






前言:通过Rpc调上游接口,上游接口限制入参ids的个数(3个)并且调一次耗时大约1000毫秒,现在假如ids数量是10个,应该如何操作效率高耗时短
方案:循环单个处理、分组串行、分组并行
1. 上游接口
/**
* 上游接口:ids最多限制3个
*
* @param ids
* @return
*/
public static Set<String> getIdsStr(Set<String> ids) {
//业务逻辑、Rpc上游接口
Set<String> idSet = Sets.newHashSet();
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
for (String str : ids) {
String res = str + "-----" + str;
idSet.add(res);
System.out.println(Thread.currentThread().getName() + ":" +res);
}
System.out.println("通过id拼接的idStr:"+Thread.currentThread().getName() + ":" +idSet);
return idSet;
}
2. 方案
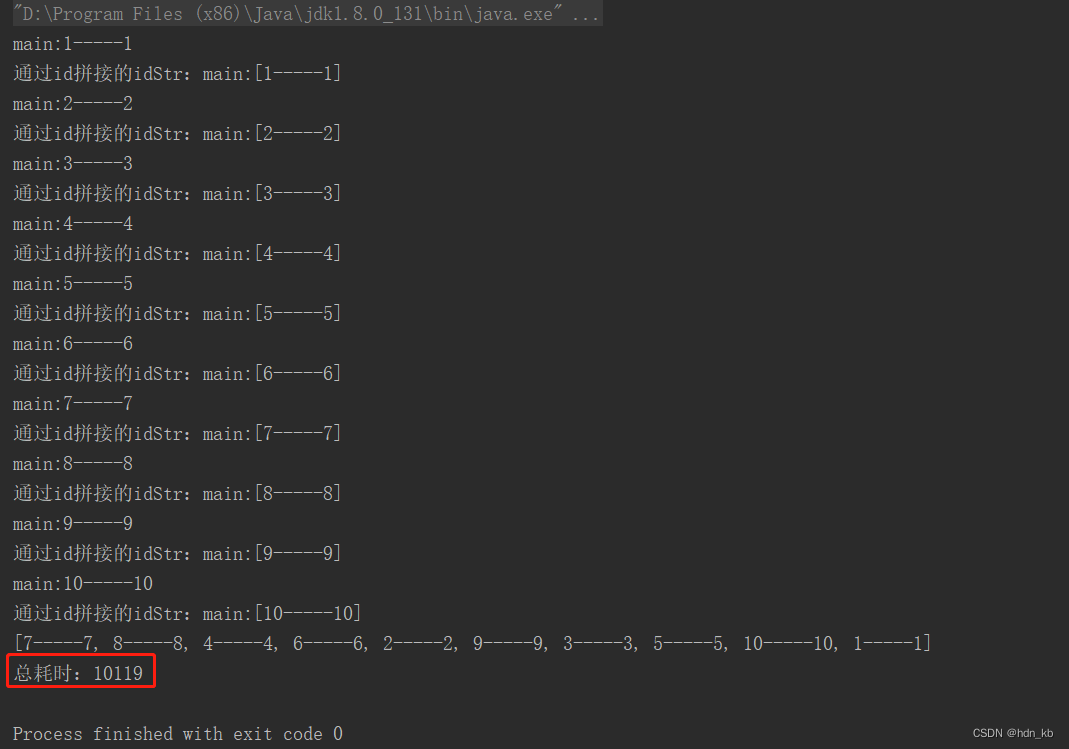
2.1. 循环单个处理
public static void main(String[] args) {
long start = System.currentTimeMillis();
Set<String> ids = new HashSet<>();
ids.add("1");
ids.add("2");
ids.add("3");
ids.add("4");
ids.add("5");
ids.add("6");
ids.add("7");
ids.add("8");
ids.add("9");
ids.add("10");
Set<String> resultSet = new HashSet<>(ids.size());
List<String> idList = new ArrayList<>();
idList.addAll(ids);
for (int i = 0; i < ids.size(); i++) {
Set<String> id = new HashSet<>();
id.add(idList.get(i));
resultSet.addAll(getIdsStr(id));
}
System.out.println(resultSet);
long end = System.currentTimeMillis();
long l = end - start;
System.out.println("总耗时:" + l);
}
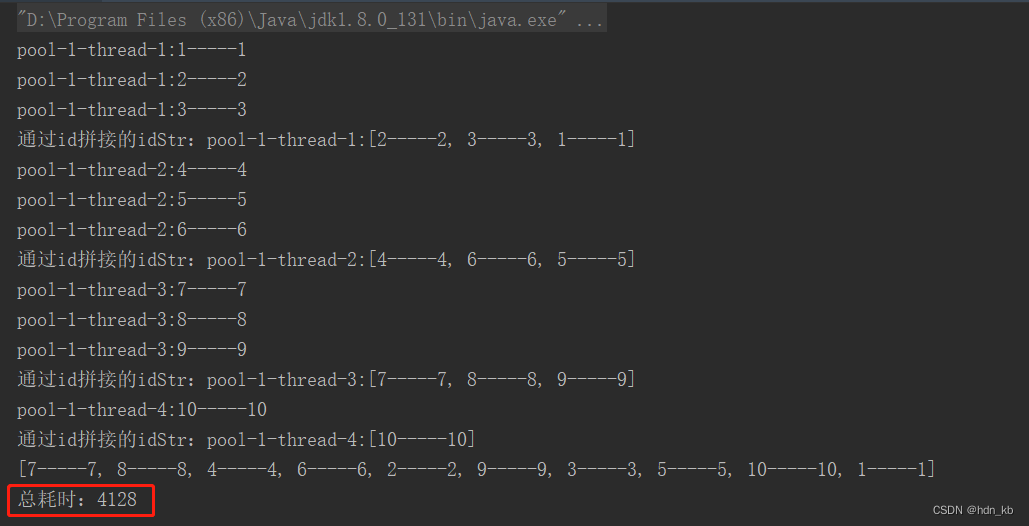
2.2. 分组串行
/**
* 按数量进行切割
*
* @param ids
* @param limit
* @return
*/
public static Map<String, Set<String>> splitSet(Set<String> ids, int limit) {
Map<String, Set<String>> map = Maps.newHashMap();
if (CollectionUtil.isEmpty(ids)) {
return map;
