




 本文提出FedFast方法,通过ActvSAMP采样和ActvAGG聚合策略,加快联邦学习中推荐系统的训练速度,同时保持高推荐质量和用户隐私。文章关注训练过程优化,展示了在轻量级模型上的效果,预示未来在更多场景的应用潜力。
本文提出FedFast方法,通过ActvSAMP采样和ActvAGG聚合策略,加快联邦学习中推荐系统的训练速度,同时保持高推荐质量和用户隐私。文章关注训练过程优化,展示了在轻量级模型上的效果,预示未来在更多场景的应用潜力。
超越平均水平更快训练联邦推荐系统
论文试图解决什么问题
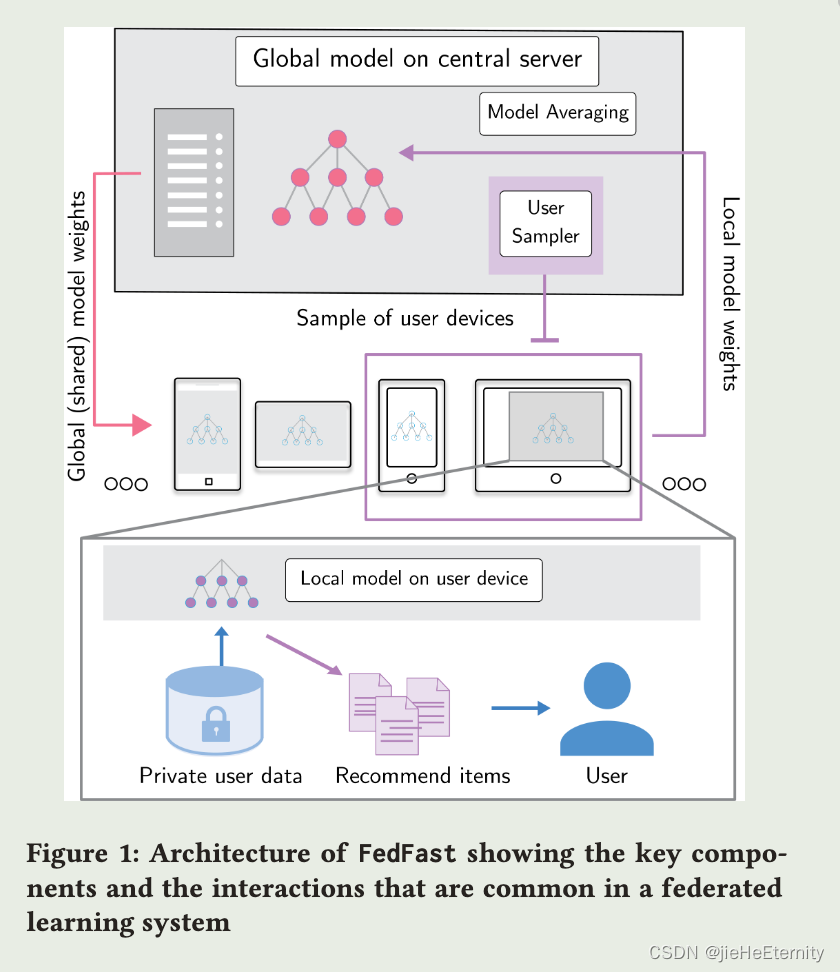
该论文试图解决在联邦学习中训练推荐系统的速度和准确性问题。在传统的推荐系统中,用户的个人数据需要上传到集中式服务器进行训练,存在隐私和数据安全的风险。而联邦学习通过在用户设备上本地训练和推理,避免了数据共享和隐私泄露的问题。然而,联邦学习中的训练过程可能会导致用户性能下降、通信负载增加和训练时间延长。因此,该论文旨在提出一种更高效的方法,以加快联邦学习中推荐系统模型的训练速度,使用户能够在训练过程完成之前就享受到更准确的推荐结果。
本文主要创新点
本文引入了两种新的技术:采样技术和聚合策略。首先是采样技术,本文使用了一种名为ActvSAMP的主动采样算法,通过将客户端分为不同的群集,并使用k-means算法进行聚类,从而形成具有代表性的采样集。每个群集中随机选择一个客户端,直到采样集中包含了所需数量的客户端。这样的采样方式可以反映领域中不同用户群体的特点。其次是聚合策略,本文使用了一种名为actvagg的聚合策略。该策略通过更新从属嵌入来改进模型的训练。对于每个群集,计算委派给该群集的代表的用户嵌入之间的差异的平均值。然后将这些平均差异乘以一个衰减因子,并添加到从属嵌入中。这样的聚合策略可以提高模型的训练速度和准确性。通过采样技术和聚合策略的结合,FedFast方法能够在
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1061
1061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









