







 本文深入解析MySQL的索引原理,包括主键索引、唯一索引、普通索引及复合索引,探讨索引结构(B+树和Hash)及其在查询优化中的应用。文章通过实例说明如何创建和管理索引,解释索引在InnoDB存储引擎中的工作方式,并解答常见疑问。
本文深入解析MySQL的索引原理,包括主键索引、唯一索引、普通索引及复合索引,探讨索引结构(B+树和Hash)及其在查询优化中的应用。文章通过实例说明如何创建和管理索引,解释索引在InnoDB存储引擎中的工作方式,并解答常见疑问。
.
最近看了林晓斌老师的mysql实战,看完后发现提笔忘字,特将自己感觉比较重要的知识记录一下,此文主要介绍了mysql的索引,默认为innodb存储引擎.如有错误,欢迎指正!
索引是一个以空间换时间的思想,虽然维护索引会有一定的开销,但是建立合适的索引可以帮助我们大大减少查询时间,此文仅为个人见解.不喜勿喷,欢迎交流!
1.1 索引分类
- 主键索引:primary key
- 唯一索引:unique
- 普通索引:index
- 复合索引(组合索引)
1.1.1 索引结构
索引结构有两种,一种是hash,一种是btree,默认为btree索引.
原因:
1.hash索引可以通过计算公式直接得到内存位置,因为查询效率极高,但是如果插入数据过多,会形成hash碰撞,会造成并不比btree结构查询快.
2.hash索引不支持范围查询
3.hash索引在组合索引中无效.
1.1.2 创建语句
1.1.2.1 建表时创建
ps:主键索引一般会在创建表时就指定.其他索引可以通过sql语句来进行创建.
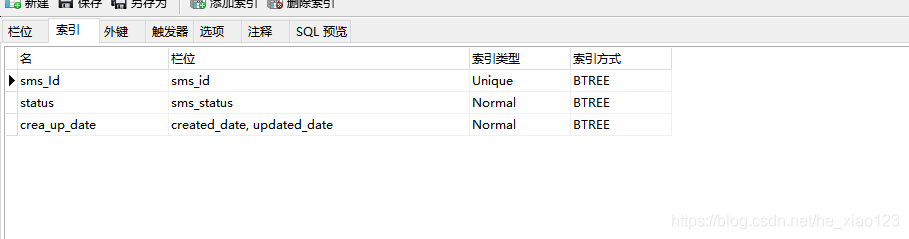
拿最近建的一张短信记录表来举例(这里索引名字,索引均为随意为之,只做示例)
create table t_sms_model
(
id int(11) not null auto_increment comment 'id',
business_type varchar(20) comment '业务类型(1.sms_001:进件校验手机号)',
channel_no varchar(50) not null comment '分配渠道号',
sms_id varchar(20) comment '短信模版id',
sms_content varchar(100) comment '短信内容',
sms_status varchar(2) comment '短信模版状态(1.正常,2.弃用)',
created_date timestamp default CURRENT_TIMESTAMP comment '创建时间',
updated_date timestamp default CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP comment '修改时间',
primary key (id),
-- 唯一索引
UNIQUE INDEX sms_Id (sms_id),
-- 普通索引
INDEX status (sms_status),
-- 组合索引
INDEX crea_up_date (created_date,updated_date)
);
alter table t_sms_model comment '短信模版表';
1.1.2.2 建表后创建:
ALTER TABLE 表名 ADD INDEX | KEY [索引名] (字段名1 [(长度)] )
如:ALTER TABLE sms_model ADD UNIQUE INDEX sms_Id (sms_id);
或者:
CREATE INDEX 索引名 ON 表名(字段名) ;
如:CREATE INDEX sms_Id on sms_model(sms_id);
1.1.2.3 索引查看和删除
- 查看索引:
如:show index from sms_model; - 删除索引:
如:drop index sms_Id on sms_model;
1.1.2 索引介绍
ps:在innodb存储引擎中,主键索引为聚簇索引,其他索引为非聚簇索引,称为二级索引,区别在于聚簇索引的叶子节点存储的是页(一页包含多个行数据),非聚簇索引的叶子节点存储的为主键索引的值(不存储地址值的主要原因是如果一但主键索引行的地址值改变,必须改变非主键索引的叶子节点,因为mysql舍弃了这种方式,而是通过在非主键索引上查询出主键索引的值,再去主键索引查询所需数据,这个过程叫做回表,而我们索引优化其中一部分就是通过复合索引/覆盖索引等来尽量减少回表次数来实现的).
引用一张林老师的图.
