



 该博客围绕大数据展开,介绍了大数据的诞生、特征与核心工作,着重讲解了Hadoop的分布式存储、计算和资源调度,包括HDFS架构、操作命令、存储原理等,还阐述了分布式计算、MapReduce和YARN。此外,详细介绍了Hive的基础架构、部署、数据库操作语法等内容。
该博客围绕大数据展开,介绍了大数据的诞生、特征与核心工作,着重讲解了Hadoop的分布式存储、计算和资源调度,包括HDFS架构、操作命令、存储原理等,还阐述了分布式计算、MapReduce和YARN。此外,详细介绍了Hive的基础架构、部署、数据库操作语法等内容。
第一章
数据导论
1、什么是数据?
人类的行为及产生的事件的一种记录称之为数据。
2、数据有什么价值?
· 对数据的内容进行深入分析,可以更好的帮助了解事和物在现实世界的运行规律
· 比如,购物的订单记录(数据)可以帮助平台更好的了解消费者,从而促进交易
大数据的诞生
1、大数据的诞生是跟随着互联网的发展的
· 当全球互联网逐步建成(2000年左右),各大企业或政府单位拥有了海量的数据有待处理
· 基于这个前提逐步诞生了以分布式的形式(即多台服务器集群)完成海量数据处理的处理方式, 并逐步发展成现代大数据体系
2、Apache Hadoop对大数据体系的意义
· 第一款获得业界普遍认可的开源分布式解决方案
· 让各类企业都有可用的企业级开源分布式解决方案
· 一定程度上催生出了众多的大数据体系技术栈
· 从Hadoop开始(2008年左右)大数据开始蓬勃发展
大数据概述
1、什么是大数据
· 狭义上:对海量数据进行处理的软件技术体系
· 广义上:数字化、信息化时代的基础支撑,以数据为生活赋能
2、大数据的5个主要特征(5V)

3、大数据的核心工作
· 存储:妥善保存海量待处理数据
· 计算:完成海量数据的价值挖掘
· 传输:协助各个环节的信息传输
大数据软件生态

1、大数据的核心工作
· 存储:妥善保存海量待处理数据
· 计算:完成海量数据的价值挖掘
· 传输:协助各个环节的信息传输
2、大数据软件生态
· 存储:Apache Hadoop HDFS、Apache HBase、Apache Kudu、云平台
· 计算:Apache Hadoop MapReduce、Apache Spack、Apache Flink
· 传输:Apache Kafka、Apache Pulsar、Apache Flume、Apache Sqoop
Hadoop概述
1、什么是Hadoop
Hadoop是开源的技术框架,提供分布式存储、计算、资源调度的解决方案
2、为什么学习Hadoop
· Hadoop诞生早,在企业中广泛应用
· Hadoop概念较为简单,适合大数据分布式入门
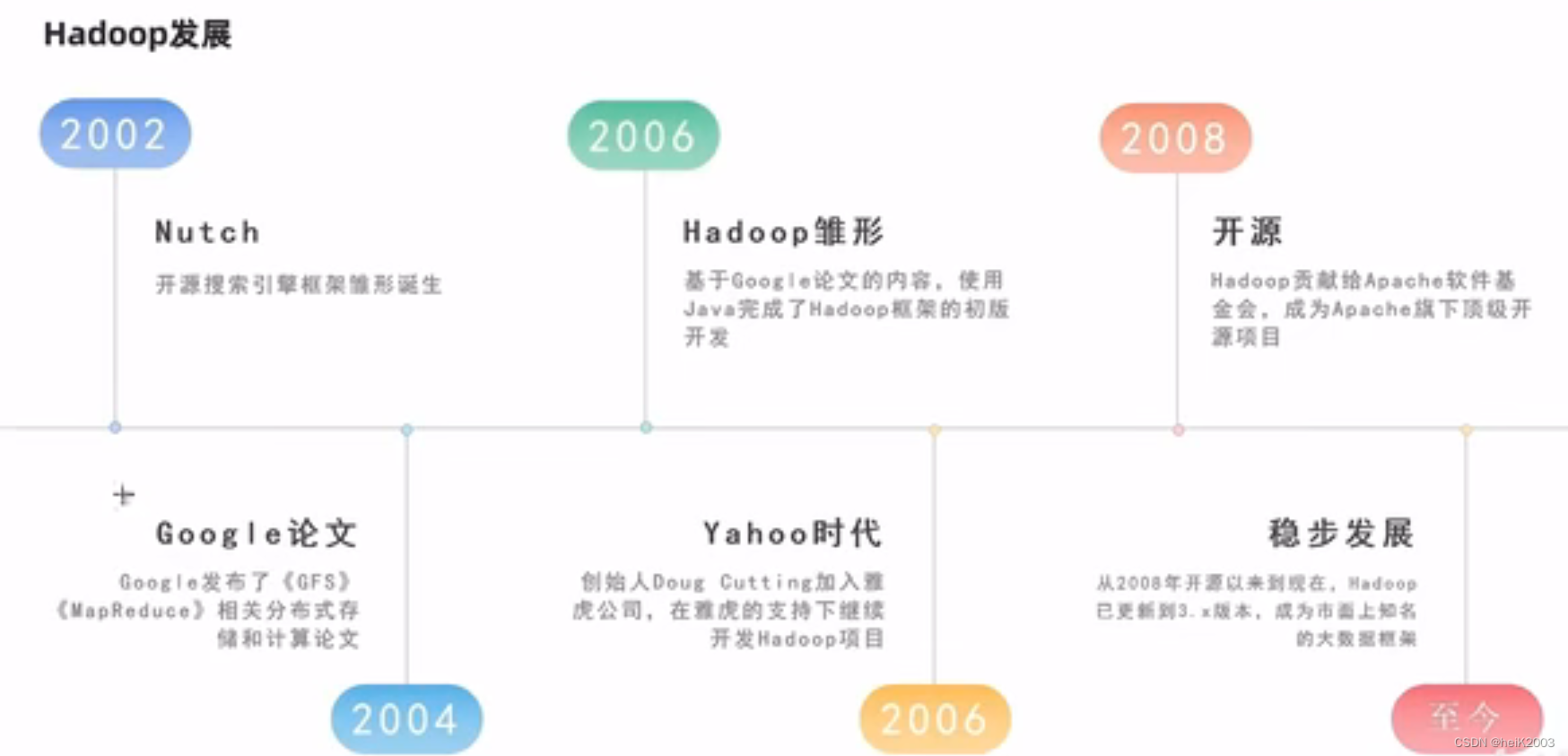
3、Hadoop的发展
· 创始人Doug cutting·基于Nutch搜索项目发展
· 发展受到Google三篇著名的论文影响
《The Google file system》:谷歌分布式文件系统GFS
《MapReduce : Simplified Data Processing on Large clusters》:谷歌分布式计算框架MapReduce
《Bigtable: A Distributed Storage System for Structured Data》:谷歌结构化数据存储系统
4、Hadoop的版本
· Apache开源社区版Hadoop(原生版本)
· 商业公司自行封装的商业版
· CDH
· HDP星环
第二章
为什么需要分布式存储
为什么需要分布式存储?
