






python面试整理
1.说说解释性语言和编译型语言
解释性语言和编译性语言是计算机编程语言的两大类型,它们的主要区别在于代码执行的方式和实现过程的不同。简而言之,解释性语言是通过解释器逐行执行代码,而编译性语言则通过编译器将源代码转化为机器代码再执行。
2.说说python程序运行过程
- 源代码 (
.py) → Python解释器编译为字节码 (.pyc)。 - 字节码加载到Python虚拟机中执行。
- Python虚拟机逐条解释执行字节码。
- 执行完成,输出结果或执行其他任务。
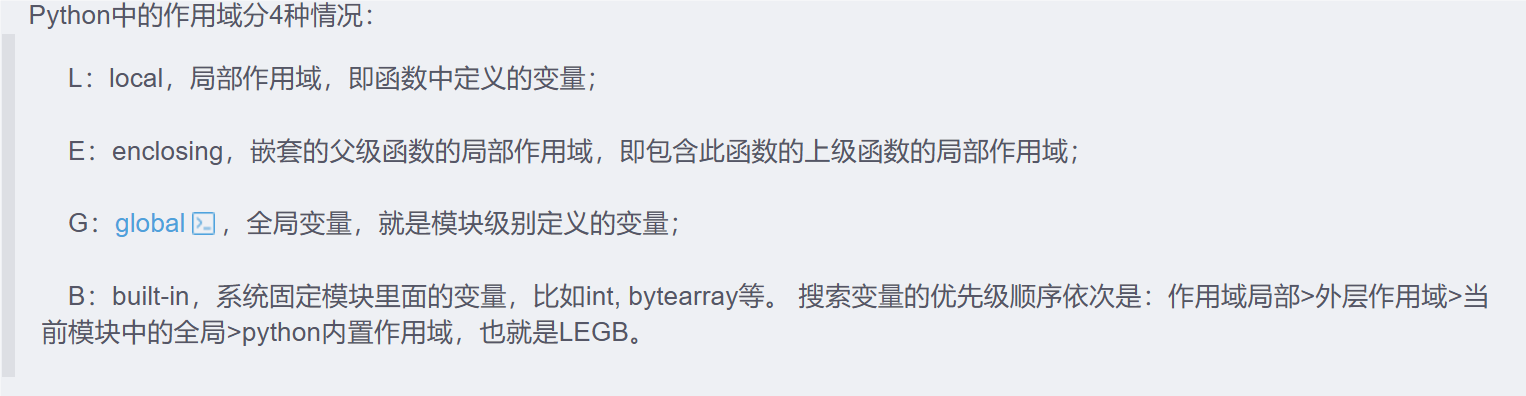
3.说说python的作用域
四种,局部作用域, 外层作用域,全局变量,python内置作用域(系统固定模块的变量)
4.说说python的数据结构
集合:set
序列:list, tuple,stack,deque,str
映射:dictionary
5.python中的可变与不可变类型
可变:列表,集合,字典
不可变:str,int,float,bool,tuple
6.说说进程与线程
- 线程:线程是程序中的一个执行单元,是CPU调度的最小单位。
- 进程:进程是程序的执行实例,一个进程可以包含多个线程。进程之间是相互独立的,而线程之间共享同一进程的资源(如内存、文件描述符等)。

7.说说python中的多进程
-
Python中的多进程是通过
multiprocessing模块实现的,它适合CPU密集型任务,能够充分利用多核处理器的计算能力。 -
多进程编程中,进程间通信(IPC)可以通过
Queue、Pipe等机制实现,进程池(Pool)适用于大量独立任务的并行处理。
对象可以帮助管理一组进程并实现进程池的功能,特别适用于需要大量并发执行相同任务的场景。
Pool会自动分配任务到不同的进程执行,避免手动管理每个进程。 -
import multiprocessing def square(x): return x * x if __name__ == "__main__": # 创建进程池,指定进程池大小 pool = multiprocessing.Pool(processes=4) # 使用map方法并行计算 result = pool.map(square, [1, 2, 3, 4, 5]) print("计算结果:", result) # 关闭进程池 pool.close() pool.join()
8.说说python中的多线程
python在同一时刻只能有一个线程在解释器中运行,因为有全局解释器锁 GIL来控制,
多线程共享主进程的资源,所以线程可能会改变全局变量,需要加上线程锁,等这个线程运行完之后再运行下一个线程
io密集型可以提高运行效率,因为在io 的时候就会释放全局解释器锁,执行下一个线程
import threading
# 创建一个锁对象
lock = threading.Lock()
# 定义共享资源
shared_data = 0
# 定义线程执行的函数
def increment():
global shared_data
for _ in range(100000):
lock.acquire() # 获取锁
shared_data += 1
