




 本文围绕基于图神经网络的联合社交推荐展开,介绍了模型中梯度和embedding的聚合方式,阐述了论文使用的数据集,分析了LeakyRelu激活函数。还对论文创新点结合代码说明,如动态差分隐私、伪项目标签技术,最后提及论文实验选取的损失函数参数。
本文围绕基于图神经网络的联合社交推荐展开,介绍了模型中梯度和embedding的聚合方式,阐述了论文使用的数据集,分析了LeakyRelu激活函数。还对论文创新点结合代码说明,如动态差分隐私、伪项目标签技术,最后提及论文实验选取的损失函数参数。
基于图神经网络的联合社交推荐
模型中梯度和embedding的聚合
在FeSog中,Server端维护一个整体的model,由于这里的model层网络和GraphAttentionLayer层网络中一共有10个要更新参数,所以当每次server端将当前的model分发到各个user后,各个user利用本地的的评分数据来获得要更新的梯度,然后加到整体的梯度里面,这个梯度也有一个权重,那就是user交互的所有的项目的数量。利用这个来实现聚合每个客户端对于整体server端梯度的更新。
对于embedding的聚合则是server端维护一个大的item_embedding和user_embedding,item_embedding的向量维度是 1957 × 8 1957 \times 8 1957×8,user_embedding的向量维度是 874 × 8 874 \times 8 874×8。
embedding分发到各个user端之后,user端会先取出于当前的用户有关的社交关系和有关的项目相关的嵌入向量。
def user_embedding(self, embedding):
return embedding[torch.tensor(self.neighbors)], embedding[torch.tensor(self.id_self)]
def item_embedding(self, embedding):
return embedding[torch.tensor(self.items)]
最后返回给server端的数据更新也只是基于user
端自己拥有的那些数据相应的用户和项目的embedding的更新。
当你创建一个PyTorch实例并调用它的方法时,你传递的参数实际上是传给了模型内部的forward函数。这是因为在pytorch中,当你调用一个模型实例,实际上是在调用它的forward方法。
对于GraphAttentionLayer中的代码解释
尤其是这里使用了注意力机制,通过对代码详细分析解释什么是注意力机制。
def forward(self, h, adj):
W_h = torch.matmul(h, self.W)
print(h,W_h,self.W)
W_adj = torch.mm(adj, self.W)
a_input = torch.cat((W_h.repeat(W_adj.shape[0], 1), W_adj), dim = 1)
attention = self.leakyrelu(torch.matmul(a_input, self.a)).squeeze(-1)
attention = F.softmax(attention, dim = -1)
W_adj_transform = torch.mm(adj, self.W_1)
h = torch.matmul(attention, W_adj_transform)
return h
这里在model.py中传给forward的参数是
f_n = self.GAT_neighbor(feature_self, feature_neighbor)
f_i = self.GAT_item(feature_self, feature_item)
我们以feature_self和feature_neighbor为例分析
W_h = torch.matmul(h, self.W)
这里第一步对h进行一个线性变换,变换后的矩阵和原矩阵有相同的形状。
进行线性变换的目的是在一个新的坐标系统中,数据的某些性质(比如类别间的区分度)能够被模型更容易地识别和学习。



W_adj = torch.mm(adj, self.W)
这行代码和前面的道理是一致的。
a_input = torch.cat((W_h.repeat(W_adj.shape[0], 1), W_adj), dim = 1)
attention = self.leakyrelu(torch.matmul(a_input, self.a)).squeeze(-1)
attention = F.softmax(attention, dim = -1)
这里W_h.repeat是为了让W_h按照行多复制几遍,让每一行W_h和W_adj能按行横向拼接起来,横向拼接起来这个向量对可以代表一个user-user或者user-item对。接着下面attention代码可以对每一个向量对分配不同的权重,最终attention对的向量形式应该是(m*1)其中m是有多少个这样的向量对。然后使用非线性激活函数self.leakyrelu非线性激活函数处理这些注意力分数并帮助稳定梯度下降过程。接下来,使用 softmax 函数对这些分数进行标准化,确保所有注意力系数加起来等于 1。这样,每个分数就变成了一个概率值,代表相应节点对的相对重要性。最后将注意力分数和W_adj_transform相乘来对邻居或者项目的特征向量进行加权得到一个新的特征向量。