}
List<String> skuList = Lists.newArrayList(ids);
int i = 0;
while (skuList.size() > limit) {
List<String> subList = skuList.subList(0, limit);
map.put(String.valueOf(i), Sets.newHashSet(subList));
i++;
skuList.removeAll(subList);
}
if (CollectionUtil.isNotEmpty(skuList)) {
map.put(i + "", Sets.newHashSet(skuList));
}
return map;
}
public static void main(String[] args) {
long start = System.currentTimeMillis();
Set<String> ids = new HashSet<>();
ids.add("1");
ids.add("2");
ids.add("3");
ids.add("4");
ids.add("5");
ids.add("6");
ids.add("7");
ids.add("8");
ids.add("9");
ids.add("10");
Set<String> resultSet = new HashSet<>(ids.size());
ExecutorService threadPool =
new ThreadPoolExecutor(10, 100, 1, TimeUnit.SECONDS, new LinkedBlockingDeque<Runnable>(4),
new ThreadPoolExecutor.AbortPolicy());
Map<String, Set<String>> batchIdMap = splitSet(ids, 3);
for (String batch : batchIdMap.keySet()) {
Future<Set<String>> submit = threadPool.submit(() -> getIdsStr(batchIdMap.get(batch)));
try {
//future的get方法会阻塞:串行执行
Set<String> idSet = submit.get(5000L, TimeUnit.MILLISECONDS);
resultSet.addAll(idSet);
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println(resultSet);
long end = System.currentTimeMillis();
long l = end - start;
System.out.println("总耗时:" + l);
}
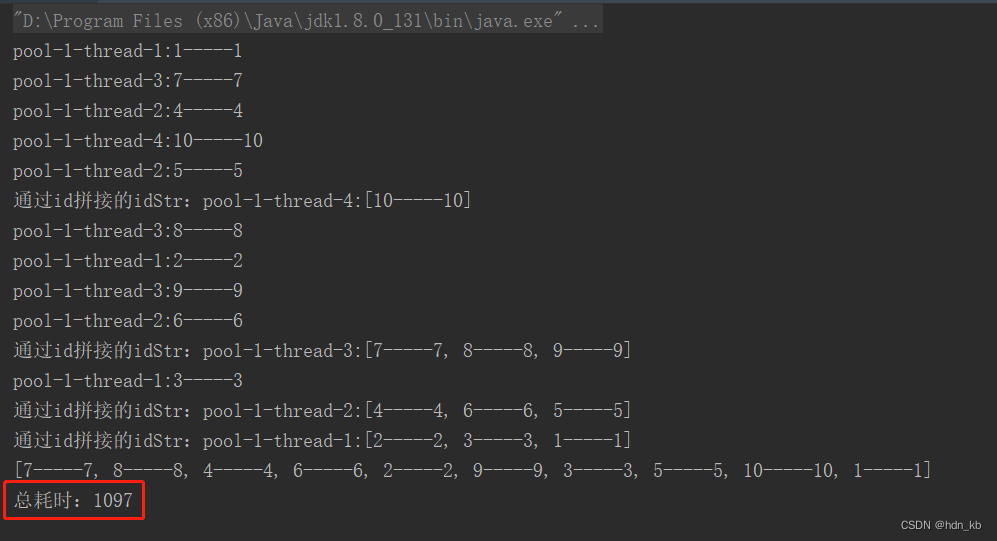
2.3. 分组并行
/**
* 按数量进行切割
*
* @param ids
* @param limit
* @return
*/
public static Map<String, Set<String>> splitSet(Set<String> ids, int limit) {
Map<String, Set<String>> map = Maps.newHashMap();
if (CollectionUtil.isEmpty(ids)) {
