








NIPS2021
1 Introduction
文本属性图是一种广泛使用的数据格式。在文本属性图上的表示学习,就是根据节点文本以及邻居节点的文本信息来获得低维的 embedding。现在的做法有一种是讲预训练模型和 GNN 技术结合,即 PLM 去独立获取文本的 embedding,再使用 GNN 去聚合节点的信息。
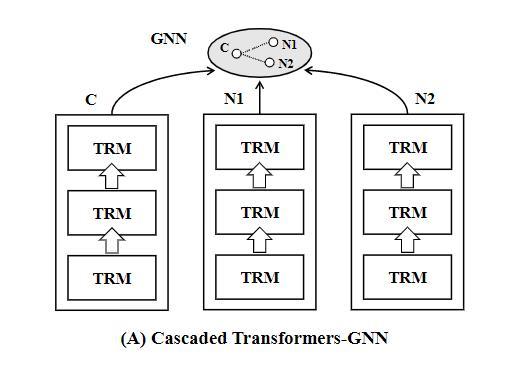
这种做法叫做 Transformer-GNN 级联做法,如 图 1 所示,也就是 Transformer 的组件是部署在 GNN 的组件的前面的。实际上,因为两者独立编码,缺乏了节点文本信息之间的交换。在一些语义上具备歧义的场景会产生没有完全理解全文的现象。例如,一个节点内文本”notes on Transformer“,一个与他连接的节点内文本”tutorials on machine translation“,所以此处的 Transformer 就不太可能是指变压器。
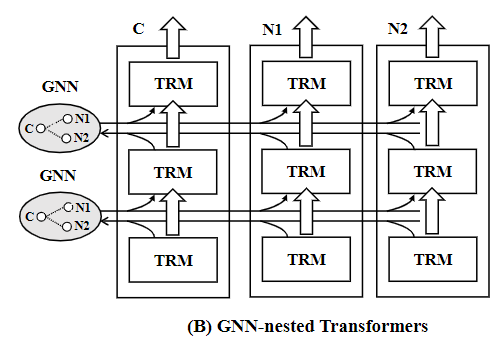
作者提出了新的架构,如图 2 所示,将 GNN 和 Transformer 嵌套,叫做 GraphFormer。文本编码和图信息聚合被融合为一个迭代工作流程。在每一次迭代过程中,相互连接的节点就会交换信息。下一层的 Transformer 就会在增强的节点特征上继续编码,和级联的架构相比,这种做法产生了节点之间的信息交换和增强,得到的节点 embedding 更具备表达力。
1.1 关于GraphFormer的训练
单个节点的信息饱满程度足够应对大多数都场景,即使不去聚合邻居节点的信息,也可以解决问题。如此以来,最终训练得到的 GNN 编码器会是缺乏”锻炼的“。受到课程学习(curriculum learning)的启发,作者在 GraphFormer 的训练上分为两个过程:
curriculum learning:模型的学习呈阶段性,从简单样本上学习,到从复杂样本上学习。
- 将原始数据的一部分经过人工污染,让 GNN 很难仅仅通过中心节点就做出准确预测,于是就会去学习利用周围的信息。
- 在未经人工污染的数据上,去拟和目标分布。
1.2 单向图注意(undirected graph attention)
因为所有连接的节点都是相互依赖的,所以如果有新的中心节点需要操作,无论他周围的节点有没有被处理过,都要从头再来。这样就产生了很多不需要的计算。本文采用了单向图注意来缓解这个问题。只有中心节点需要参考周围节点,而周围节点直接独立编码,于是已经编码过的邻居节点的结果可以重用。
2 GraphFormers
在文本图数据的表示中,节点 xxx 是一个文本,NxN_xNx 表示邻居,GxG_xGx 表示整个图,目标是通过 embedding 的相似度预测 xqx_qxq 和 xkx_kxk 是否存在链接。
2.1 GNN-nested Transformers
首先,中心节点和邻居节点被编码为一个 token 序列,前端带有 [cls],[cls] 表示的是一个节点的 embedding。基于词 embedding 和位置 embedding,输入序列被映射到初始 embedding 序列 {Hg0}G\{\mathrm{H}_g^0\}_G{Hg0}G 。embedding 序列由多个 GNN-nested Transformer 层编码而得。