· 数据量太大,单机存储能力有上限,需要靠数量来解决问题
· 数量的提升带来的是网络传输、磁盘读写、CPU、内存等各方面的
综合提升。分布式组合在一起可以达到1+1>2的效果
分布式的基础架构中心
1、分布式系统常见的组织形式?
· 去中心化模式:没有明确中心,大家协调工作
· 中心化模式:有明确的中心,基于中心节点分配工作
2、什么是主从模式?
主从模式(Master-Slaves)就是中心化模式,表示有一个主节点来作为管理者,管理协调下属一批从节点工作
3、Hadoop是哪种模式?
主从模式(中心化模式)的架构
HDFS的基本架构
1、什么是HDFS?
· HDFS全称:Hadoop Distributed File System
· 是Hadoop三大组件(HDFS、MapReduce、YARN)之一
· 可在多台服务器上构建集群,提供分布 式数据存储能力
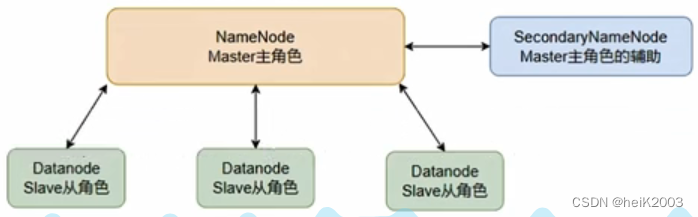
2、HDFS中的架构角色有哪些?
· NameNode:主角色,管理HDFS集群和DataNode角色(领导)
· DataNode:从角色,负责数据的存储(员工)
· SecondaryNameNode:辅助角色,协助NameNode整理元数据(秘书)
3、HDFS的基本架构
HDFS集群启停命令
1、一键启停脚本可用
· $HADOOP_HOME/sbin/start-dfs.sh
· $HADOOP_HOME/sbin/stop-dfs.sh
2、独立进程启停可用
· $HADOOP_HOME/sbin/hadoop-daemon. sh (过时但依旧可用)
用法:hadoop-daemon.sh (start | status | stop) (namenode | secondarynamenode | datanode)
· $HADOOP_HOME/bin/ hdfs --daemon
用法:hdfs --daemon (start | status | stop) (namenode | secondarynamenode | datanode)
HDFS文件系统的命令操作
1、命令操作可以使用(这两种使用效果相同)
· hadoop fs
· hdfs dfs
2、文件系统协议包括
· file://表示Linux本地文件
· hdfs://namenode_server:port/表示HDFS文件系统
比如我配的集群表示为:hdfs://node1:8020/
一般可以省略协议头file://和hdfs://协议头,不用写
3、常用命令(以下我用hdfs dfs进行演示)
· mkdir 创建文件夹
格式:hdfs dfs -mkdir [-p] <path> ...
例:hdfs dfs -mkdir -p /hacker/hadoop
注:-p(可创建副目录)
path不给协议头系统将自动识别。
· ls、cat 列出内容、查看内容
格式:hdfs dfs -ls [-h] [-R] [<path>...]
例:hdfs dfs -ls -h -R /
注:-h(人性化显示文件大小,带单位)
-R(递归查看指定目录及其子目录)
· cp、mv、rm 复制、移动、删除(cp和mv就不演示了,可以类比)
格式:hdfs dfs -rm -r [-skipTrash] <path>
例:hdfs dfs -rm -r /hacker