lock.release() # 释放锁
# 创建两个线程
thread1 = threading.Thread(target=increment)
thread2 = threading.Thread(target=increment)
# 启动线程
thread1.start()
thread2.start()
# 等待线程结束
thread1.join()
thread2.join()
print("最终的共享数据值:", shared_data)
9.说说python中的互斥锁和死锁
-
互斥锁(Mutex):互斥锁用于保证同一时刻只有一个线程能够访问共享资源,避免多线程同时操作同一资源时出现竞争条件。
threading.Lock是Python中实现互斥锁的常用方式。 -
死锁(Deadlock):死锁发生在多个线程相互等待对方释放资源时,导致程序无法继续执行。死锁的四个条件是:互斥、持有并等待、不剥夺和循环等待。
-
避免死锁:
- 按照统一的顺序获取锁。
- 使用
tryLock()方法尝试获取锁,避免长期阻塞。 - 使用可重入锁(
RLock)来避免同一线程反复获得同一锁。
10.说说lambda
- 匿名性:
lambda创建的是一个没有名字的函数,通常用于简单的函数操作,适合短小的函数逻辑。 - 单一表达式:
lambda函数体只能包含一个表达式,不能包含多个语句或复杂的控制结构。 - 返回值:
lambda表达式的返回值就是它的计算结果,不需要显式使用return语句。 - 临时使用:
lambda函数通常是短期使用的函数,多用于需要函数作为参数传递的地方。
11.说说深拷贝与浅拷贝
浅拷贝创建新的对象,但是是对原对象的引用,改变新对象,原对象也会改变,拷贝父对象,不会拷贝对象内部的子对象
深拷贝:完全拷贝了父对象和子对象,深拷贝出来的对象是一个全新的对象,与原对象无关
12.说说python多线程能否用多个cpu
不能
13.说说python垃圾回收机制
Python 的垃圾回收机制主要依赖于两种策略:
- 引用计数:每个对象都有一个引用计数器,当引用计数为零时,内存会被回收。
- 垃圾回收器:处理循环引用和无法通过引用计数回收的对象,使用 分代回收 策略。
引用计数和循环垃圾回收(分代回收)
14.说说python中的生成器
生成器是一种创建迭代器的工具,在返回数据时用yield语句,每一调用next()生成一个数据,生成器从上一次执行的地方重新开始
特性:惰性求值,只能遍历一次(之后会销毁)
def fibonacci():
a, b = 0, 1
while True:
yield a
a, b = b, a + b
# 创建生成器
fib = fibonacci()
# 获取前10个斐波那契数
for _ in range(10):
print(next(fib), end=" ") # 输出: 0 1 1 2 3 5 8 13 21 34
15.说说python中生成器和迭代器的区别
| 特性 | 迭代器(Iterator) | 生成器(Generator) |
|---|
| 定义 | 实现了__iter__()和__next__()方法的对象。 | 通过yield关键字定义的特殊类型的迭代器。 |
|---|