return map;
}
List<String> skuList = Lists.newArrayList(ids);
int i = 0;
while (skuList.size() > limit) {
List<String> subList = skuList.subList(0, limit);
map.put(String.valueOf(i), Sets.newHashSet(subList));
i++;
skuList.removeAll(subList);
}
if (CollectionUtil.isNotEmpty(skuList)) {
map.put(i + "", Sets.newHashSet(skuList));
}
return map;
}
public static void main(String[] args) {
long start = System.currentTimeMillis();
Set<String> ids = new HashSet<>();
ids.add("1");
ids.add("2");
ids.add("3");
ids.add("4");
ids.add("5");
ids.add("6");
ids.add("7");
ids.add("8");
ids.add("9");
ids.add("10");
Set<String> resultSet = new HashSet<>(ids.size());
ExecutorService threadPool =
new ThreadPoolExecutor(10, 100, 1, TimeUnit.SECONDS, new LinkedBlockingDeque<Runnable>(4),
new ThreadPoolExecutor.AbortPolicy());
Map<String, Set<String>> batchIdMap = splitSet(ids, 3);
Map<String, Future<Set<String>>> futureMap = Maps.newHashMap();
for (String batch : batchIdMap.keySet()) {
Future<Set<String>> submit = threadPool.submit(() -> getIdsStr(batchIdMap.get(batch)));
futureMap.put(batch,submit);
}
for (String batch : futureMap.keySet()){
try {
resultSet.addAll(futureMap.get(batch).get(5000L, TimeUnit.MILLISECONDS));
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println(resultSet);
long end = System.currentTimeMillis();
long l = end - start;
System.out.println("总耗时:" + l);
}
3、总结
从以上的耗时可以看出效率由高到低的是:分组并行、分组串行、循环单个处理

















 3179
3179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