图神经网络中节点用向量可以表示,边也可以用向量表示。
if type(feature_item) == torch.Tensor:
f_n = self.GAT_neighbor(feature_self, feature_neighbor)
f_i = self.GAT_item(feature_self, feature_item)
e_n = torch.matmul(self.c, torch.cat((f_n, self.relation_neighbor)))
e_i = torch.matmul(self.c, torch.cat((f_i, self.relation_item)))
e_s = torch.matmul(self.c, torch.cat((feature_self, self.relation_self)))
m = nn.Softmax(dim = -1)
e_tensor = torch.stack([e_n, e_i, e_s])
e_tensor = m(e_tensor)
r_n, r_i, r_s = e_tensor
user_embedding = r_s * feature_self + r_n * f_n + r_i * f_i
下面这三行代码
e_n = torch.matmul(self.c, torch.cat((f_n, self.relation_neighbor)))
e_i = torch.matmul(self.c, torch.cat((f_i, self.relation_item)))
e_s = torch.matmul(self.c, torch.cat((feature_self, self.relation_self)))
这3个代码考虑了用户的节点特征和用户和节点之间的关系特征。

这里的torch.matmul()执行向量的点积计算出来的e_n,e_i,e_s。这是哪个值分别表示了用户-邻居,用户-项目,用户-自身三种关系的重要程度。

每种关系的重要程度是不同的。

在FeSog这个模型框架中,存在两种注意力机制,一种是计算每种关系中具体哪个用户对哪个邻居或者哪个用户对哪个项目更重要的注意力,还有一种是用户与用户的关系,用户与项目的关系,以及用户自身的关系这三种关系哪个对于求解最后的向量表示更重要的注意力关系。

推荐系统中节点自身到自身的连接表示什么?

论文中使用的数据集介绍
论文一共使用了ciao,epinions,filmtrust三个数据集。
filmtrust数据集中有以下几个关系。
train_data,valid_data,test_data,user_id_list,item_id_list,social。
其中train_data,valid_data,test_data三者是含有874个元素的字典。其中每个字典的键是用户的id,每一个键对应一个三元组,三元组第一位表示item编号,第二位表示user对item的rate分数。第三位没啥用。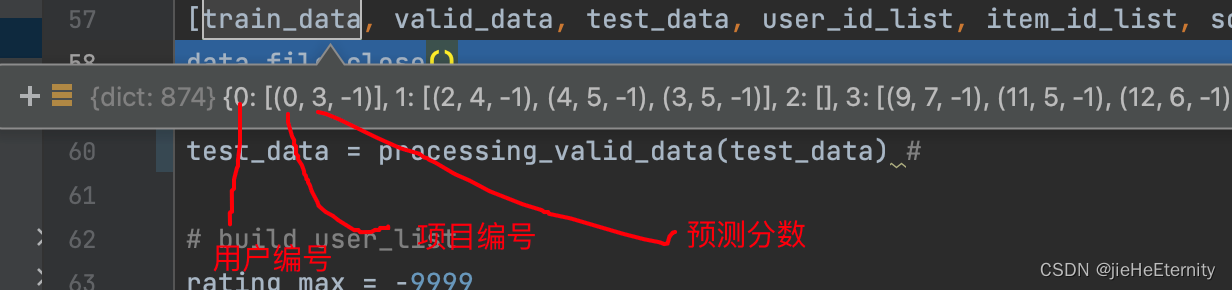
film数据集中有
- 1957个item
- 874个user
user_id_list中有874个user编号,item_id_list有1957个item编号。
social中是每个用户的社交关系。
rating的评分是1到8,1表示最不喜欢,8表示最喜欢。

epinions数据集中有18069个Users,有261246个Items,有762938个社交关系。其中数据的组织形式和前面介绍的Filmtrust数据集差不多,都包含6个组成部分。
Ciao数据集中有7317个Users,有104975个Items,包含了283320个打分。
这两个数据集
LeakyRelu激活函数
LeakyReLU(Leaky Rectified Linear Unit)是ReLU(Rectified Linear Unit)激活函数的一个变种,用于解决ReLU激活函数中的所谓“死神经元”问题。以下是LeakyReLU的主要特点和工作原理。