| 实现方式 | 手动实现__iter__()和__next__()方法。 | 通过生成器函数或生成器表达式自动实现。 |
|---|
| 内存使用 | 需要存储所有的元素(例如列表或其他容器)。 | 生成器按需生成元素,不需要一次性存储所有元素,节省内存。 |
|---|
| 是否支持惰性求值 | 不支持惰性求值。每次调用__next__()都返回一个元素。 | 支持惰性求值。每次调用next()都生成下一个元素。 |
|---|
| 是否需要显式的初始化 | 需要显式初始化对象并定义方法。 | 通过yield语句生成,不需要显式初始化。 |
|---|
| 可重复性 | 迭代器只能遍历一次,遍历完后需要重新创建。 | 生成器只能遍历一次,但通过重新调用生成器函数可以重新生成。 |
|---|
| 代码简洁度 | 需要实现多个方法,代码量较多。 | 通过yield语句,可以简洁地定义迭代器,代码量更少。 |
|---|
class MyIterator:
def __init__(self, start, end):
self.current = start
self.end = end
def __iter__(self):
return self
def __next__(self):
if self.current >= self.end:
raise StopIteration
self.current += 1
return self.current - 1
# 创建迭代器实例
iter_obj = MyIterator(1, 5)
# 使用迭代器
for num in iter_obj:
print(num)
16.说说list中del,pop,remove的区别
del | 删除指定索引的元素或删除整个列表 | 可指定索引或删除整个列表 | 无返回值 | 索引越界时抛出IndexError |
|---|
pop() | 删除并返回指定索引的元素,默认删除并返回最后一个元素 | 可指定索引,默认删除最后一个元素 | 返回被删除的元素 | 索引越界或空列表时抛出IndexError |
|---|
remove() | 删除列表中的第一个匹配值元素 | 需要指定要删除的元素值 | 无返回值 | 元素不存在时抛出ValueError |
|---|
16.说说python中的闭包
在函数中嵌套另一个函数,并且在内部函数中,调用外部作用域的变量,,即使在外部函数已经执行完毕并返回后,内部函数依然可以访问外部函数的局部变量。
def outer_function(x):
# 外部函数的局部变量
def inner_function(y):
return x + y # 内部函数使用了外部函数的局部变量 x
return inner_function # 返回内部函数
# 创建闭包
closure_func = outer_function(10)
# 调用闭包
print(closure_func(5)) # 输出: 15
简而言之,闭包是由函数和函数外部的变量(即自由变量)共同组成的“环境”,它使得一个函数在其定义的作用域外部仍能访问其外部作用域的变量。
- 说说python中的装饰器
- 装饰器 是一种用于动态修改函数行为的技术,常常用于代码复用、日志记录、权限检查等场景。
- 装饰器本质上是一个接受函数作为参数并返回一个新的函数的函数。