注:-r(删除的为文件夹)
-skipTrash(跳过回收站,直接删除)
HDFS中回收站功能默认关闭,如果要开启需要在core-site.xml内配置:
<property>
<name>fs.trash.interval</name>
<value>1440</value> # 回收站每个1440分钟清空(即1天)
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>120</value> # 回收站每隔120分钟查看一次(即个2小时)
</property>无需重启集群,在哪个机器配置的,在哪个机器执行命令就生效。回收站默认位置在:/user/用户名(hadoop)/.Trash
· put、get 上传、下载
格式:hdfs dfs -put [-f] [-p] <本地文件系统(Linux)> <目标文件系统(HDFS)>
hdfs dfs -get [-f] [-p] <文件系统(HDFS)> <本地文件系统(Linux)>
例:hdfs dfs -put /hacher/hadoop /
hdfs dfs -get /hadoop /home
注:-f(覆盖已存在的目录文件)
-p(保留访问和修改时间,所有权和权限)
· appendToFile 向文件追加内容
格式:hdfs dfs -appendToFile <本地文件> <HDFS文件》
例:hdfs dfs -appendToFile append.txt /test.txt
注:HDFS系统中文件修改只支持两种,一种是直接删除,另一种是追加
如需查看其他命令可访问:https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-common/FileSystemShell.html
4、可以在HDFS WEBUI网页中进行HDFS文件系统的基本操作
HDFS存储原理
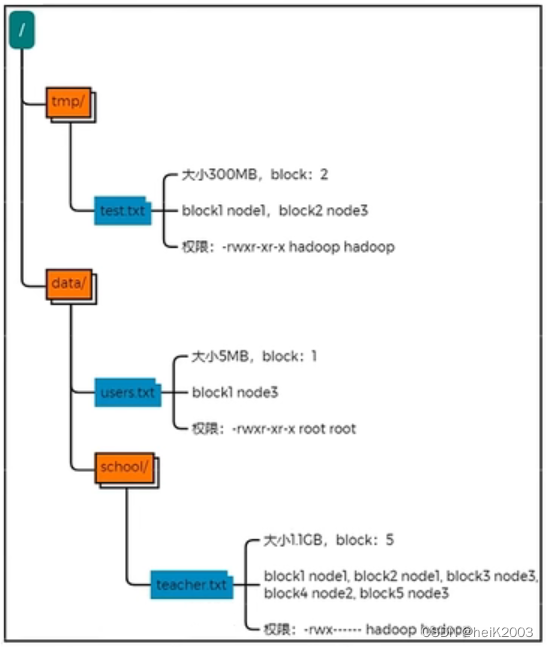
· 数据存入HDFS是分布式存储,即每一个服务器节点,负责数据的一部分
· 数据在HDFS上是划分为一个个Block块进行存储
· 在HDFS上,数据Block块可以有多个副本,提高数据安全性
HDFS修改副本数
1、副本和block的配置
· 配置副本数:dfs.replication,默认3
· 配置block大小:dfs.blocksize,单位为b,一般配置为256MB
2、副本和block相关命令
· 上传文件临时修改副本数:hadoop fs -D dfs.replication=2 -put test.txt /tmp/
· 修改已存在文件副本数:hadoop fs -setrep [-R] 2 path
· 检查文件系统:hdfs fsck path [-files [-blocks [-locations]]]
NameNode元数据
1、NameNode基于
· edits记录每次操作
· fsimage,记录某一个时间节点前的当前文件系统全部文件的状态和信息,维护整个文件系统元数据
2、edits文件会被合并到fsimage中,这个合并由:SecondaryNameNode来操作
3、fsimage记录的内容是:
HDFS数据的读写流程
1、数据写入流程
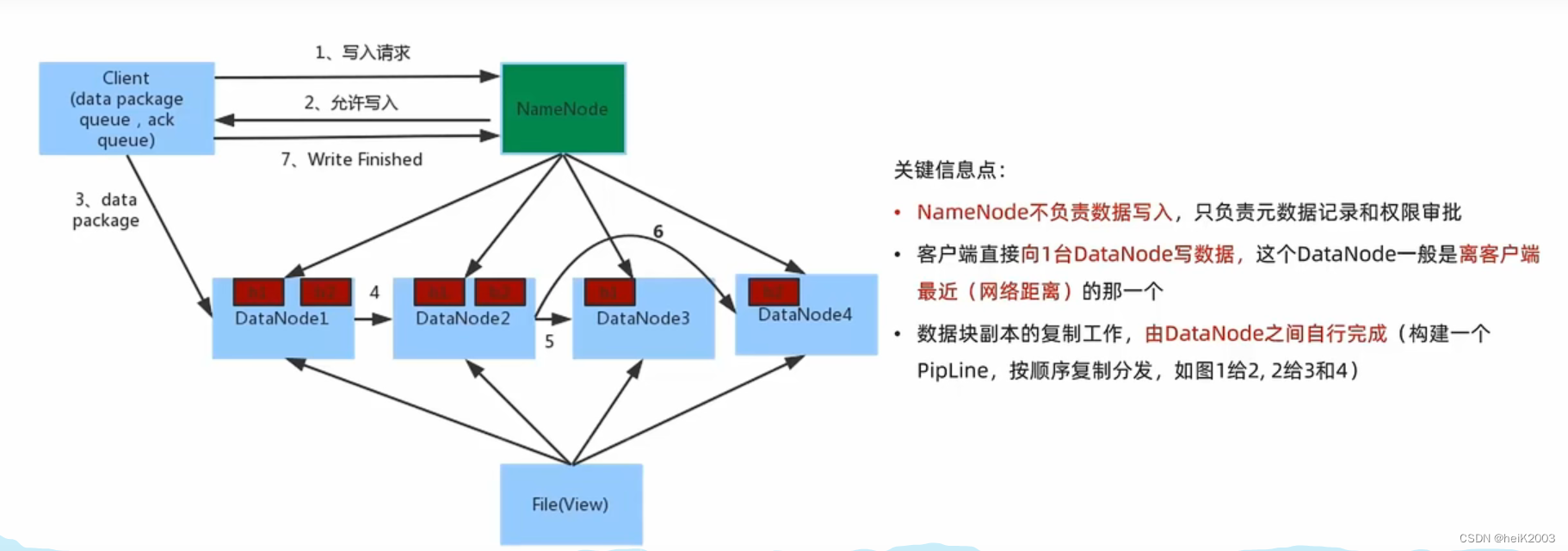
