



人类天生就拥有从双眼看到的二维图像中感知三维世界的能力,无论是判断物体的远近,还是在复杂环境中导航,都显得毫不费力。然而,对于人工智能而言,这项能力却长期以来被分解成一个个独立的、高度专门化的任务,例如单目深度估计、多视角三维重建(MVS)、运动恢复结构(SfM)等。每项任务都需要设计独特的、复杂的模型架构,它们就像一个个技术孤岛,难以互通,更无法有效利用大规模预训练模型的强大力量。
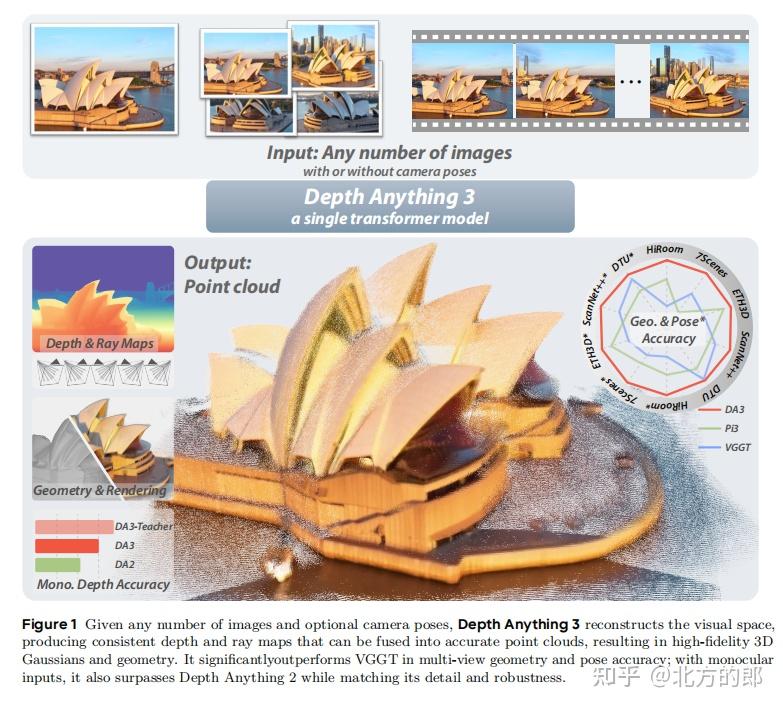
面对这一挑战,来自字节跳动(ByteDance Seed)的研究团队提出了一个颠覆性的解决方案——Depth Anything 3 (DA3)。这篇于2025年11月13日发布的论文,旨在打破3D视觉任务之间的壁垒,实现一个“大一统”的视觉几何模型。DA3的核心思想是“化繁为简”,它以一个惊人简洁的架构,实现了从任意数量、任意视角的图像中恢复三维空间几何的能力,无论是否提供相机位姿。这不仅是一次技术的迭代,更是对3D视觉感知范式的一次深刻重塑,标志着我们向通用3D感知迈出了里程碑式的一步。
论文:https://www.arxiv.org/abs/2511.10647
项目:https://depth-anything-3.github.io/
代码:https://github.com/ByteDance-Seed/depth-anything-3

接下来,我们将为您详细剖析DA3的技术精髓、实验效果及其深远影响。
第一章:引言 (Introduction)
研究团队首先指出了当前3D计算机视觉领域的痛点:任务碎片化与模型特化。尽管单目深度估计、多视角重建等任务在概念上高度重叠,但学界的主流范式是为每个任务“量身定做”模型。这导致模型结构复杂、难以泛化,并且无法充分利用像DINOv2这类在2D领域取得巨大成功的预训练模型的潜力。
为此,作者提出了两个核心问题:
- 是否存在一组最小化的预测目标,足以统一描述和恢复三维空间,而无需对多个3D任务进行联合建模?
- 能否用一个单一、朴素的Transformer模型,不加特殊修改,就足以胜任这个统一的任务?