- 装饰器可以带参数,用于更加灵活的功能扩展。
- 使用
functools.wraps 可以保留被装饰函数的元数据。
def log_decorator(func):
def wrapper():
print(f"Function {func.__name__} is called.")
return func()
return wrapper
@log_decorator
def greet():
print("Hello!")
greet()
- yield 和 return 的区别
| 特点 | return | yield |
|---|---|---|
| 函数行为 | 使函数立即结束并返回一个值 | 使函数暂停执行并返回一个生成器对象 |
| 函数执行状态 | 函数执行结束,无法恢复 | 函数在每次yield后暂停,可以恢复继续执行 |
| 返回类型 | 返回值 | 返回一个生成器对象 |
| 内存消耗 | 一次性返回所有结果,占用内存较大 | 延迟生成数据,内存消耗较小 |
19.python中set的底层实现
哈希表,set只是默认值和键相同
20.python中set和字典的区别
都是用哈希表实现的,不过字典有序,set无序,字典key不能重复,set值不能重复
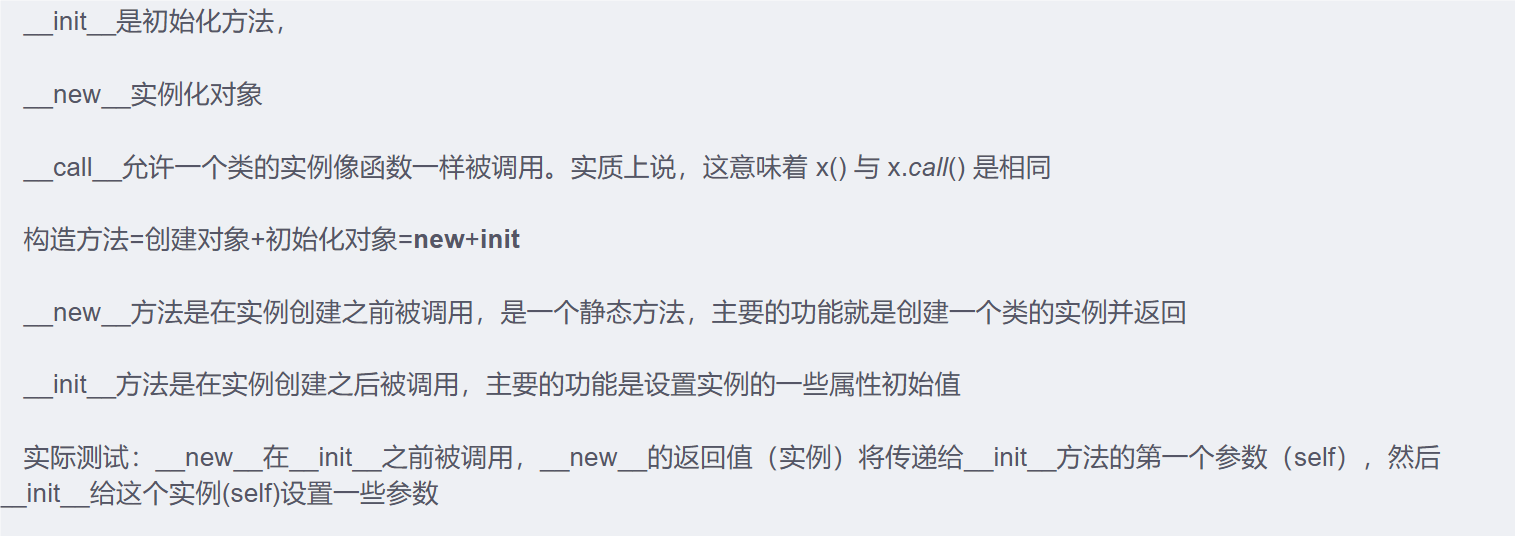
21.python中__init__ 和__new__ 和__call__的区别
22.说说python内存管理
-
引用计数是 Python 中的主要内存管理机制,通过追踪对象的引用次数来决定何时回收内存。
-
垃圾回收是 Python 用于处理循环引用问题的机制,使用分代收集算法,定期回收不再使用的对象。
-
内存池优化了小对象的内存分配,避免频繁的内存分配和释放。
-
内存池机制:Python 使用 内存池(Memory Pool)来提高内存分配的效率。特别是对小对象(例如小于 512 字节的对象)进行内存管理时,Python 使用了一个称为 “分配器”(allocator)来维护内存池,以避免频繁的操作系统内存分配和释放。通过分配器的内存池,多个对象可以共享内存空间。
- 例如,Python 中的
int 类型会使用专门的内存池来管理常见的小整数,通常在-5 到256 之间的整数都会被事先分配好并重用,减少了内存的分配和回收开销
- 例如,Python 中的
23.python 中类方法与静态方法的区别
| 特性 | 类方法 (@classmethod) | 静态方法 (@staticmethod) |
|---|
| 第一个参数 | cls(类本身),可以访问类的属性和方法 | 无默认第一个参数,不能访问类或实例的属性和方法 |
|---|
| 用途 | 用于操作类级别的属性和方法,或创建类的实例 | 用于执行不依赖于类或实例状态的功能 |
|---|
| 访问权限 | 可以访问类的属性和方法,但不能访问实例的属性 | 不能访问类或实例的任何属性和方法 |
|---|
| 调用方式 | 可以通过类或实例调用 | 可以通过类或实例调用 |
|---|
| 常见场景 | - 操作类变量 - 定义工厂方法(如 from_string) | - 独立的 |
|---|
24.说说python中点积和矩阵相乘的区别
