



如果你对机器学习感兴趣或者一直从事机器学习,那么分类和回归是最常见词汇。但还有一种常见的技术,称为相似性问题,它可以发现两个输入是否相似,这就是所谓的孪生神经网络。
假设你熟悉用于图像分类的 CNN,并且之前已经训练过图像分类模型或正常分类类型,那么你应该可以使用正常深度学习网络或完全连接层网络识别狗和猫图像的模型。
使用传统深度学习神经网络架构的图像分类模型
首先必须获得包含狗和猫图像的标记数据集。在训练神经网络后,在输入任何图像时,网络只能输出狗或猫的标签。这是一个标准的计算机视觉问题,称为图像分类。
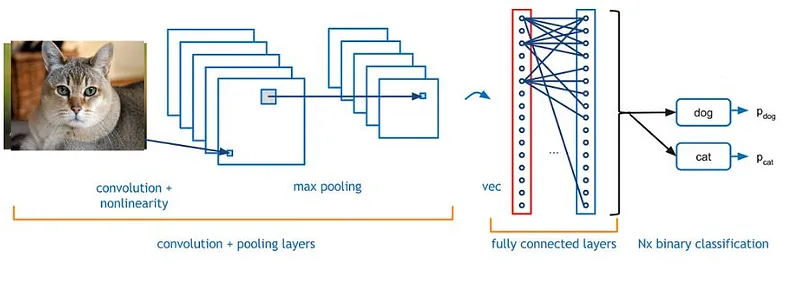
在分类中,输入图像被输入到神经网络(神经网络或全连接层网络)中,最后在输出层,我们得到所有类别的概率分布列表(根据要解决的分类问题使用 Softmax 或任何其他激活函数)。
但是在训练过程中,我们需要每个类别(猫和狗)都有大量的图像,如果网络只在上述两类图像上进行训练,那么我们就不能期望在任何其他类别上进行预测或测试,例如“大象”。
如果我们希望我们的模型也能对大象的图像进行分类,那么我们首先需要获得大量的大象图像,然后我们必须在这些图像上再次重新训练模型,然后进行预测。
有些应用中,我们没有足够的数据来表示每个类别,而且对于员工考勤系统等用例,类别数量可能会呈指数级增长。因此,每次添加新类别或新员工加入时,数据收集和重新训练的成本都很高。
由于这种相似度得分学习或孪生神经网络等算法成为传统分类算法的替代。
什么是相似性学习?
相似度学习是一种监督机器学习技术,其目标是让模型学习,这是一个相似度函数,用于测量两个对象的相似程度并返回相似度值。
当对象相似时,返回高分;当图像或对象不同时,返回低分。现在让我们看一些使用相似性学习即一次性分类(孪生网络)的用例。
孪生网络的用例
在这里我们将看到相似性学习的两个用例,首先是员工考勤,其次是签名验证系统。
在孪生网络中,我们只需要每个类一个训练示例。因此得名One Shot。让我们尝试用一个现实世界的实际例子来理解。
- 员工考勤系统
假设我们要为一个只有 20 名员工(人数较少,事情简单)的小公司建立一个考勤系统,系统必须识别员工的面部。
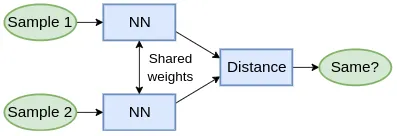
建立考勤系统的问题
第一个问题是训练数据图像,我们首先需要组织中每个员工的大量不同图像。
当新员工加入或离开组织时,我们需要费力地再次收集数据并重新训练整个模型。这对于可扩展的系统来说效率不高,尤其是对于大型组织来说,几乎每周都有人员的更迭。对于这种需要可扩展系统的场景,孪生网络模型可以是一个很好的解决方案。
现在,孪生网络所做的不是将测试图像分类为组织中的 20 个人之一,而是将该人的参考图像作为输入,并生成相似度分数,表示两个输入图像属于同一个人的概率。
使用 S 型函数,相似度得分介于 0 和 1 之间。
相似度得分 0 表示不相似,相似度得分 1 表示完全相似。0 到 1 之间的任何数字都将被相应地解释。
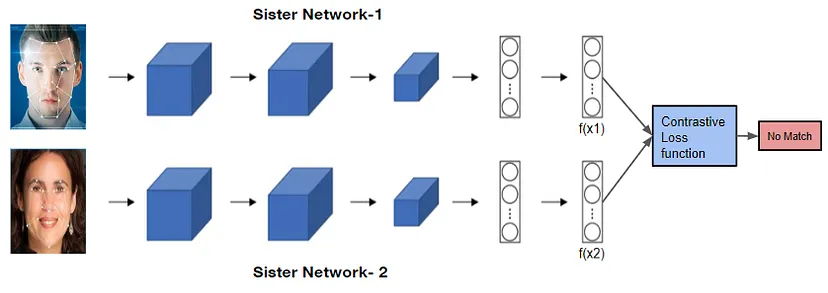
孪生网络不会学习将图像归类到任何输出类别。但是,它会借助相似度函数进行学习,该函数将两幅图像作为输入,并给出这些图像相似程度的概率。百度也使用类似的技术为其组织内的员工开发了面部识别系统。
孪生神经网络如何解决上述问题?