· 客户端向NameNode发起请求
· NameNode审核权限、剩余空间后,满足条件允许写入,并告知客户端写入DataNode地址
· 客户端向指定的DataNode发送数据包
· 被写入数据的DataNode同时完成数据副本的复制工作,将其接收的数据分发给其他DataNode
· 如上图,DataNode1复制给DataNode2,然后基于DataNode2复制给DataNode3和DataNode4
· 写入完成客户端通知NameNode,NameNode做元数据记录工作
2、数据读取流程
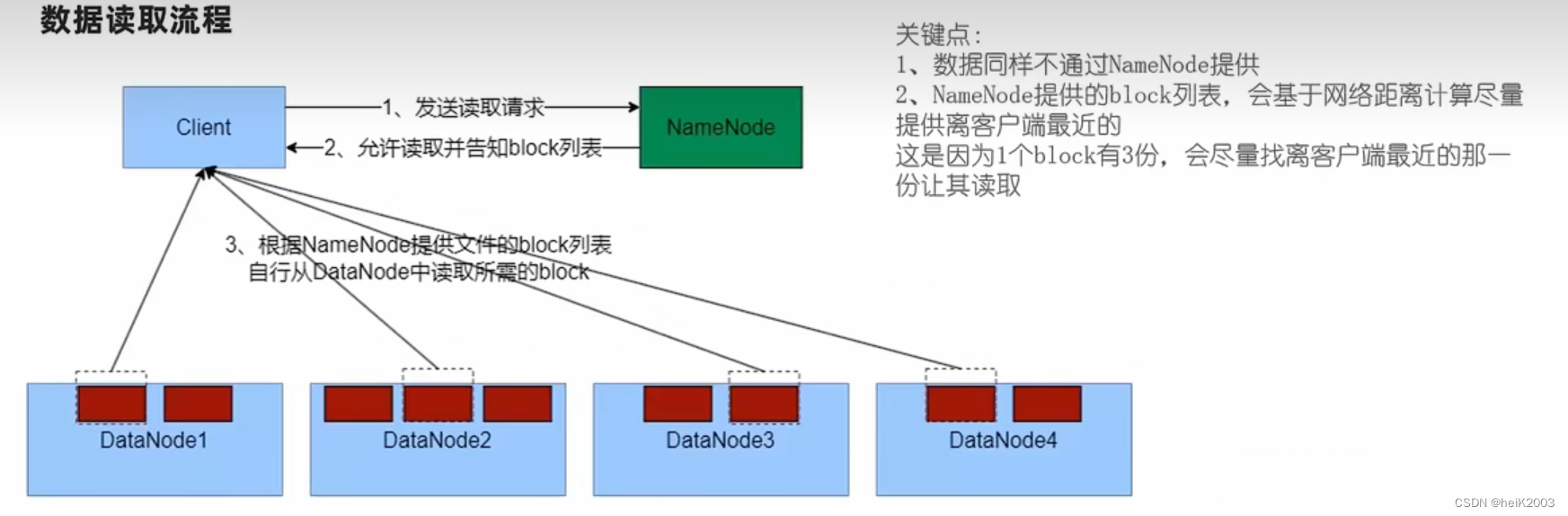
· 客户端向NameNode申请读取文件
· NameNode判断客户端权限等细节后,允许读取,并返回此文件的block列表
· 客户端拿到block列表后自行寻找DataNode读取即可
3、对于客户端读取HDFS数据流程中,一定要知道
不论读还是写,NameNode都不经手数据,均是客户端和DataNode直接通讯,不然对NameNode压力太大
4、写入和读取数据的流程,简单来说就是:
· NameNode做授权判断(是否能写,是否能读)
· 客户端直连DataNode进行写入(由DataNode自己完成副本复制)、客户端直连DataNode进行block读取
· 写入,客户端会被分配找离自己最近的DataNode写数据
· 读取,客户端拿到的block列表,会是网络最近的一份
5、网络距离
· 最近的距离就是在同一台机器
· 其次就是在同一个局域网(交换机)
· 再其次就是跨越交换机
· 再其次就是跨越数据中心
HDFS内置网络距离计算算法,可以通过IP地址、路由表来推断网络距离
第三章
分布式计算概述
1、什么是计算、分布式计算
· 计算:对数据进行处理,使用统计分析等手段得到需要的结果
· 分布式计算:多台服务器协同工作,共同完成一个计算任务
2、分布式计算常见的2种工作模式
· 分散 --> 汇总(MapReduce就是这种模式)
1.将数据分片,多台服务器各自负责一部分数据处理
2.然后将各自的结果,进行汇总处理
3.最终得到想要的计算结果
例:生活中的“人口普查”
· 中心调度 --> 步骤执行(大数据Spark、Flink等是这种模式)
1.由一个节点作为中心调度管理者
2.将任务划分为几个具体步骤
3.管理者安排每个机器执行任务
4.最终得到结果数据
例:生活中的各类项目的:项目经理和项目成员就是这种模式,一个管理分配任务,其余人员领取任务工作
中心调度相对于分散-汇总来说多了个数据交换过程
MapReduce概述
1、什么是MapReduce
· MapReduce是Hadoop中的分布式计算组件
· MapReduce可以以分散->汇总(聚合)模式执行分布式计算任务
2、MapReduce的主要编程接口
· map接口,主要提供“分散”功能,由服务器分布式处理数据
· reduce接口,主要提供“汇总”功能,进行数据汇总统计得到结果
· MapReduce可供Java、Python等语言开发计算程序
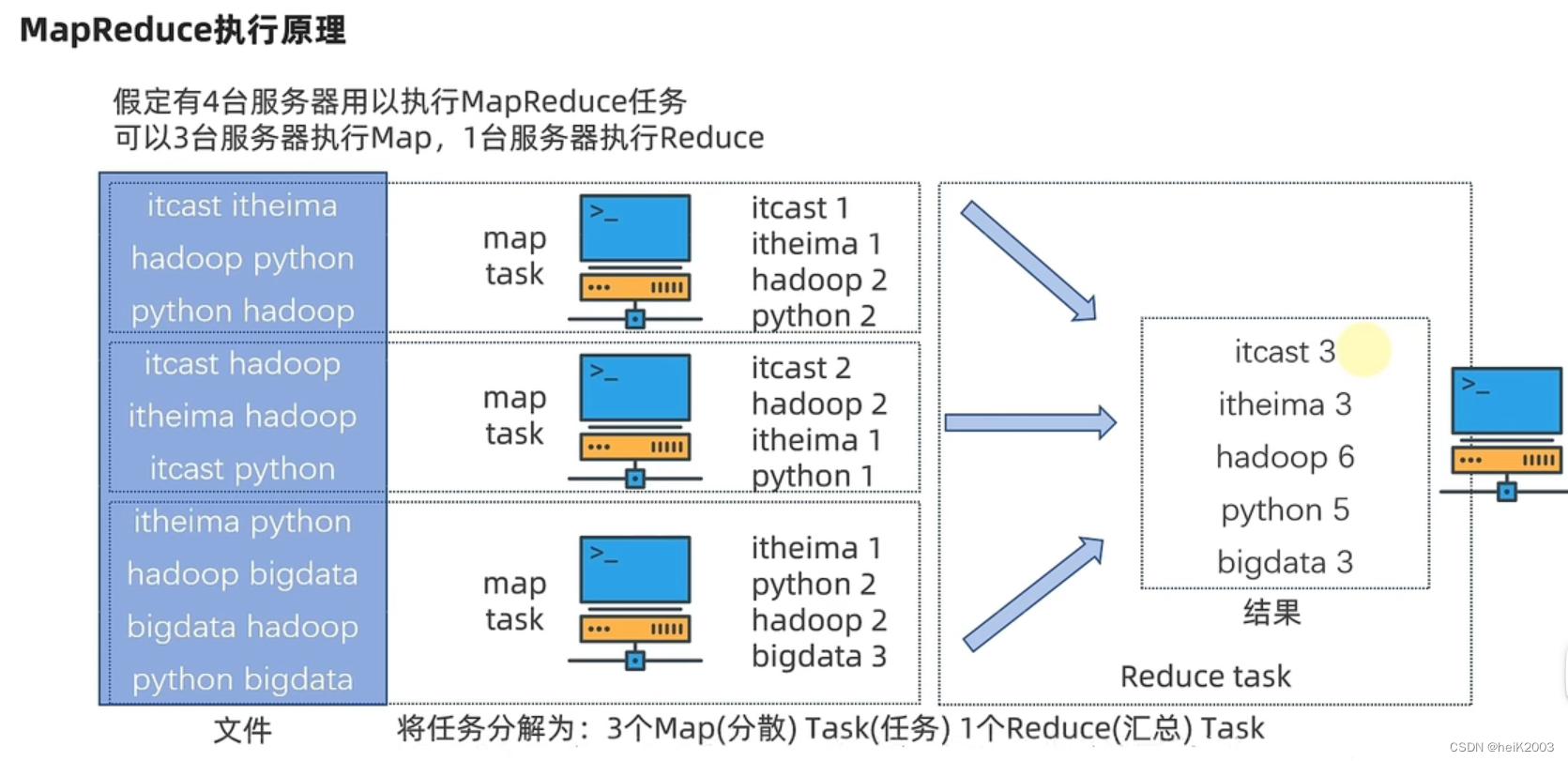
3、MapReduce的运行机制
· 将要执行的需求,分解为多个Map Task和Reduce Task
· 将Map Task 和 Reduce Task分配到对应的服务器去执行
YARN概述
1、YARN是做什么的?