标量,矩阵
25.说说python中错误和异常处理
分为语法错误和逻辑错误,
异常处理:try except
- python中try else 和try finally 的区别
try-else:在没有异常发生时执行else 块中的代码,适用于你想在没有异常的情况下执行额外操作的情况。try-finally:finally 块总是会执行,不管try 块是否发生异常。适用于确保资源清理等必须执行的操作。
27.说说什么是猴子补丁
是指在运行时动态地修改或扩展一个模块或类的功能,通常是在不修改源代码的情况下对某个模块的函数、方法、类等进行修改。
28.python中is 和==的区别
== 用来比较对象的值是否相等(内容比较)。is 用来比较对象的身份是否相同(内存地址比较)
29.GBK和UTF-8的区别
GBK只支持中文字符,UTF-8支持全球所有语言的字符
编译方式:UTF-8 对于ASCAL码一1字节,中文字符3字节, 对于多语言平台建议用UTF-8,只在中文环境下工作,可以选择GBK
30.说说遍历字典的方法
dic1 = {'date':'2018.11.2','name':'carlber','work':"遍历",'number':3}
for i in dic1:
print(i)
for key in dic1.keys(): #遍历字典中的键
print(key)
for value in dic1.values(): #遍历字典中的值
print(value)
for item in dic1.items(): #遍历字典中的元素
print(item)
31.说说反转列表的方法
# 1. 内建函数reversed()
li=[1,2,3,4,5,6]
a= list(reversed(li))
# 2. 内建函数sorted()
li=[1,2,3,4,5,6]
c=sorted(a, reverse=True)
# 3. 使用分片[::-1]
li=[1,2,3,4,5,6]
li[::-1]
31.如何把元组转换为字典
dict()函数 | dict([("a", 1), ("b", 2)]) | 直接将二元组列表转换为字典 |
|---|
| 字典推导式 | {key: value for key, value in tuple_list} | 自定义转换并进行处理 |
|---|
zip()函数 | dict(zip(keys, values)) | 将两个元组(一个为键,另一个为值)配对并转换为字典 |
|---|
| 嵌套元组 | dict([("a", 1), ("b", 2)]) | 转换嵌套的元组列表 |
|---|
- python中__init__.py 是的作用和意义
在 Python 中,__init__.py 是一个特殊的文件,通常用于标识一个目录是一个 包(package)。它的作用不仅仅是使目录变成包,还可以包含初始化代码,使得包的导入行为更加灵活。__init__.py 是一个非常重要的文件,在 Python 包的构建和管理中起着关键作用。

33.python 函数调用的方式是值传递还是引用传递
对象传递:
- 不可变对象(
int、float、str、tuple 等):尽管是引用传递,但由于不可变,实际上表现得像是值传递。函数内部无法改变原始对象,只能修改副本。 - 可变对象(