论文分析
FeSoG的提出的三个主要创新来解决的三个主要问题
- 数据的异构性
- 本地GNN的关系注意力和聚合区分了社交邻居和项目邻居
- 本地建模的个性化要求
- 本地用户嵌入推理为客户端保留个性化信息
- 通信的隐私保护
- 伪项标记以及动态LDP技术保护梯度
代码分析
Pytorch常用代码分析
model.eval():调用后,模型进入评估模式,在这个模式下,所有的训练特有的行为会被禁用。比如 Dropout 层会停止工作,即不会丢弃任何激活,而是会传递所有的输入.BatchNorm 层会使用在训练阶段计算得到的运行均值和方差来标准化数据,而不是当前批次的均值和方差。
评估模式的用途在于,当你需要进行模型验证、测试或实际预测时,你通常需要模型表现出稳定的行为,不受训练过程中某些随机性的影响。因此,eval() 模式确保了模型的前向传播是确定性的,并且某些层(如 Dropout 和 BatchNorm)的行为也是确定性的。
model.train():将模型设置为训练模式。在这种模式下,模型会正常更新权重,且某些层(如Dropout、BatchNorm等)会按照训练时的行为运行。model.eval():将模型设置为评估模式。在这种模式下,所有的训练特定层(如Dropout、BatchNorm等)会设置为评估状态,不会进行权重更新,也不会进行梯度计算。
clip=0.3表示梯度裁剪的阈值设定为0.3。梯度裁剪是一种针对梯度爆炸问题的常用技术,它通过设定一个阈值来限制梯度的最大值,保持梯度在一个合理的范围内。
具体到这个值(0.3):
- 当计算得到的梯度的绝对值超过0.3时,这些梯度将被缩放到不超过0.3。
- 梯度的方向保持不变,只是大小被限制在指定的范围内。
self.model = copy.deepcopy(global_model)这个代码可以生成global_model的深拷贝,这样修改新的model不会改变原来的model。否则,修改客户端的model会把服务器端的model也给修改了。
在PyTorch中,.detach() 方法被用于将一个变量从当前的计算图中分离出来。当你调用 .detach() 后,原变量所得到的新变量将不会在其上进行梯度计算,也就是说它不会在反向传播中被跟踪。这通常用于冻结某些层的参数或在评估模型时防止梯度计算。在代码 self.user_feature = user_feature.detach() 中,user_feature.detach() 创建了 user_feature 的一个副本,该副本与原计算图无关,这意味着对 self.user_feature 的任何操作都不会影响到原本的梯度计算。这样做通常是为了避免在反向传播时计算那些不应该或不需要计算梯度的变量。
torch.clone().detach()的含义
torch.clone(embedding_user).detach()首先创建embedding_user的一个副本,然后通过.detach()将其从当前计算图中分离出来,使得副本不会参与梯度计算。这样做通常是为了在执行操作时不影响原始Tensor的梯度。
torch.clone().detach()和copy.deepcopy()有什么区别?
copy.deepcopy()是Python标准库中的一个函数,它会递归地复制Python对象,包括对象内部嵌套的对象。在PyTorch中,copy.deepcopy()也可以用来复制一个模型或Tensor,但它不仅复制了数据还包括了Tensor的所有历史和计算图。如果对一个Tensor使用copy.deepcopy(),则得到的副本仍然会保留梯度计算的历史。
简而言之,torch.clone().detach()用于创建一个无梯度的Tensor副本,适用于PyTorch中的Tensor对象;copy.deepcopy()用于创建一个有梯度历史的深层副本,适用于包括PyTorch模型在内的任意Python对象。
share_memory_()是PyTorch中的一个函数,它用于将Tensor数据从共享内存中共享给其他进程。这对于多进程并行计算非常有用,可以提高数据传输的效率。通过使用share_memory_(),多个进程可以直接访问相同的Tensor数据,而无需进行数据的复制或传输。
self.model.parameters
在 PyTorch中,self.model.parameters() 是一个方法,用于获取模型self.model中所有的可训练参数。这个方法返回一个迭代器,遍历这个迭代器可以访问模型中定义的所有参数。这些参数通常包括神经网络层的权重和偏置等。以下是一些关键点:
直接使用print输出self.model.parameters()会输出一个封装对象,要想输出里面的内容,可以使用
print(list(self.model.parameters()))
在PyTorch中,要获取每个参数的名字,你可以使用 model.named_parameters() 方法,这将返回一个生成器,生成的每个元素都是参数的名字和对应的张量。
for name, param in self.model.named_parameters():
print(name, param.size())
self.model.named_parameters()中的参数数量是和model类中定义的需要被更新的参数数量一致。
以这个代码的model类为例:
model类里面有GraphAttentionLayer类的代码:
class model(nn.Module):
def __init__(self, embed_size):
super().__init__()
self.GAT_neighbor = GraphAttentionLayer(embed_size, embed_size)
self.GAT_item = GraphAttentionLayer(embed_size, embed_size)
self.relation_neighbor = nn.Parameter(torch.randn(embed_size))
self.relation_item = nn.Parameter(torch.randn(embed_size))
self.relation_self = nn.Parameter(torch.randn(embed_size))
self.c = nn.Parameter(torch.randn(2 * embed_size))
class GraphAttentionLayer(nn.Module):
def __init__(self, in_features, out_features, alpha = 0.1):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.alpha = alpha
self.W = nn.Parameter(torch.empty(size = (in_features, out_features)))
nn.init.xavier_uniform_(self.W.data)
self.a = nn.Parameter(torch.empty(size = (2 * out_features, 1)))
nn.init.xavier_uniform_(self.a.data)
self.W_1 = nn.Parameter(torch.randn(in_features, out_features))
self.leakyrelu = nn.LeakyReLU(self.alpha)
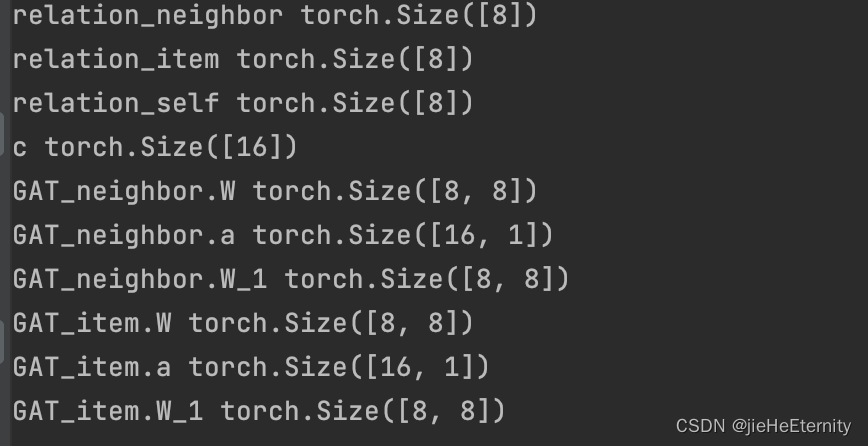
首先分析GraphAttentionLayer类里面有哪些训练参数(初始化定义为nn.paramameter的为训练参数):
self.W,self.a,self.W_1
self.GAT_item 和 self.GAT_neighbor每一个都有三个训练参数,两个有六个训练参数。
model类接着定义了self.relation_neighbor,self.relation_item,self.relation_self,self.c四个参数,所以self.model.named_parameters()里面一共有3*2+4=10个训练参数。
在pycharm的控制台中打印model.parameters()参可以验证一共有10个训练参数。
torch.matmul和torch.mm的区别