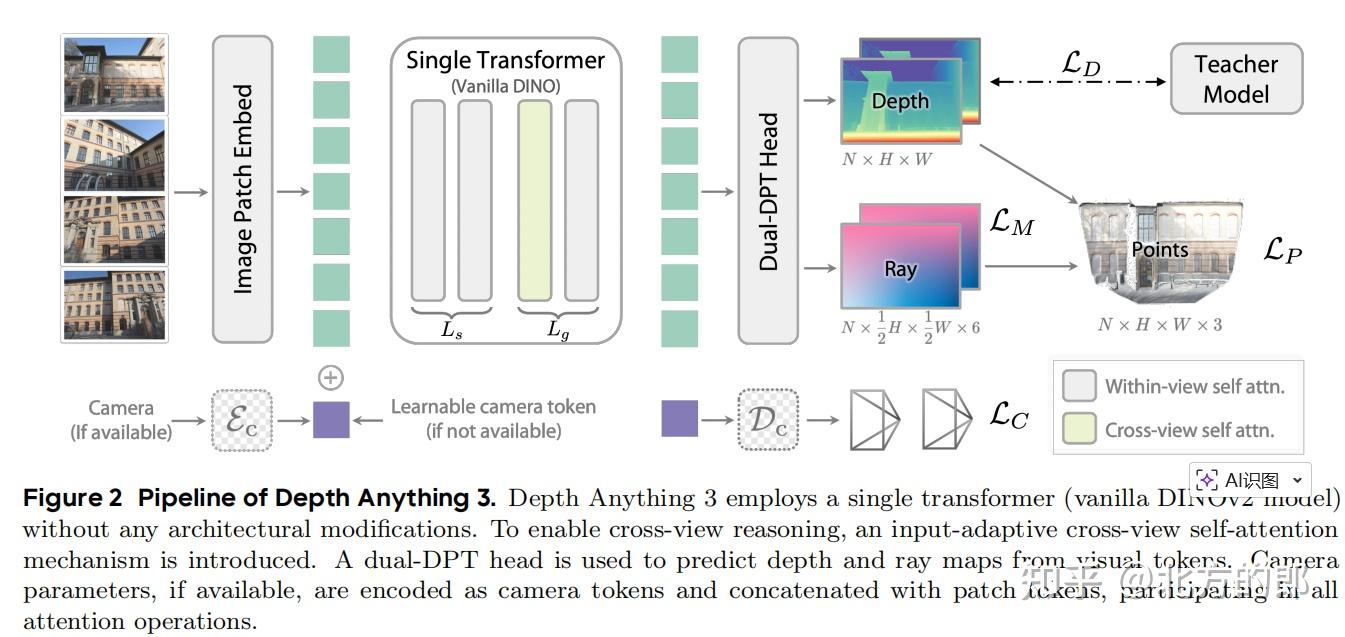
DA3对这两个问题给出了肯定的答案。它创新地提出了一种**“深度-光线”(depth-ray)**的表示方法作为其唯一的预测目标,并证明了仅使用一个标准的视觉Transformer(ViT)作为骨干网络就足以实现最先进的性能。
为了训练这样一个通用模型,DA3采用了一种高效的教师-学生学习范式。一个强大的“教师模型”在海量高质量的合成数据上进行训练,然后为混杂着噪声和稀疏标签的真实世界数据生成高质量的伪标签,从而指导“学生模型”(即DA3)的学习。
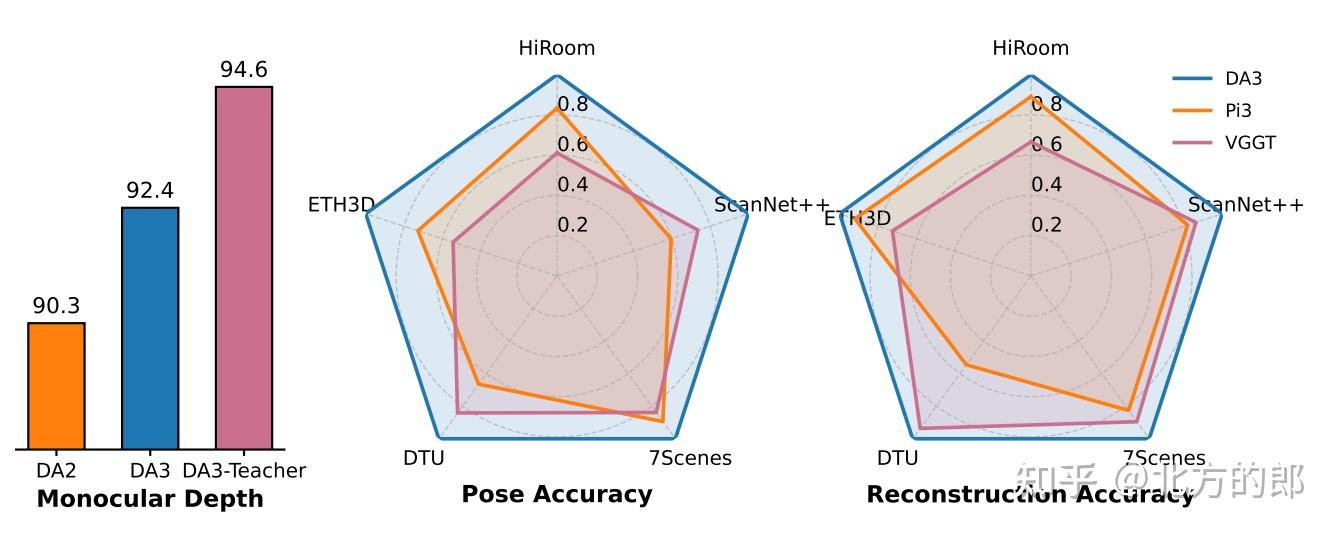
最后,为了公平、全面地评估这类通用几何模型,团队还建立了一个全新的视觉几何基准(Visual Geometry Benchmark),涵盖了相机位姿估计、任意视角几何重建和视觉渲染三大任务。实验结果令人震撼:DA3在该基准上全面超越了之前的SOTA(State-of-the-Art)模型,例如在相机位姿准确率上平均领先VGGT模型35.7%,在几何重建准确率上平均领先23.6%。
第二章:相关工作 (Related Work)
本章回顾了三个主要领域的研究进展,并阐明了DA3与它们的区别。
- 多视角视觉几何估计:传统方法通常遵循一套固定的流水线:特征检测匹配、位姿估计、束调整(Bundle Adjustment)、稠密重建。这些方法在纹理丰富的场景中表现优异,但在弱纹理或大视角变化的场景下则显得脆弱。后续的深度学习方法尝试改进流水线的各个环节,例如学习更好的特征描述子或使用代价体网络(cost-volume networks)。而DA3则完全摒弃了这种模块化的思路,通过一个端到端的Transformer模型直接联合预测深度和位姿,实现了更高的鲁棒性和简洁性。
- 单目深度估计:早期模型依赖于在特定领域(如室内或室外驾驶场景)的数据集上进行监督学习,导致泛化能力差。现代的通用方法则通过在海量多源数据集上训练,并利用ViT等先进架构来学习更广泛的视觉线索。DA3虽然主要目标是统一的多视角任务,但其简洁的架构和强大的教师-学生训练范式,使其在单目深度估计任务上同样表现出色,甚至超越了其前代作品Depth Anything 2。
- 前馈新视角合成 (Feed-Forward Novel View Synthesis, FF-NVS):该领域旨在通过单次网络前向传播从输入图像生成场景的3D表示(如NeRF或3D高斯溅射),从而合成新视角的图像。DA3证明了自己可以作为一个极其强大的几何先验模型(geometry backbone),只需在其后附加一个简单的解码头,就能在FF-NVS任务上超越那些专门设计的复杂模型,这凸显了其作为“基础模型”的巨大潜力。