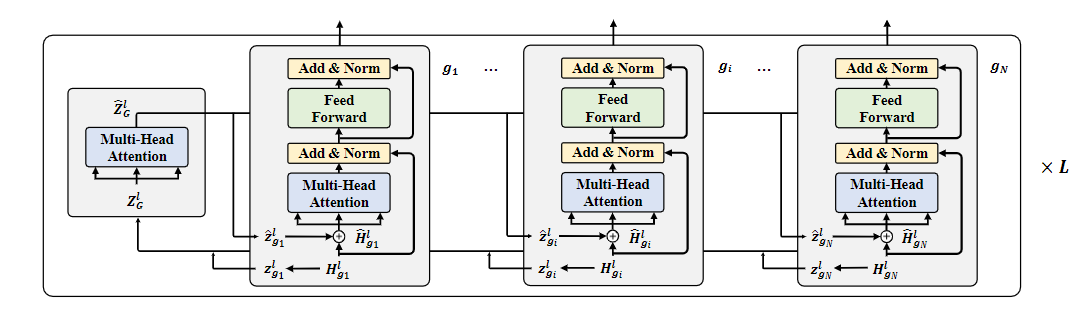
2.1.1 Graph Aggregation in GNN
如图第 lll 层为例,首先用 Transformer 编码出初始的 token 级的编码序列 {Hg0}\{\mathrm{H}_g^0\}{Hg0} ,每一个节点对应一个{Hgi0}\{\mathrm{H}_{g_i}^{0}\}{Hgi0} ,最开始,会直接将 token 级的 embedding 赋值给 node 级的 embedding,z^gl←Hgl\mathbf{\hat{z}}_g^l\leftarrow \mathbf{H}_g^lz^gl←Hgl ,node 级的 embedding 是由 GNN 聚合所有节点信息之后得到的。所有的z^gl\mathbf{\hat{z}}_g^lz^gl 组成了ZGl\boldsymbol{Z}_{G}^{l}ZGl ,作为多头注意力的输入,接下来和 GAT 的操作类似,得到 GAT 的编码:
Z^Gl=MHA(ZGl);
\hat{\mathbf{Z}}_G^l=\mathrm{MHA}(\mathbf{Z}_G^l);
Z^Gl=MHA(ZGl);
MHA(ZGl)=Concat(head1,...,headh); \mathrm{MHA(}\mathbf{Z}_{G}^{l})=\mathrm{Concat(}\mathbf{head}_1,...,\mathbf{head}_h); MHA(ZGl)=Concat(head1,...,headh);
headj=softmax(QKTd+B)V; \mathbf{head}_{j}=\mathrm{softmax}(\frac{\mathbf{QK}^{\mathrm{T}}}{\sqrt{d}}+\mathbf{B})\mathbf{V}; headj=softmax(dQKT+B)V;
Q=ZGlWjQ;K=ZGlWjK;V=ZGlWjV; \mathbf{Q}=\mathbf{Z}_G^l\mathbf{W}_j^Q; \mathbf{K}=\mathbf{Z}_G^l\mathbf{W}_j^K; \mathbf{V}=\mathbf{Z}_G^l\mathbf{W}_j^V; Q=ZGlWjQ;K=ZGlWjK;V=ZGlWjV;
公式 4 中有三个投影矩阵,对应的是第jjj 个注意力头。聚合信息之后的Z^Gl\hat{\mathbf{Z}}_G^lZ^Gl 里的每一个z^gl\mathbf{\hat{z}}_g^lz^gl 都会被分配到原来的节点上,并和自己 token 级的 embedding 做一个 concat 操作。
H^gl←Concat(z^gl,Hgl).
\widehat{\mathbf{H}}_g^l\leftarrow\mathrm{Concat}(\mathbf{\hat{z}}_g^l,\mathbf{H}_g^l).
Hgl←Concat(z^gl,Hgl).