在PyTorch中,param.grad存储的是param的梯度消息,这些梯度消息用于优化param.data,即参数的实际值。
在PyTorch中,param是一个torch.nn.Parameter 对象,它是torch.Tensor的一个子类。因此,你可以调用所有适用于torch.Tensor的方法和属性。下面是一些常用的参数和方法:
param.data:访问数据
param.dtype:参数的数据类型
param.size()或者param.shape:参数的形状
param.grad:参数的梯度
param.requires_grad()一个参数值表示是否需要计算这个参数的梯度。
param.device参数所在的设备。
param.zero_()将参数中的所有元素置0
param.copy_()复制另一个张量的数据到这个参数中。
GAT.py
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import pdb
class GraphAttentionLayer(nn.Module):
def __init__(self, in_features, out_features, alpha = 0.1):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.alpha = alpha
self.W = nn.Parameter(torch.empty(size = (in_features, out_features)))
nn.init.xavier_uniform_(self.W.data)
self.a = nn.Parameter(torch.empty(size = (2 * out_features, 1)))
nn.init.xavier_uniform_(self.a.data)
self.W_1 = nn.Parameter(torch.randn(in_features, out_features))
self.leakyrelu = nn.LeakyReLU(self.alpha)
def forward(self, h, adj):
W_h = torch.matmul(h, self.W)
W_adj = torch.mm(adj, self.W)
a_input = torch.cat((W_h.repeat(W_adj.shape[0], 1), W_adj), dim = 1)
attention = self.leakyrelu(torch.matmul(a_input, self.a)).squeeze(-1)
attention = F.softmax(attention, dim = -1)
W_adj_transform = torch.mm(adj, self.W_1)
h = torch.matmul(attention, W_adj_transform)
return h
一步步解读GAT.py
首先,我们导入了必要的Python库:
numpy 是一个科学计算库。
torch 是PyTorch库,一个流行的深度学习库。
torch.nn 和 torch.nn.functional 是PyTorch中用于构建网络层的模块。
pdb 是Python的调试器。
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import pdb
定义了一个类 GraphAttentionLayer,它继承自 nn.Module,这是所有神经网络模块的基类。
class GraphAttentionLayer(nn.Module):
在类的初始化函数中,我们有三个参数:in_features 指输入特征的维数,out_features 指输出特征的维数,alpha 是用于LeakyReLU激活函数的负斜率。
def __init__(self, in_features, out_features, alpha = 0.1):
这里定义了一个权重矩阵 W 并用Xavier均匀初始化方法进行初始化。nn.Parameter 表示这是一个模型可学习的参数。
self.W = nn.Parameter(torch.empty(size = (in_features, out_features)))
nn.init.xavier_uniform_(self.W.data)`在这里插入代码片`
定义了另一个可学习的参数 a,它是用于计算注意力系数的向量,并且也使用Xavier均匀初始化。
self.a = nn.Parameter(torch.empty(size = (2 * out_features, 1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8155
8155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