第三章:Depth Anything 3 模型详解
这是论文的核心技术章节,详细阐述了DA3的数学表述、网络架构和训练策略。
3.1 公式化表述 (Formulation)
DA3的核心创新在于其深度-光线表示法 (depth-ray representation)。传统方法直接预测相机的旋转矩阵(R)和平移向量(t),但旋转矩阵具有正交约束,直接预测非常困难。
DA3巧妙地回避了这个问题。对于输入图像中的每一个像素,模型不直接预测相机位姿,而是预测两样东西:
- 深度图 (Depth Map):每个像素的深度值。
- 光线图 (Ray Map):每个像素对应光线在世界坐标系中的原点 (origin) 和方向 (direction)。
一个三维点 P 可以通过 P = origin + depth * direction 简单地计算出来。这种表示法有两大优势:
- 一致性:通过简单的逐元素操作即可生成一致的点云,避免了复杂的几何变换。
- 简洁性:它将复杂的相机位姿估计问题转化为一个稠密的像素级预测任务,更适合Transformer架构。
论文还给出了如何从预测出的光线图中恢复出传统相机内外参(R, t, K)的方法,证明了这种表示的完备性。作者强调,“深度+光线”是恢复三维空间的一组最小且充分的预测目标。
3.2 模型架构 (Architecture)
DA3的架构体现了极简主义哲学,主要由三部分构成:
- 单一Transformer骨干网络:DA3直接使用了一个在大型图像数据集上预训练好的普通视觉Transformer(如DINOv2),未做任何结构上的修改。为了处理任意数量的输入视图,它采用了一种输入自适应的跨视图自注意力机制。具体来说,Transformer的前 Ls 层在每个视图内部进行自注意力计算,而后 Lg 层则交替地在所有视图的tokens上进行联合(跨视图)注意力和在单个视图内部进行注意力计算。这种设计使得模型在输入多视图时能有效交换信息,而在输入单视图时则自然退化为单目模型,无需任何额外开销。
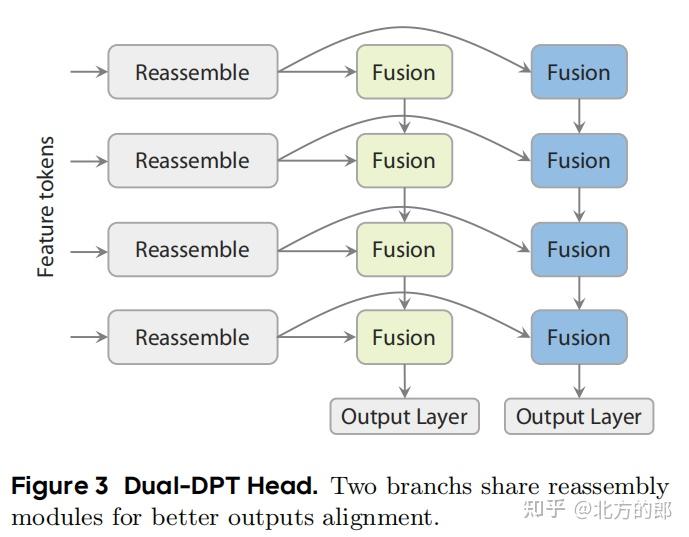
- 双分支DPT解码头 (Dual-DPT Head):为了从Transformer提取的特征中同时预测深度图和光线图,DA3设计了一个新颖的解码头。该解码头首先通过一组共享的模块处理特征,然后分为两个分支,分别用不同的融合层来生成最终的深度图和光线图。这种设计鼓励两个任务之间进行强交互,同时避免了中间表示的冗余。
- 可选的相机编码器:为了增加灵活性,当外部提供相机位姿时,DA3可以通过一个轻量级的MLP将其编码成一个特殊的token,并与图像的patch tokens拼接在一起,参与所有的注意力计算,从而为模型提供明确的几何约束。