2.1.2 Text Encoding in Transformer
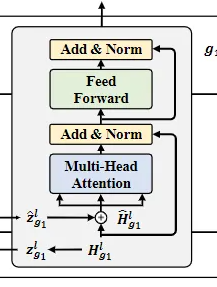
经过图聚合增强之后的 token 级的 embeddingH^gl\widehat{\mathbf{H}}_g^lHgl 接下来由 Transformer 组件处理,
H^gl=LN(Hgl+MHAasy(H^gl));
\hat{\mathbf{H}}_g^l=\mathrm{LN}(\mathbf{H}_g^l+\mathrm{MHA}^{asy}(\widehat{\mathbf{H}}_g^l));
H^gl=LN(Hgl+MHAasy(Hgl));
Hgl+1=LN(H^gl+MLP(H^gl)). \mathbf{H}_g^{l+1}=\mathrm{LN}(\widehat{\mathbf{H}}_g^l+\mathrm{MLP}(\widehat{\mathbf{H}}_g^l)). Hgl+1=LN(Hgl+MLP(Hgl)).
- 首先,H^gl\widehat{\mathbf{H}}_g^lHgl 经过一个非对称多头注意力层,并和原始的 token 编码作 add 并进行 Norm 操作
- 经过一个 MLP 投影之后再加上没投影之前的,和未投影的 token 编码作 add 并进行 Norm 操作
从而得到下一层的 token 级的输入Hgl+1\mathbf{H}_g^{l+1}Hgl+1 ,最后一层的输出zxL(i.e.,HgL[0])\mathbf{z}_{x}^{L} (\mathrm{i.e.},{\mathbf{H}}_{g}^{L}[0])zxL(i.e.,HgL[0]) 就是最终的节点表示。总的时间复杂度是O(M^2+MP2)O(\hat{M}^2+MP^2)O(M^2+MP2) ,分别是 GAT 和 Transformer 需要的时间,其中MMM 是节点数,PPP 是token 的数量
2.2 Undirected Graph Aggregation
之前提到了关于模型的一个问题:在编码过程中,输入节点相互依赖。因此,为了为节点生成嵌入,其邻域中的所有相关节点都需要从头开始编码,而不管它们是否之前已经处理过。
作者采用了一种叫做单向图聚合的做法简化了计算:只有中心节点需要考虑周围节点的信息,而作为邻居节点,则直接由文本编码赋值即可。
Hgl+1={TRMl(Hxl^),g=x;TRMl(Hgl),∀g∈Nx.
\mathbf{H}_g^{l+1}=\begin{cases}\mathrm{TRM}^l(\widehat{\mathbf{H}_x^l}), g=x;\\\mathrm{TRM}^l(\mathbf{H}_g^l), \forall g\in N_x.\end{cases}
Hgl+1={TRMl(Hxl),g=x;TRMl(Hgl),∀g∈Nx.
在框架中产生的节点的 node 级编码z^gl\mathbf{\hat{z}}_g^lz^gl 会被缓存,作为后续可能计算使用。
2.3 两阶段模型训练
2.3.1 训练目标
以链接预测作为训练任务,给定一个节点对qqq 和kkk ,预测基于他们各自的 embedding,是否存在链接。最小化以下分类损失:
L=−logexp(⟨hq,hk⟩)exp(⟨hq,hk⟩)+∑r∈Rexp(⟨hq,hr⟩).
\mathcal{L}=-\log\frac{\exp(\langle\mathbf{h}_q,\mathbf{h}_k\rangle)}{\exp(\langle\mathbf{h}_q,\mathbf{h}_k\rangle)+\sum_{r\in R}\exp(\langle\mathbf{h}_q,\mathbf{h}_r\rangle)}.
L=−logexp(⟨hq,hk⟩)+∑r∈Rexp(⟨hq,hr⟩)exp(⟨hq,hk⟩).
hq\mathbf{h}_qhq 和hk\mathbf{h}_khk 是模型得到的节点的 embedding,<⋅><\cdot ><⋅> 表示内积操作,RRR 表示负采样样本。
深入学习:作者在实验中采用了 in-batch negative sampling 的做法,相比其他训练方法,这种做法的优点是什么?
