




 本文探讨了MySQL中IN子查询与索引的问题,特别是在5.7版本下的表现。通过举例说明,当使用IN子查询时,外层表未利用索引,而使用JOIN则能更好地利用索引。同时指出,MySQL从5.6版本开始,优化器对子查询和OR语句的处理有了提升,在5.7版本中可以直接使用索引。作者鼓励读者尝试不同MySQL版本以验证这些行为。
本文探讨了MySQL中IN子查询与索引的问题,特别是在5.7版本下的表现。通过举例说明,当使用IN子查询时,外层表未利用索引,而使用JOIN则能更好地利用索引。同时指出,MySQL从5.6版本开始,优化器对子查询和OR语句的处理有了提升,在5.7版本中可以直接使用索引。作者鼓励读者尝试不同MySQL版本以验证这些行为。
今天和大家看下关于in索引的问题.
我本地是5.7版本
这是我的数据结构和表定义
CREATE TABLE test (
id int(10) unsigned NOT NULL AUTO_INCREMENT,
name varchar(191) COLLATE utf8mb4_unicode_ci NOT NULL,
display_name varchar(191) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (id),
KEY keyname (display_name),
KEY name (name(4))
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
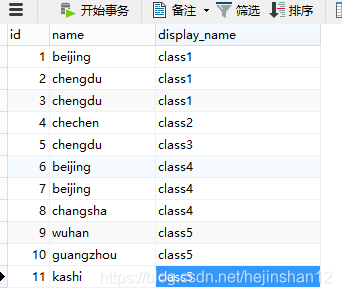
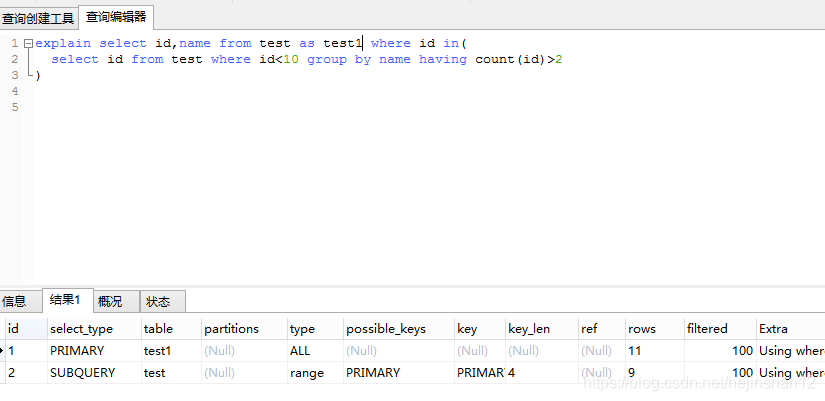
现在有一个需求,统计id小于并且name出现超过2次的数据.
1.使用in
select id,name from test as test1 where id in(
select id from test where id<10 group by name having count(id)>2
)
外层表没有用到索引.
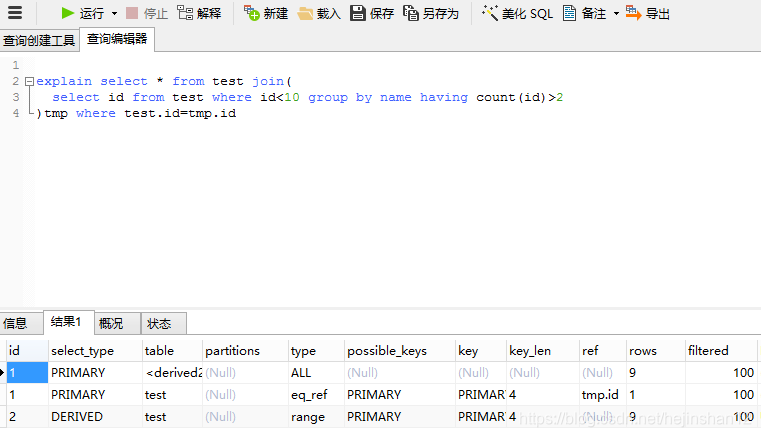
2.使用join,外层表使用到了索引
mysql 子查询直接使用直接值也是走索引的
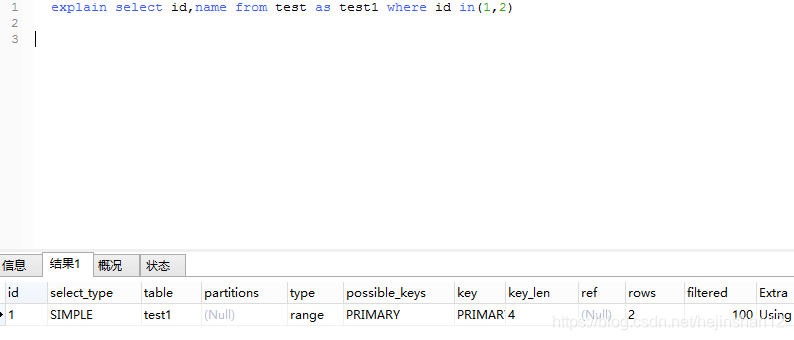
之前有见网上说or语句在innodb下不走索引是在含5.5版本之下,5.7中是可以的.
关联子查询
select * from film where file_id in (select film_id from film_actor where actor_id=1);
一般会认为mysql会先执行子查询返回所有包含actor_id为1的film_id.我们会认为上面的查询会这样执行:
--select group_concat(film_id) from film_actor where actor_id=1
--result: 1,23,25
很不幸,mysql不是这样做的.mysql会将相关的外层表压到子查询,它认为这样可以更高效地查找到数据行.也就是说,mysql会将查询改写成下面的样子:
select * from film where exists(
select * from film_actor where actor_id=1
and film_actor.film_id=film.film_id
)
这时,子查询需要根据film_id来关联外表film,因为需要film_id字段,所以mysql认为无法先执行这个子查询.通过explain可以看到子查询是一个相关子查询(dependent subquery)
mysql先选择对film进行全表扫描,然后根据返回的film_id逐个执行子查询,这个查询性能会非常糟糕.
改写:
select film.* from film inner join film_actor using(film_id) where actor_id=1;
这个是之前in查询的执行,查询优化器5.6版本以后,以更高的效率完成,我本地5.7没有出现in的这个相关子查询. 大家有兴趣可以尝试切换mysql版本来运行此类sql.
欢迎修正补充.

















 324
324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