· YARN是Hadoop的一个组件
· 用以做集群的资源(内存、CPU等)调度
2、为什么需要资源调度
· 将资源统一管控进行分配可以提高资源利用率
3、程序如何在YARN内运行
· 程序向YARN申请所需资源
· YARN为程序分配所需资源供程序使用
4、MapReduce和YARN的关系
· YARN用来调度资源给MapReduce分配和管理运行资源
· 所以,MapReduce需要YARN才能执行(普遍情况)
YARN的核心架构
1、YARN的架构有哪2个角色?
· 主(Master ):ResourceManager
· 从(Slave): NodeManager
2、两个角色各自的功能是什么?
· ResourceManager:管理、统筹并分配整个集群的资源
· NodeManager︰管理、分配单个服务器的资源,即创建管理容器,由容器提供资源供程序使用
3、什么是YARN的容器?
· 容器(Container)是YARN的NodeManager在所属服务器上分配资源的手段
· 创建一个资源容器,即由NodeManager占用这部分资源
· 然后应用程序运行在NodeManager创建的这个容器内
· 应用程序无法突破容器的资源限制
YARN的辅助架构角色
YARN的架构有哪些角色
· 核心角色:ResourceManager和NodeManager
· 辅助角色:ProxyServer,保障WEB UI访问的安全性
· 辅助角色:JobHistoryServer,记录历史程序运行信息和日志
YARN集群的启停命令
1、 一键启停脚本可用
· $HADOOP_HOME/sbin/start-yarn.sh
· $HADOOP_HOME/sbin/stop-yarn.sh
2、独立进程启停可用
· $HADOOP_HOME/bin/yarn --daemon
控制resourcemanager、nodemanager、proxyserver
· $HADOOP_HOME/bin/mapred --daemon(路径为/export/server/hadoop/etc/hadoop)
控制historyserver
提交MapReduce任务到YARN上执行
1、 Hadoop自带的MapReduce示例程序的代码jar包是
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar
2、使用什么命令提交MapReduce程序到YARN中执行?
hadoop jar 命令
语法:hadoop jar 程序文件 java类名 [程序参数] ... [程序参数]
例:hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount hdfs://node1:8020/input/ hdfs://node1:8020/output/wc
注:大数据中一般输入的为一个文件夹,输出到的文件必须不存在
3. 如何查看程序运行状态
· 在YARN WEB页面中查看
第四章
Apache Hive概述
1、 什么是分布式SQL计算?
以分布式的形式,执行SQL语句,进行数据统计分析。
2、Apache Hive是做什么的?
将SQL语句翻译成MapReduce程序,从而提供用户分布式SQL计算的能力。
· 传统MapReduce开发:写MapReduce代码 --> 得到结果
· 使用Hive开发:写SQL --> 得到结果
· 底层都是MapReduce在运行,但是使用层面上更加简单了
如何模拟实现Hive功能
基于MapReduce构建分布式SQL执行引擎,主要需要有哪些功能组件?
· 元数据管理
· SQL解析器
Hive基础架构
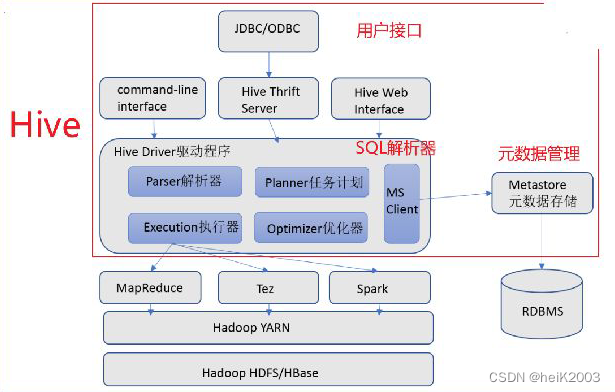
Hive的核心架构包含哪些?