in-batch negative sampling:多个训练 batch,一个 batch 内的正样本将作为其他 batch 内的负样本存在
2.3.2 两阶段训练
在 GraphFomer 里,实际上中心节点和周围节点是被区别对待的,这样做会破坏模型店训练效果。具体来讲,就是中心节点的信息可以直接使用,但是周围节点的信息却需要 3 个步骤才能引入
- 先编码为 node 级的 embedding
- 经过 GAT 操作和中心节点进行聚合
- 引入中心节点经过图增强之后的 token 级 embedding
那么,如果中心节点的文本信息量已经足够完成预测,根本不需要考虑周围的节点信息的话。如此以来,模型的 Transformer 就会很强大,但是 GNN 模块却很弱。为了减轻这个问题,作者提出了一个”热身任务“:链接预测的训练是建立在被人工污染的数据上的。
polluted nodes:一个节点的一个 token 子集会被随机遮盖(masked)
因为被遮盖导致节点表示不足够产生精确的预测,所以模型会强迫自己大量利用周围的信息(加强周围信息的权重)学习。
第一阶段损失
L′=−logexp(⟨hq~,hk~⟩)exp(⟨hq~,hk~⟩)+∑r∈Rexp(⟨hq~,hr~⟩) \mathcal{L}'=-\log\frac{\exp(\langle\mathbf{h}_{\tilde{q}},\mathbf{h}_{\tilde{k}}\rangle)}{\exp(\langle\mathbf{h}_{\tilde{q}},\mathbf{h}_{\tilde{k}}\rangle)+\sum_{r\in R}\exp(\langle\mathbf{h}_{\tilde{q}},\mathbf{h}_{\tilde{r}}\rangle)} L′=−logexp(⟨hq~,hk~⟩)+∑r∈Rexp(⟨hq~,hr~⟩)exp(⟨hq~,hk~⟩)
波浪号标志的元素表示从被污染的节点上得到的 embedding。最小化该损失函数直到收敛。
第二阶段损失
L=−logexp(⟨hq,hk⟩)exp(⟨hq,hk⟩)+∑r∈Rexp(⟨hq,hr⟩). \mathcal{L}=-\log\frac{\exp(\langle\mathbf{h}_q,\mathbf{h}_k\rangle)}{\exp(\langle\mathbf{h}_q,\mathbf{h}_k\rangle)+\sum_{r\in R}\exp(\langle\mathbf{h}_q,\mathbf{h}_r\rangle)}. L=−logexp(⟨hq,hk⟩)+∑r∈Rexp(⟨hq,hr⟩)exp(⟨hq,hk⟩).
也就是正常的损失函数。
3 实验
3.1 数据集
- DPLB:论文引文图,论文的标题作为文本特征
- WIKI:维基百科的实体图,每个实体介绍中的第一个句子作为文本特征
- Product Graph:在线产品数据集,产品名称,品牌作为文本特征
输入文本的 tokenization 是采用的子词粒度分词的 WordPiece 法。在实验中,每一个文本和 5 个均匀采样的邻居相关联,数据集规格如下:
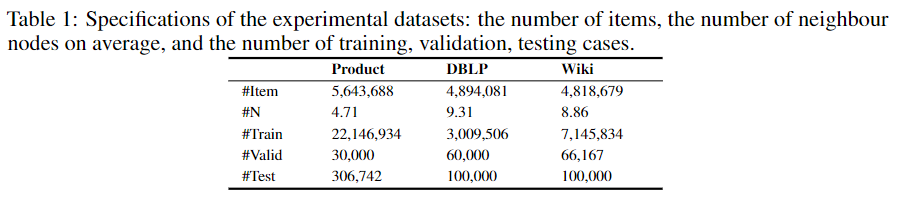
在实验中,每一个测试实例中,一个qqq 节点会被提供 300 个kkk 节点:1 个正例和 299 个负例。 关于链接预测的衡量指标,有 3 个
- Precision@1:预测正确的相关结果占全部结果的比例
Precision@k=TP@kTP@k+FP@k \text{Precision@k}=\frac{\text{TP@k}}{\text{TP@k}+\text{FP@k}} Precision@k=TP@k+FP@kTP@k
- **NDCG(Normalized Discounted Cumulative Gain)**归一化折损累积增益:考虑了返回顺序的评价指标
NDCG@k=DCG@kIDCG@k \mathrm{NDCG}@k=\frac{\mathrm{DCG}@k}{\mathrm{IDCG}@k} NDCG@k=IDCG@kDCG@k
DCG@k=∑i=1krelilog2(i+1) \mathrm{DCG@k}=\sum_{\mathrm{i=1}}^\mathrm{k}\frac{\mathrm{rel_i}}{\log_2\left(\mathrm{i+1}\right)} DCG@k=i=1∑klog2(i+1)reli
IDCG@k=∑i=1∣REL∣relilog2(i+1) \mathrm{IDCG@k}=\sum_{\mathrm{i=1}}^{|\mathrm{REL}|}\frac{\mathrm{rel_i}}{\log_2(\mathrm{i+1})} IDCG@k=i=1∑∣REL∣log2(i+1)reli
其中relirel_ireli 表示第iii 个结果的真实相关性分数。第三个公式是理想的 DCG,将 rel 集合按照从大到小的顺序排序,取前 k 个。
- **MRR(Mean Reciprocal Rank)平均倒数排名:**强调用户的需求项在模型推荐列表中的位置
MRR=1S∑i=1S1pi \mathrm{MRR}=\frac1S\sum_{i=1}^S\frac1{p_i} MRR=S1i=1∑Spi1
SSS 表示全部样本数量,pip_ipi 表示第iii 个样本在模型推荐列表中的位置。
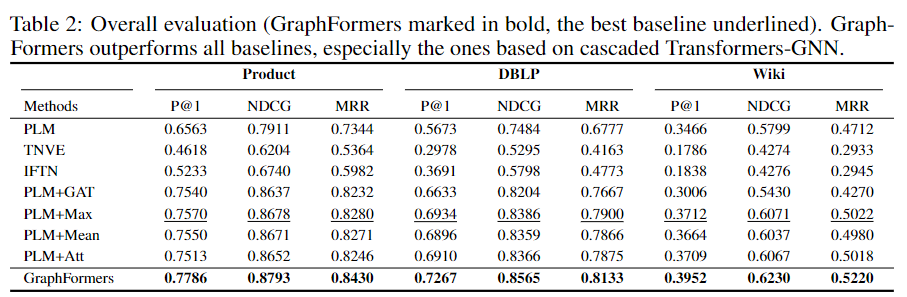
3.2 实验结果
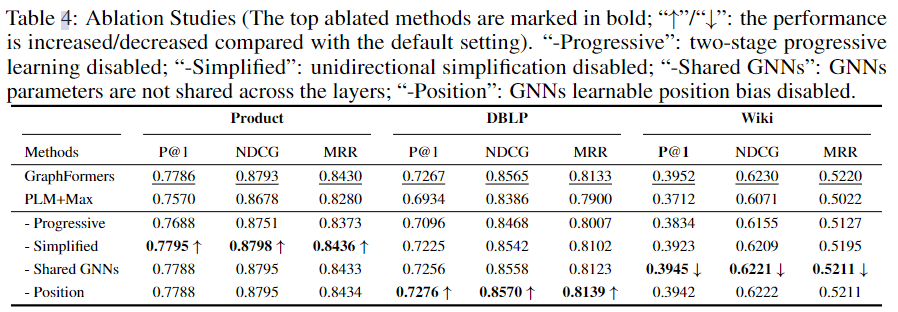
3.3 消融实验
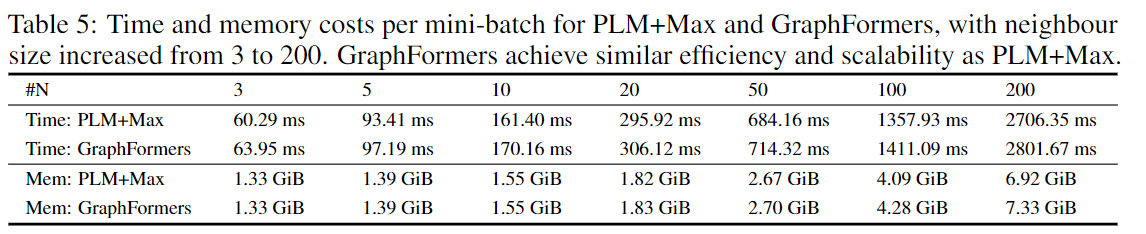
3.4 效率分析
每一个 mini-batch32 个节点,一张 P100,节点的 token 长度是 16
4 总结
- 将 GNN 和 Transformer 嵌套在一起,因此文本底层语义被挖掘的同时还能聚合周围邻居的信息
- 两阶段训练方式加强了训练质量
- 单向图聚合缓解了计算负担

















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