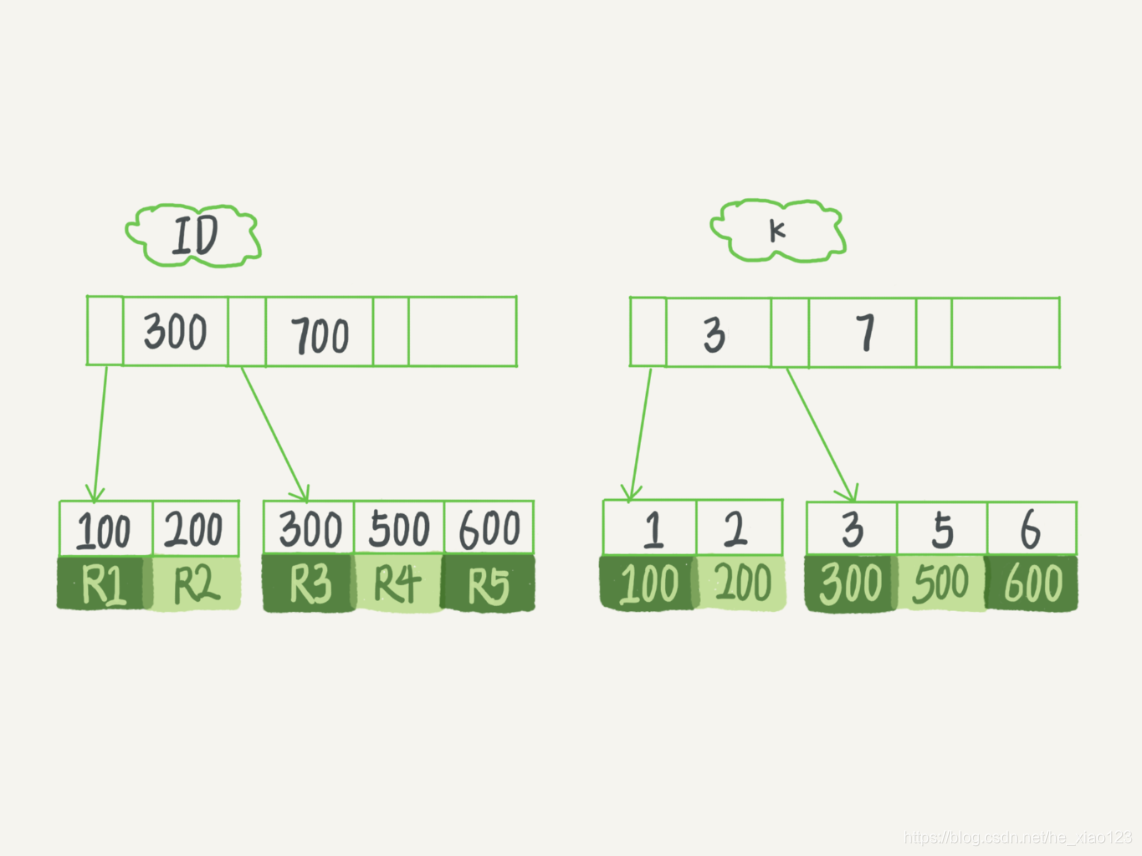
如上图,ID为主键索引,叶子节点存储的为R行值,k为普通索引,叶子节点存储的为主键id的值
知识点:
- 主键索引: 对于一个只有主键索引的表,mysql的存储形式为有序的b+tree(B+树)存储,其数据存储在主键的叶子节点
- 普通索引: 除了主键索引外的索引也是以有序的b+树形式存储的,但是其他索引的叶子节点存储的为主键索引的值.然后根据值返回主键索引树查询出所需数据.
- 回表: 通过非主键索引上主键索引的值去主键索引上查数据的操作称为回表
- 覆盖索引: 所需数据只通过索引树就可以取得,而不需要回表.这种称作覆盖索引.
- 复合索引: 一个好的复合索引应该考虑到最左原则和覆盖索引的情况.
查询的时候,如果我们以带索引的字段为条件,mysql会先扫描索引树,然后根据主键索引id回表取出要查询的值.
1.1.3 答疑
这里以短信记录表为例,我们只建立主键索引.假使现在我们这个短信模版表非常大.
drop table if exists t_sms_record;
/*==============================================================*/
/* Table: t_sms_record */
/*==============================================================*/
create table t_sms_record
(
id int(11) not null auto_increment comment 'id',
sms_id varchar(12) not null comment '短信模版id',
channel_no varchar(20) not null comment '科技输出合作银行标识',
code varchar(6) comment '验证码',
sms_content varchar(200) comment '短信内容',
phone_number varchar(11) comment '手机号码',
send_status varchar(2) comment '发送短信状态(T.成功,F.失败)',
created_date timestamp default CURRENT_TIMESTAMP comment '创建时间',
updated_date timestamp default CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP comment '修改时间',
primary key (id)
);
alter table t_sms_record comment '短信发送记录表';
-
select * 和select字段差别真的很大吗
答:对于select* 和select 列名(所有字段)来说查询差别会有差异,select* mysql会先Query Table Metadata For Columns查询出所有字段后,才会去查询.但是两者差异真的很小
结论:两者差别几乎可忽略。所以查询所有字段(或者大多数字段)的时候,大可select *来操作。如果某些不需要的字段数据量特别大,还是写清楚字段比较好,因为这样可以减少网络传输。 -
为什么尽量不创建唯一索引?
答:
1.在查询方面,两者差别微乎其微,如果表结构已经被加载进内存,因为不需要去磁盘寻址,都是从内存直接返回数据.如果表结构不在内存中,唯一索引和普通索引查询都是需要先将表结构数据读入内存,再根据条件查询,
2.但是对于更新和添加来说,如果数据在内存中,两者差别也很小,唯一索引需要多加一个判断,索引是否唯一,但是如果数据不在内存中,唯一索引需要做的需要先将表结构从磁盘读入内存,看是否与之前的索引有重复,然后才会进行操作,而普通索引可以直接将更新或者添加操作写入change buffer就可以直接返回成功了.会比唯一索引要快得多.
结论:在插入或者更新操作多得表尽量不使用唯一索引,但如果业务需要,那么就大胆用吧.

















 1356
1356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