· 元数据管理,称之为Metastore服务
· SQL解析器(Driver驱动程序),完成SQL解析、执行优化、代码提交等功能
· 用户接口:提供用户和Hive交互的功能
Hive的部署
部署Hive的主要流程:
· 部署MySQL数据库,并配置root账户密码
· 下载Hive上传并解压和设置软链接
· 下载MySQL 驱动jar包放入Hive的lib目录内
· 修改配置文件(hive-env.sh和hive-site.xml)
· 初始化元数据库(bin/schematool -initSchema -dbType mysql -verbos)
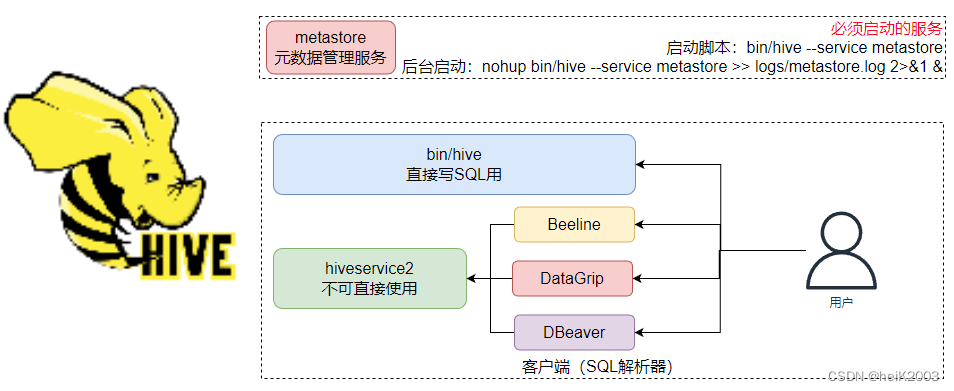
· 启动hive的metastore服务:
· 前台启动:bin/hive --service metastore
· 后台启动:nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
· 启动hive命令行:bin/hive
Hive初使用
1、Hive中可以使用类MySQL的SQL语法完成基本的库、表、插入、查询等操作
2、通过YARN控制台可以看到,Hive是将SQL翻译成MapReduce程序运行在YARN中
3、Hive中创建的库和表的数据,存储在HDFS中,默认存放:hdfs://node1:8020/user/hive/warehouse中。
HiveServer2 & Beeline
Hive有哪些客户端可以使用
· 执行:bin/hive,这是Hive提供的Shell环境,可以直接写SQL执行
· 启动HiveServer2,bin/hive --service hiveserver2
后台执行脚本:nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
(metastore开启路径为/export/server/hive)
这是Hive的Thrift服务,对外提供接口(默认端口10000)可供其它客户端链接,如:bin/beeline(内置)、DataGrip(第三方)、DBeaver(第三方)
第五章
Hive数据库操作语法
1、创建库的语法为
CREATE DATABASE [IF NOT EXISTS] db_name [LOCATION position];
2、删除库的语法为
DROP DATABASE db_name [CASCADE];
3、数据库和HDFS的关系
· Hive的库在HDFS上就是一个以.db结尾的目录
· 默认存储在:/user/hive/warehouse内
· 可以通过LOCATION关键字在创建的时候指定存储目录
4、基于语法描述说明
· [],表示可选,可写可不写
· |,表示或
· ...,表示序列,即未完结
· (),表示必填
内部表
1、内部表和外部表的区别

2、Hive的字段分隔符
· 默认是特殊字符:‘\001’
· 可以通过row format delimited fields terminated by在创建表的时候修改
3、删除内部表,表信息以及表数据全部都被删除
外部表
1、创建外部表语法:
· CREATE EXTERNAL TABLE ......
· 必须使用row format delimited fields terminated by指定列分隔符
· 必须使用LOCATION指定数据路径
2、外部表和其数据,是相互独立的,即:
· 可以先有表后有数据
· 也可以先有数据,后有表
· 表和数据只是一个链接关系
· 所以删除表,表不存在了但数据保留
3、内外部表转换
· 查看表类型:desc formatted stu;(查看Table Type属性的值,MANAGED_TABLE为内部表)
· 内转外:stu set tblproperties('EXTERNAL'='TRUE')
· 外转内:stu set tblproperties('EXTERNAL'='FALSE')
数据的导入和导出
1、数据导入
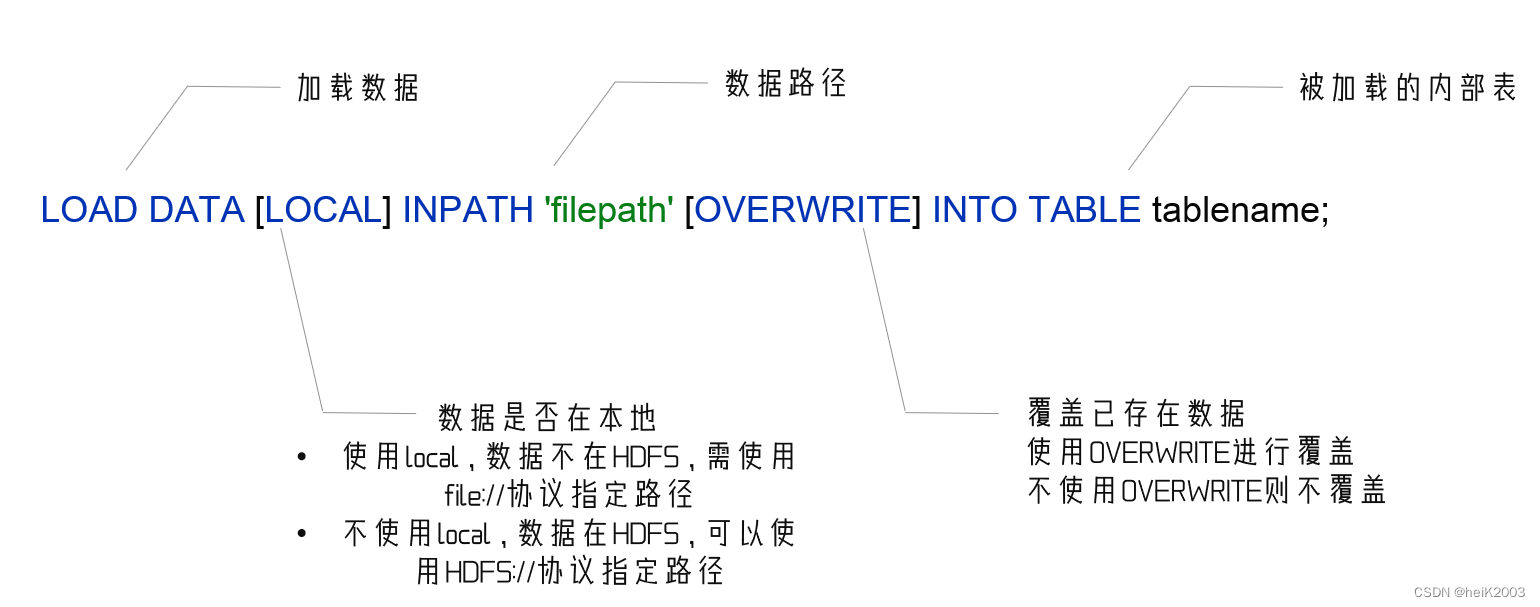
方法1:
从文件向表加载数据
load data [local] inpath 'path' [overwrite] into table tablename;
· 如果数据在hdfs中,那么源文件会消失(本质是mv的移动)
· 如果数据在本地,需要写local,如果是hdfs就不用写
· 这个加载方式不会走MapReduce,小文件加载速度快
方法2:
从表向其它表加载数据
insert [into | overwrite] table tablename select ...;
数据加载两种如何选择:
· 数据在本地:
· 推荐 load data local加载
· 数据在HDFS:
· 如果不保留原始文件:推荐使用LOAD方式直接加载
· 如果保留原始文件:推荐使用外部表先关联数据,然后通过INSERT SELECT 外部表的形式加载数据
· 数据已经在表中:
· 只可以INSERT SELECT
2、数据导出
方法1:
通过insert overwrite语句
insert overwrite [local] directory 'path' select ...;
· 有local表示写入本地
· 无local表示写入hdfs
方法2:
bin/hive -e "sql语句" > result.txt
· -e 直接执行sql语句,将结果通过Linux的重定向符号写入指定文件中
bin/hive -f "sql脚本文件“ > result.txt
· -f 直接执行sql脚本文件,将结果通过Linux的重定向符号写入指定文件中
分区表
1、什么是分区表?
