







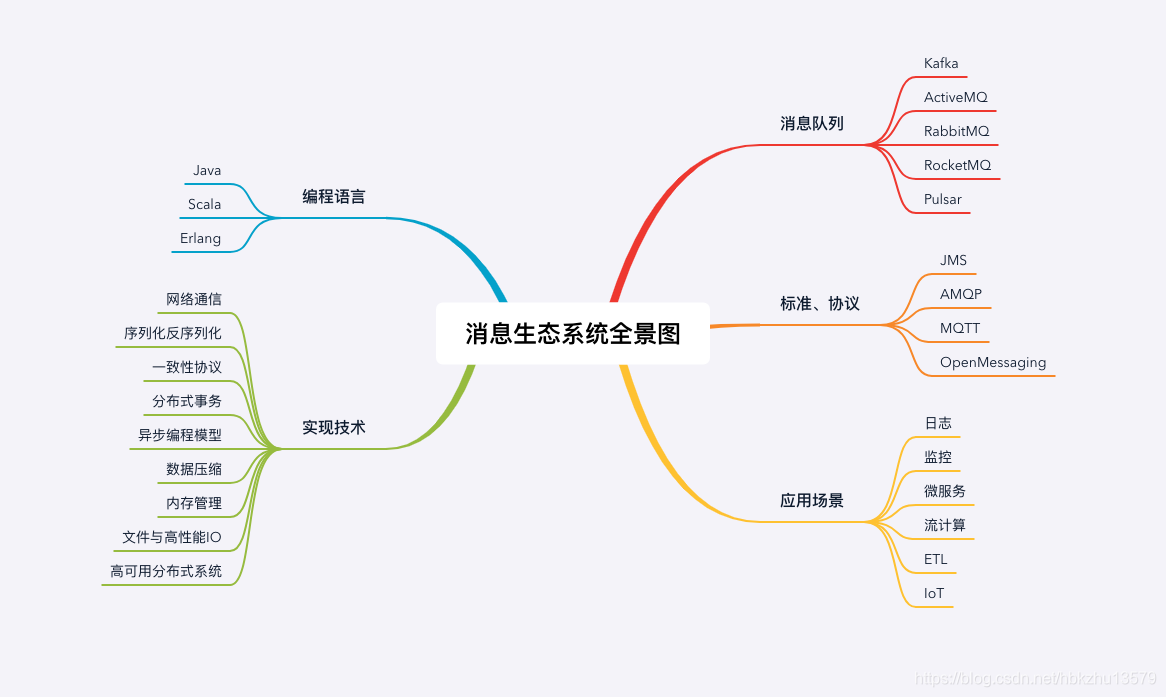
 本文详细介绍了消息队列的基础知识,包括为何需要消息队列、如何选择消息队列以及消息模型的对比。文章讨论了RabbitMQ、RocketMQ和Kafka的消息模型,并解释了如何利用事务消息实现分布式事务。此外,还探讨了如何确保消息不丢失,以及处理消费过程中的重复消息和性能优化策略,如通过幂等性设计和消费端性能调整防止消息积压。
本文详细介绍了消息队列的基础知识,包括为何需要消息队列、如何选择消息队列以及消息模型的对比。文章讨论了RabbitMQ、RocketMQ和Kafka的消息模型,并解释了如何利用事务消息实现分布式事务。此外,还探讨了如何确保消息不丢失,以及处理消费过程中的重复消息和性能优化策略,如通过幂等性设计和消费端性能调整防止消息积压。
概览
01 | 为什么需要消息队列?
哪些问题适合使用消息队列来解决?
- 异步处理
- 流量控制
- 服务解耦
- 作为发布 / 订阅系统实现一个微服务级系统间的观察者模式;
- 连接流计算任务和数据;
- 用于将消息广播给大量接收者。
局限性:
- 引入消息队列带来的延迟问题;
- 增加了系统的复杂度;
- 可能产生数据不一致的问题。
02 | 该如何选择消息队列?
选择中间件的考量维度:可靠性,性能,功能,可运维行,可拓展性,是否开源及社区活跃度
- RabbitMQ:
优点:轻量,迅捷,容易部署和使用,拥有灵活的路由配置
缺点:性能和吞吐量较差,不易进行二次开发 - RocketMQ:
优点:性能好,稳定可靠,有活跃的中文社区,特点响应快
缺点:兼容性较差,但随着影响力的扩大,该问题会有改善 - Kafka:
优点:拥有强大的性能及吞吐量,兼容性很好
缺点:由于“攒一波再处理”导致延迟比较高 - Pulsar:
采用存储和计算分离的设计,是消息队里产品中黑马,值得持续关注
03 | 消息模型:主题和队列有什么区别?
主题和队列有什么区别?