list、dict、set 等):表现得像是引用传递,函数内部可以修改原始对象
34.说说对缺省参数的理解
缺省参数是在没有参数传入时,调用默认参数
*args 不定长参数,可以传入任意数量的未知参数
**kwargs 关键字参数,可以传入任意数量的关键字参数
*args 使用要在**kwarg之前
def my_function(a, b, *args, **kwargs):
print(a, b)
print(args)
print(kwargs)
my_function(1, 2,name="Alice", age=25)
35.列表的去重方式
def distFunc1(a):
"""使用集合去重"""
a = list(set(a))
print(a)
def distFunc2(a):
"""将一个列表的数据取出放到另一个列表中,中间作判断"""
list = []
for i in a:
if i not in list:
list.append(i)
#如果需要排序的话用sort
list.sort()
print(list)
def distFunc3(a):
"""使用字典"""
b = {}
b = b.fromkeys(a)
c = list(b.keys())
print(c)
if __name__ == "__main__":
a = [1,2,4,2,4,5,7,10,5,5,7,8,9,0,3]
distFunc1(a)
distFunc2(a)
distFunc3(a)
36.python常见的列表推导式
- 基本结构:
[表达式 for 元素 in 可迭代对象] - 条件筛选:
[表达式 for 元素 in 可迭代对象 if 条件] - 嵌套循环:可以通过多个
for 循环进行嵌套来处理多维数据结构。 - 条件表达式:通过
if-else 语句根据条件返回不同的值。 - 集合与字典推导式:Python 还支持集合推导式(去重元素)和字典推导式(根据键值对创建字典)。
37.说说map与reduce函数
都是通过传入一个函数和可迭代对象来产生一个新的结果
map(lambda x: x * x, [1, 2, 3, 4]) # 使用 lambda
# [1, 4, 9, 16]
reduce(lambda x, y: x * y, [1, 2, 3, 4]) # 相当于 ((1 * 2) * 3) * 4
# 24
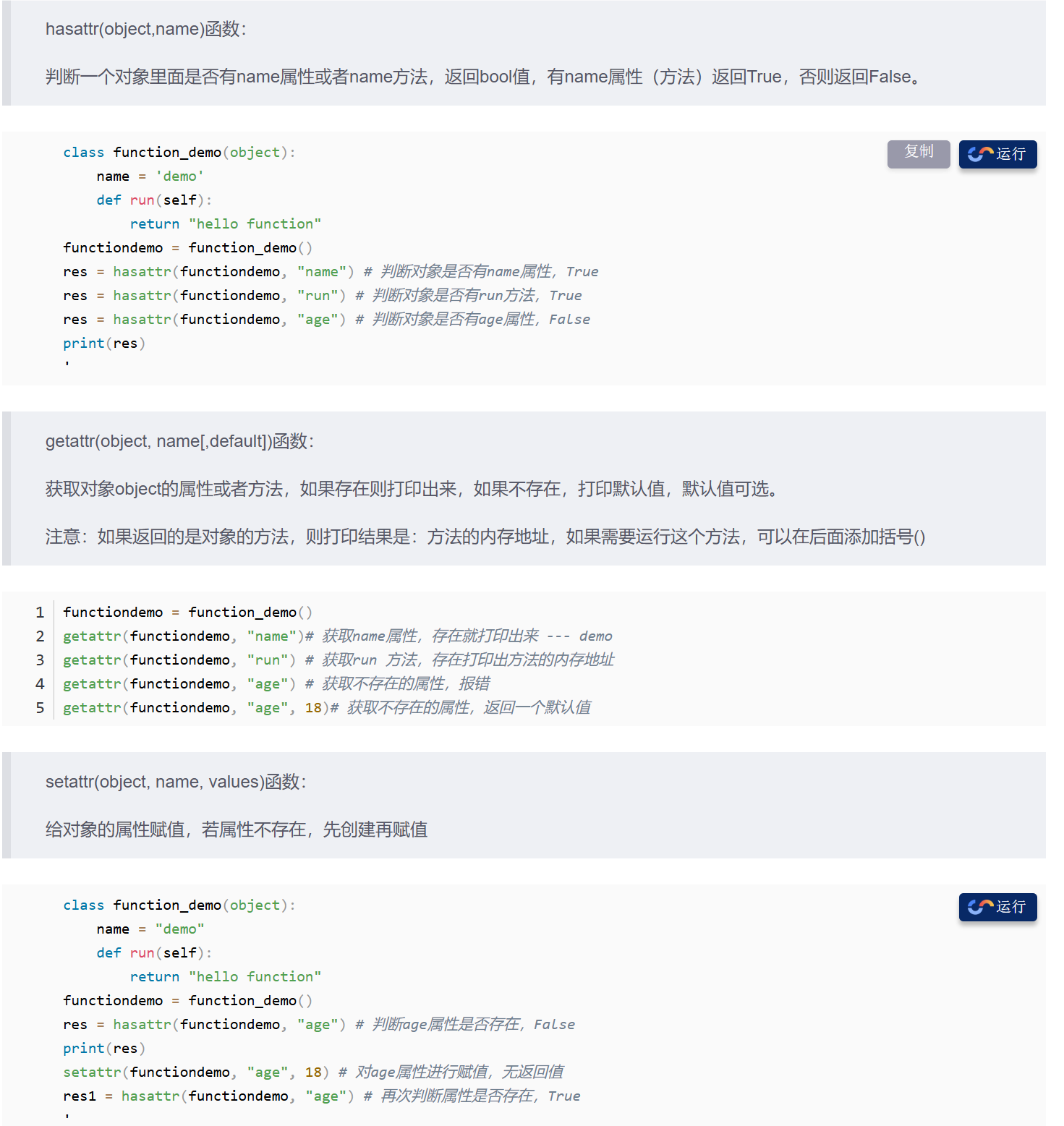
- hasattr,getattr,setattr 函数使用详解
39.说说except的作用和用法
except 语句的作用:用于捕获并处理try 块中的异常,防止程序崩溃。- 捕获特定异常:使用
except ExceptionType 来捕获指定的异常类型。 - 捕获所有异常:如果不指定异常类型,
except 会捕获所有异常类型,但不建议这样做。 else 和finally:else 块用于在没有异常时执行,finally 块无论是否发生异常都会执行,常用于资源清理。
通过 try-except 语句,可以提高程序的健壮性和容错能力,确保程序在发生错误时能够平稳运行并进行适当处理。