· 可以选择字段作为表分区
· 分区其实就是HDFS上的不同文件夹
· 分区表可以极大的提高特定场景下Hive的操作性能
2、分区表的语法
· create table tablename(...) partitioned by (分区列 列类型,...) row format delimited fields terminated by ' ';
· 分区表的分区列,在partitioned by 中定义,不在普通列中定义
分桶表
1、什么是分桶表
· 可以选择字段作为分桶字段
· 分桶表本质上是数据分开在不同的文件中
· 分区和分桶可以同时使用
2、分桶表的语法
· 通过clustered by(...) into 3 buckets
· clustered by指定分桶字段
· into num buckets指定分桶数量
3、为什么需要用insert select的方式插入分桶表数据
· 需要insert select触发MapReduce进行hash取模计算,来基于分桶列的值,确定哪一条数据进入到哪一个桶文件中(不能用load data导入数据,因为load data不会触发MapReduce)
4、什么是Hash取模?
· 基于Hash算法,对值进行计算,同一个值得到同样的结果
· 对结果进行取模(除以桶数量得到余数),确认当前数据应该去哪一个桶文件
· 同样key(分桶列的值)的数据,会在同一个桶中
5、分桶表能带来什么性能提升?
在基于分桶列做操作的前提下
· 单值过滤
· JOIN
· GROUP BY
修改表操作
1、表重命名
alter table old_name rename to new_name;
2、修改表属性值
alter table table_name set tblproperties(property_name=property_value, ...)
如:alter table table_name set tblproperties('EXTERNAL'='TRUE'); 修改内部表属性为外部表
alter table table_name set tblproperties('comment'=new_comment); 修改表注释
3、添加表分区
alter table tablename add partition(year='2003',month='4',day='22');
新分区是没有数据的,需要手动添加或上传数据文件
4、修改分区值
alter table tablename partition(month='1') rename to partition(month='4');
修改元数据记录,HDFS的实体文件夹不会改名,但在元数据记录中是改名了的
5、删除分区
alter table tablename drop partition(year='2003',month='4',day='22');
6、添加列
alter table tablename add columns(v1 int, v2 string);
7、修改列名
alter table tablename change v1 v1new int;
列的属性不要修改,不然会报错
8、删除表
drop table tablename;
9、清空表
truncate table tablename;
无法清空外部表
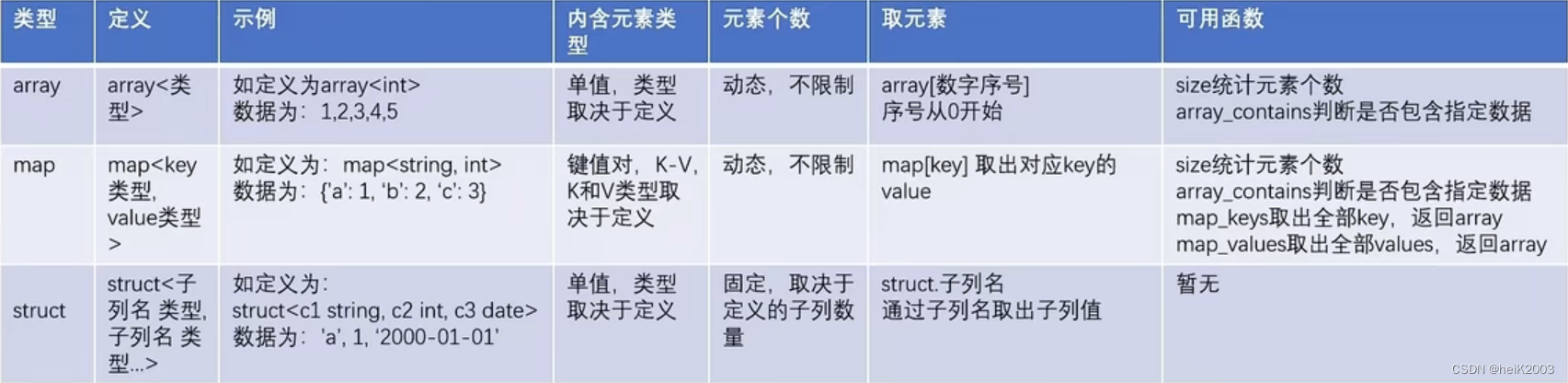
复杂类型array数组
1、array类型,主要存储:数组格式
保存一堆同类型的元素,如:1,2,3,4,5
2、定义格式
· array<类型>
· 数组元素之间的分隔符:collection items terminated by '分隔符'
3、在查询中使用
· 数组[数字序号],可以取出指定需要的元素(从0开始)
· size(数组),可以统计数组元素的个数
· array_contains(数组名, 数据),可以查看指定数据是否在数组中存在
复杂类型map映射