最初的消息队列,就是一个严格意义上的队列。在计算机领域,“队列(Queue)”是一种数据结构,有完整而严格的定义。在维基百科中,队列的定义是这样的:
队列是先进先出(FIFO, First-In-First-Out)的线性表(Linear List)。在具体应用中通常用链表或者数组来实现。队列只允许在后端(称为 rear)进行插入操作,在前端(称为 front)进行删除操作。
这个定义里面包含几个关键点,第一个是先进先出,这里面隐含着的一个要求是,在消息入队出队过程中,需要保证这些消息严格有序,按照什么顺序写进队列,必须按照同样的顺序从队列中读出来。不过,队列是没有“读”这个操作的,“读”就是出队,也就是从队列中“删除”这条消息。
早期的消息队列,就是按照“队列”的数据结构来设计的。我们一起看下这个图,生产者(Producer)发消息就是入队操作,消费者(Consumer)收消息就是出队也就是删除操作,服务端存放消息的容器自然就称为“队列”。
这就是最初的一种消息模型:队列模型。
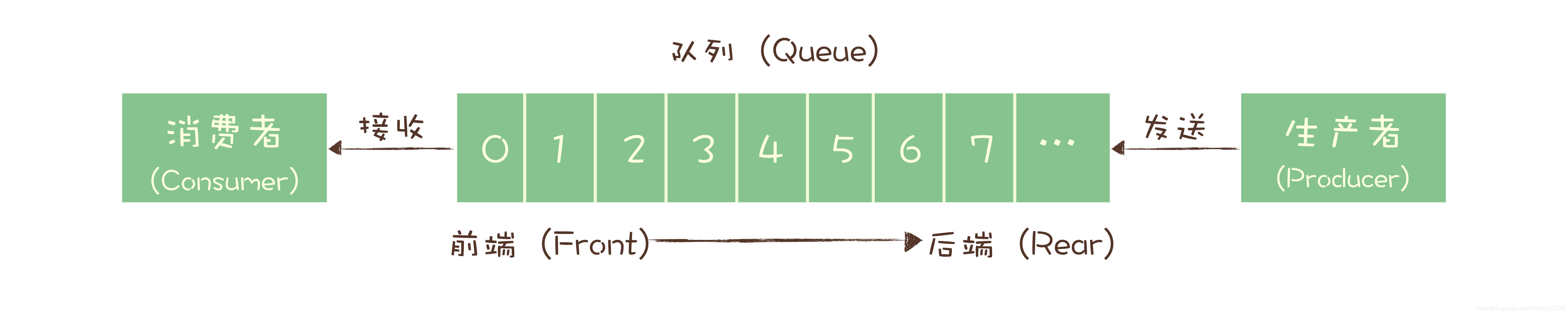
如果有多个生产者往同一个队列里面发送消息,这个队列中可以消费到的消息,就是这些生产者生产的所有消息的合集。消息的顺序就是这些生产者发送消息的自然顺序。如果有多个消费者接收同一个队列的消息,这些消费者之间实际上是竞争的关系,每个消费者只能收到队列中的一部分消息,也就是说任何一条消息只能被其中的一个消费者收到。
如果需要将一份消息数据分发给多个消费者,要求每个消费者都能收到全量的消息,例如,对于一份订单数据,风控系统、分析系统、支付系统等都需要接收消息。这个时候,单个队列就满足不了需求,一个可行的解决方式是,为每个消费者创建一个单独的队列,让生产者发送多份。
显然这是个比较蠢的做法,同样的一份消息数据被复制到多个队列中会浪费资源,更重要的是,生产者必须知道有多少个消费者。为每个消费者单独发送一份消息,这实际上违背了消息队列“解耦”这个设计初衷。
为了解决这个问题,演化出了另外一种消息模型:“发布 - 订阅模型(Publish-Subscribe Pattern)”。
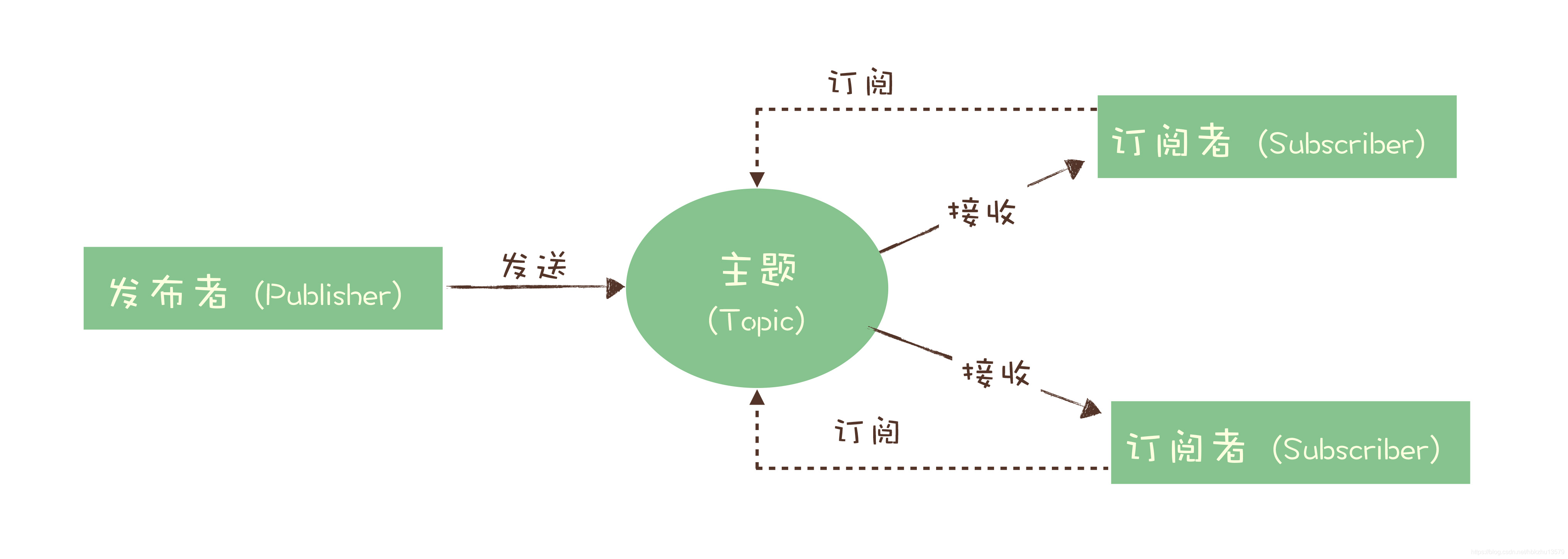
在发布 - 订阅模型中,消息的发送方称为发布者(Publisher),消息的接收方称为订阅者
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1000
1000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









