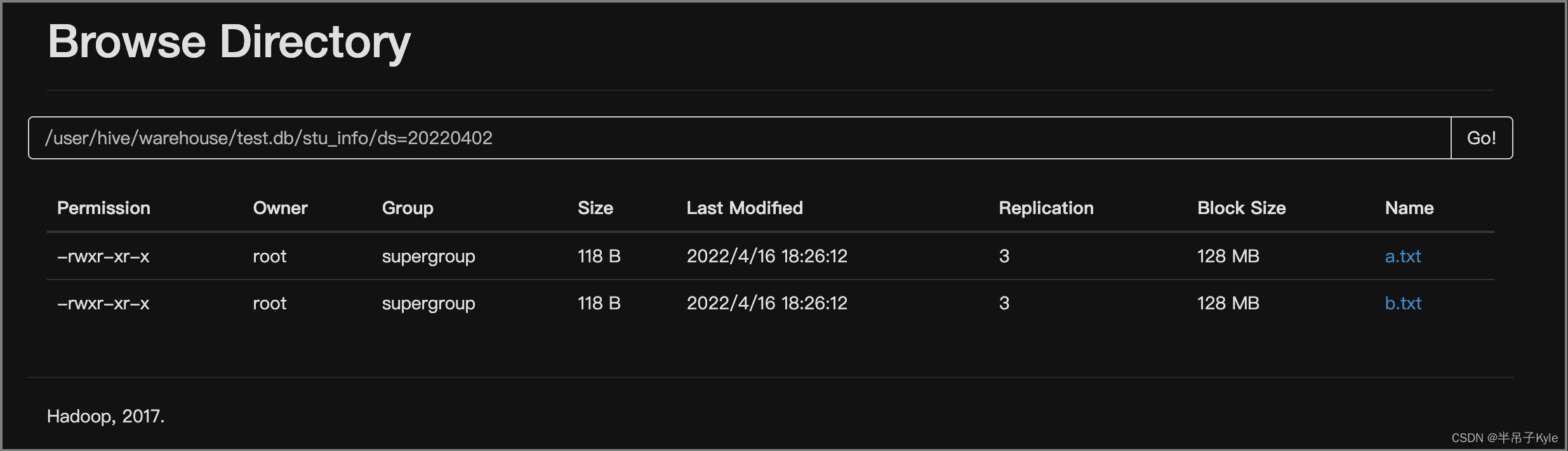
② 直接向表中插入数据
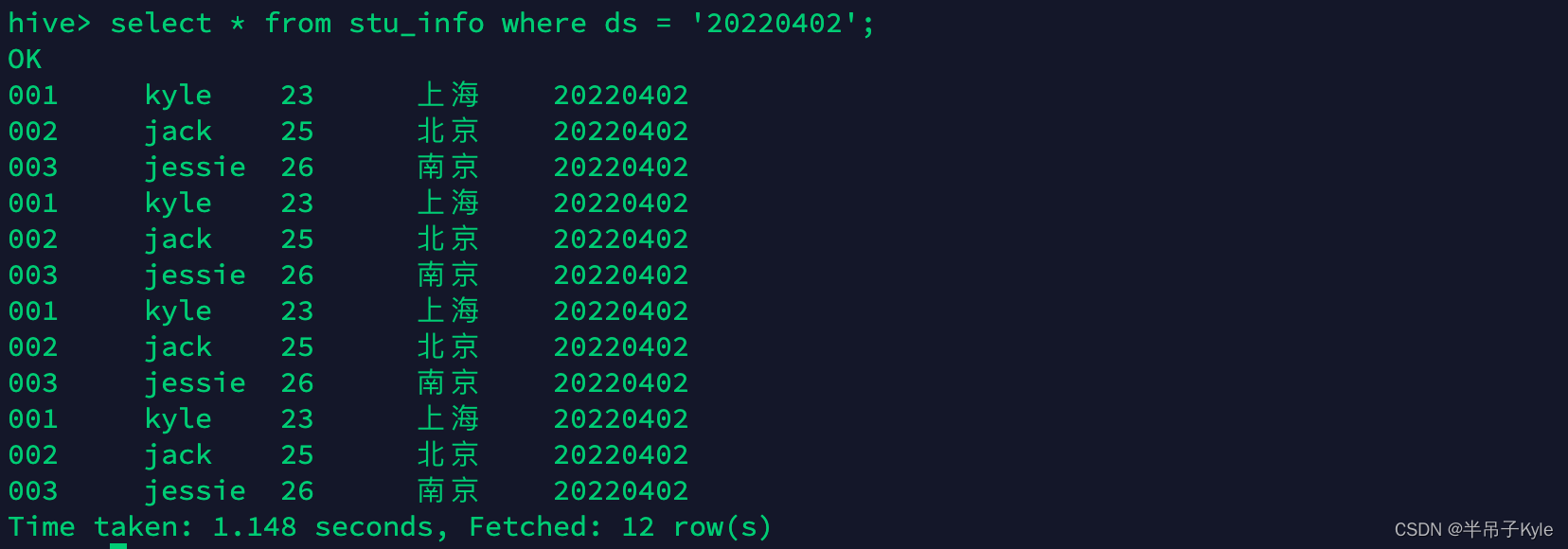
每次插入时都会产生一个文件,多次插入少量数据就会出现多个小文件
-- 执行两次看下结果
insert into table stu_info partition(ds = '20220405') values ('001','kyle', '22', 'beijing'),('002', 'lisa', '23', 'shanghai');
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1075
1075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