1、map类型,主要存储:K-V键值对类型数据
保存一堆同类型的键值对,如:"a": 1, "b": 2, "c" : 3
2、定义格式:
· map<key类型, value类型>
· 不同键值对之间:COLLECTION ITEMS TERMINATED BY '分隔符' 分隔
· 一个键值对内,使用:MAP KEYS TERMINATED BY '分隔符‘ 分隔K-V
如:father:xiaoming#mother:xiaohuang#brother:xiaogou
不同的KV之间使用#分隔,同一个KV内用:分隔K和V
3、在查询中使用
· map[key]来获取指定key的值
· map_keys(map)取到全部的key作为array返回,map_values(map)取到全部values
· size(map)可以统计K-V对的个数
· array_contains(map_values(map),数据)可以统计map是否包含指定数据
复杂类型struct结构
1、struct类型,主要存储:复合格式
可以包含多个二级列,二级列支持列名和类型,如
“a" : 1, "b" : "foo", "c" : "2003-04-22"
2、定义格式:
· struct<name:string, age:int>
· struct的分隔符只需要:COLLECTION ITEMS TERMINATED BY ‘分隔符’ 只需要分隔数据即可(数据中不记录key,key是建表定义的固定的)
3、在查询中使用
· struct.key即可取得对应的value
array、map、struct总结
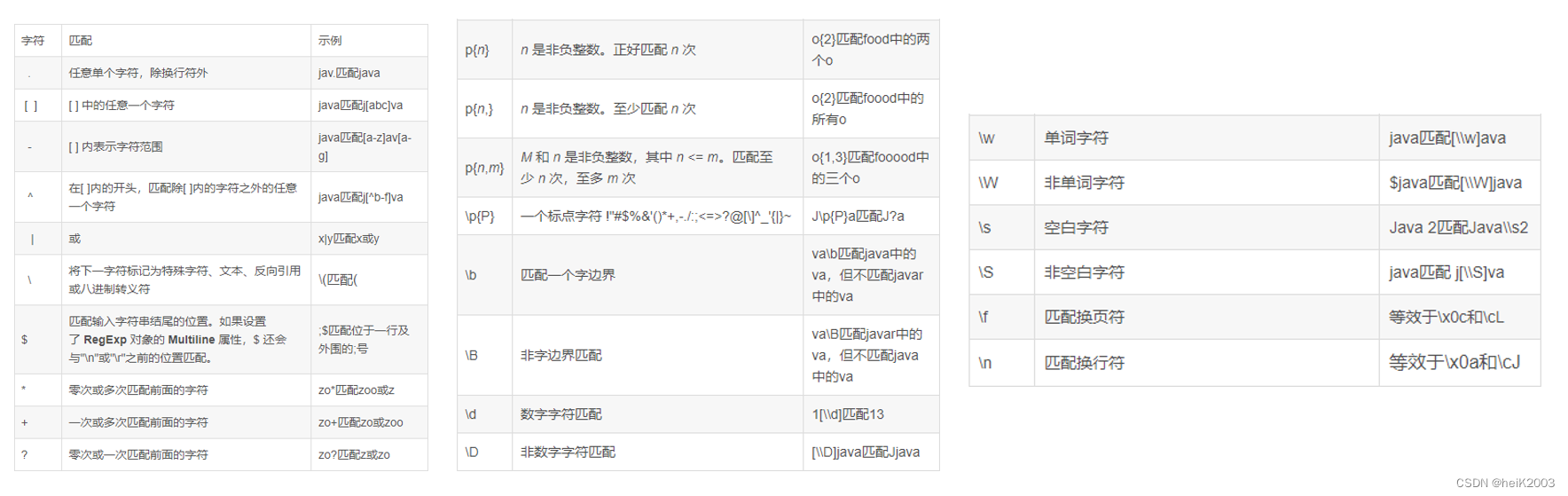
RLIKE正则匹配
1、什么是正则表达式
正则表达式就是一种规则的集合,通过特定的规则字符来匹配字符串是否满足规则的描述
2、RLIKE的作用
可以基于正则表达式,对数据内容进行匹配
UNION联合查询
1、UNION关键字的作用是?
· 将多个SELECT的结果集合并成一个
· 多个SELECT的结果集需要架构一致,否则无法合并
· 自带去重效果,如果无需去重,需要使用UNION ALL
2、UNION用在何处
· 可以用在任何需要SELECT发挥的地方(包括子查询、INSERT SELECT等)
数据抽样
1、为什么需要抽样?
大数据体系下,表内容一般偏大,小操作也要很久
所以如果想要简单看看数据,可以通过抽样快速查看
2、TABLESAMPLE函数的使用
· 桶抽样方式,TABLESAMPLE(BUCKET x OUT OF y ON(colname l rand())),推荐,完全随机,速度略慢块抽样,使用分桶表可以加速。从y个桶中抽取第x个桶,colname固定不变。
· 块抽样方式,TABLESAMPLE(num Rows | num PERCENT | num(K|N|G))
速度快于桶抽样方式,但不随机,只是按照数据顺序从前向后取。
虚拟列
1、什么是虚拟列,有哪些虚拟列?
虚拟列是Hive内置的可以在查询语句中使用的特殊标记,可以查询数据本身的详细参数。
· INPUT__FILE__NAME,显示数据行所在的具体文件
· BLOCK__OFFSET__INSIDE_FILE,显示数据行所在文件的偏移量
· ROW__OFFSET__INSIDE_BLOCK,显示数据所在HDFS块的偏移量(此虚拟列需要设置:SET hive.exec.rowoffset=true 才可使用)
2、虚拟列的作用
· 查看行级别的数据详细参数
· 可以用于WHERE、GROUP BY等各类统计计算中
· 可以协助进行错误排查工作
函数
Hive的函数分为两大类,内置函数和用户定义函数
· 内置函数
· 数值函数
· 集合函数
· 类型转换函数
· 日期函数
· 条件函数
· 字符串函数
· 数据脱敏函数
· 其它函数
· 用户定义函数


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