1)与深度学习中的传统神经网络不同,孪生网络不需要太多类别的实例,只需很少的实例就足以构建一个良好的模型。
2)孪生网络的最大优势在于,在考勤等面部检测应用中,当我们的模型中有新员工或新班级时,网络只需要一张该员工的面部图像即可检测出该员工的面部。使用这张图像作为参考图像,网络将计算任何新实例的相似度得分。这就是我们说网络一次性预测得分并称其为一次性学习模型的原因。
- 使用孪生网络的签名验证系统
连体网络还可用于将账户持有人的签名与支票或任何需要账户持有人签名的文件上的签名进行比较,出于安全目的,银行员工需要对其进行验证。
如果相似度得分高于某个阈值(需要根据模型的训练性能来决定),则检查被接受;如果相似度得分较低,则签名是被伪造的可能性就比较高。
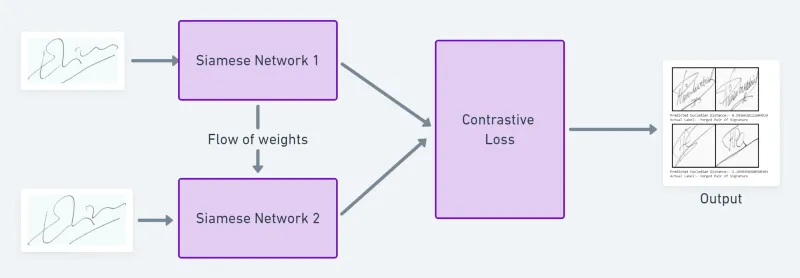
这也使得系统具有可扩展性,开发时间更少,甚至对数据和重新训练时间的需求也减少了。从而使系统更加高效。
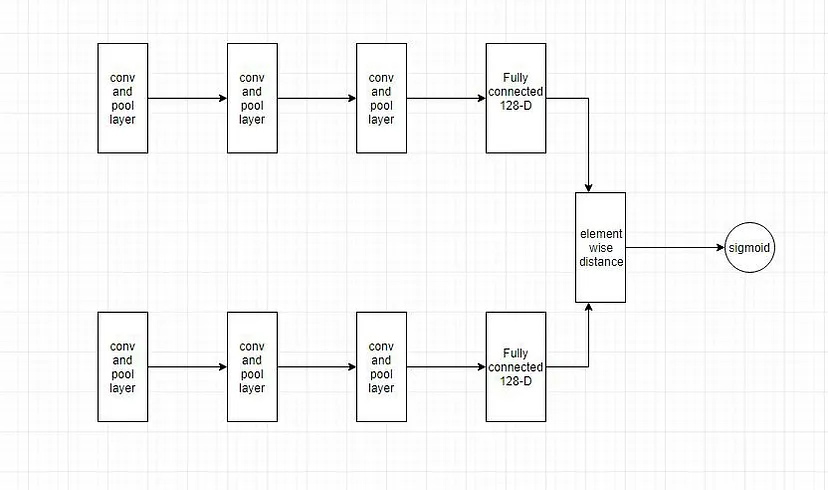
孪生神经网络架构
孪生网络是一种包含两个或多个相同子网络的人工神经网络,即它们具有相同的配置、相同的参数和权重。
大多数情况下,我们只训练 N(为解决问题而选择的子网络数量)个子网络中的一个,并对其他子网络使用相同的配置(参数和权重)。
孪生网络用于通过比较输入的特征向量来找到输入的相似性。
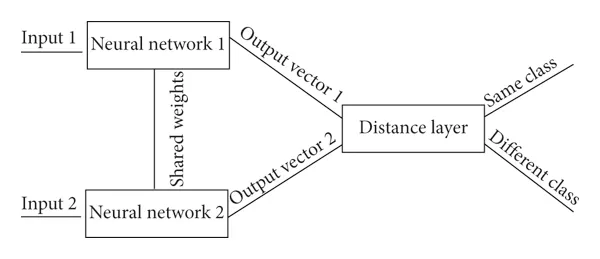
孪生网络架构工作原理的分步说明
我们有两幅图像,我们想比较一下它们是否相似或不相似
- 第一个子网络以图像(A)作为输入,经过卷积层和全连接层,得到图像的矢量表示
- 再次将第二幅图像(B)传递到具有完全相同的权重和参数的网络。
- 现在我们有了来自相应图像的两个编码 E(A) 和 E(B),我们可以比较这两个编码以了解这两个图像有多相似。如果图像相似,那么编码也会非常相似。
- 我们将测量这两个向量之间的距离,如果它们之间的距离很小,那么这两个向量相似或属于同一类,如果它们之间的距离较大,那么这两个向量彼此不同,这基于分数。
在孪生网络架构中,损失函数起着区分两幅图像中相似和不相似的对的主要作用。
孪生网络中的损失函数
让我们来看看孪生网络的两个主要损失函数,即对比损失和三重态损失。
- 对比损失函数
孪生网络不是对输入图像进行分类,而是对输入图像进行区分。因此,像交叉熵损失这样的分类损失函数并不是最佳选择。
点击机器学习笔记 孪生神经网络综合指南查看全文。

















 2741
2741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