40.except中return 之后会不会继续执行finally 中的语句,如何抛出自定义异常
except 中return 后finally 会执行:无论是否有return 语句,finally 块中的代码总是会执行,确保执行清理操作。若finally 中也有return,它会覆盖except 或try 中的return 返回值。- 抛出自定义异常:通过创建一个继承自
Exception 类的异常类,并使用raise 语句抛出,可以在程序中引发自定义异常。这有助于处理业务逻辑中的特定错误。
# 定义自定义异常类
class CustomError(Exception):
def __init__(self, message):
super().__init__(message)
self.message = message
# 使用自定义异常
def test():
try:
raise CustomError("这是一个自定义异常")
except CustomError as e:
print(f"捕获到自定义异常: {e}")
test()
41,什么是断言
assert() 表达式必须为真,表达式为假则发生异常
42.如何理解python字符串中的\ 字符
- 转义字符:
\ 用于表示一些特殊字符,比如换行符\n、制表符\t、回车符\r 等。 - 保留反斜杠:通过原始字符串
r"...",可以防止反斜杠被作为转义字符,直接保留其字面意义。(路径) - 正则表达式中的应用:在正则表达式中,
\ 用于转义特殊字符,因此处理正则表达式时需要小心使用。
或者编写代码过长的手动软换行
43.python是如何进行类型转换的
强制类型转换
- 隐式类型转换:Python 会自动将较小的数据类型转换为较大的数据类型,以避免数据丢失,常见于运算过程中。
- 显式类型转换:通过内建函数(如
int(),float(),str(),list(),tuple() 等)可以手动将数据类型转换为所需类型。 - 注意事项:在进行类型转换时要确保源数据能被正确转换,否则会抛出异常(如
ValueError)。
44.提高python运行效率的方法
- 避免不必要的计算:避免重复计算,缓存中间结果。
- 使用内建函数和库:利用 Python 内建函数和高效的标准库。
- 使用生成器:节省内存,按需生成数据。
- 避免全局变量:避免频繁访问全局变量,减少查找时间。
- 使用
join() 连接字符串:避免使用+ 运算符。 - 避免不必要的函数调用:减少函数调用的开销。
- 使用
numpy 进行数值计算:提高数值计算效率。 - 优化循环:减少循环体中的计算量。
- 使用缓存:对于递归函数使用
lru_cache() 缓存计算结果。 - 避免过多的
try-except:减少异常处理的开销。
45.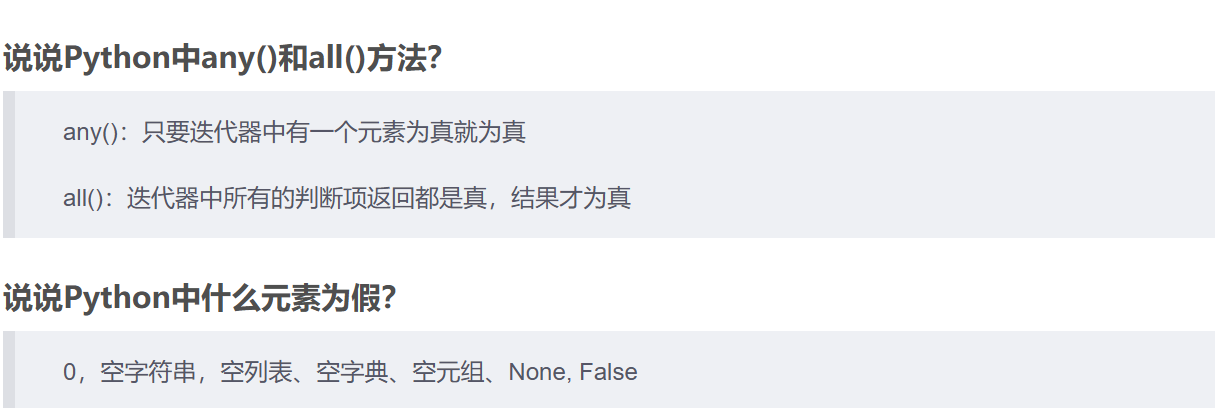
False。None。- 数值类型的零:
0、0.0、0j。 - 空容器:空字符串
"",空列表[],空元组(),空字典{},空集合set(),空冻结集合frozenset()。
其他所有元素都被视为 真。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