3.3 & 3.4 训练与实现细节 (Training & Implementation Details)
DA3的训练核心是教师-学生学习范式。由于真实世界数据集的深度标签通常是稀疏的(如COLMAP重建)或充满噪声的(如LiDAR),直接用于监督学习效果不佳。

DA3的策略是:
- 训练教师模型:首先,仅在海量、多样化、高质量的合成数据集上训练一个强大的单目相对深度预测模型,称之为“教师模型”(DA3-Teacher)。
- 生成伪标签:用训练好的教师模型为所有真实世界数据预测出稠密且精细的相对深度图。
- 对齐与监督:通过RANSAC等鲁棒算法,将教师生成的相对深度图与真实世界数据中稀疏或有噪声的绝对深度值进行对齐(尺度和偏移量),生成高质量的伪标签。
- 训练DA3:最后,用这些高质量的伪标签来监督DA3(学生模型)的学习。
这种方法极大地提升了标签的质量和稠密度,同时保留了原始数据的几何准确性。论文还公布了详细的训练参数,例如模型在128块H100 GPU上训练了200k步,使用了动态批处理大小和多种分辨率的数据增强。
第四章:教师-学生学习策略详解
本章进一步阐述了教师-学生范式的细节,尤其是如何构建一个比前代(DA2)更强大的教师模型。
- 数据规模扩展:相比DA2,DA3的教师模型使用了更多样化的合成数据集,涵盖室内、室外、以物体为中心等多种场景,显著提升了模型的泛化能力。
- 深度表示优化:DA2的教师模型预测的是“视差”(disparity),而DA3的教师模型直接预测“深度”(depth),这更适合下游的几何任务。为了解决深度值在近距离区域不敏感的问题,模型预测的是指数深度,从而增强了在近处的区分度。
通过这些改进,DA3-Teacher模型不仅在各项指标上超越了DA2,更能生成几何结构更真实、伪影更少的点云。
第五章:应用:前馈3D高斯溅射
为了展示DA3作为基础模型的强大能力,研究团队将其应用于当前热门的新视角合成 (NVS) 任务中,具体是基于3D高斯溅射 (3D Gaussian Splatting, 3DGS) 的方法。
他们仅在DA3的骨干网络后增加了一个轻量级的解码头(GS-DPT),用于预测每个像素对应的3D高斯球的参数(如不透明度、旋转、缩放、颜色等)。通过在NVS任务上进行微调,DA3展现出了惊人的性能,显著优于那些为NVS专门设计的、结构更复杂的模型。
特别值得一提的是,他们还提出了一个位姿自适应 (Pose-Adaptive) 版本,该版本与DA3使用完全相同的预训练权重,能够无缝处理带位姿和不带位姿的输入,极大增强了模型的实用性。
第六章:视觉几何基准 (Visual Geometry Benchmark)
为了系统地评估DA3这类通用模型的性能,作者提出了一个全新的、全面的评测基准。该基准包含三大流程:
- 位姿估计评测:模型输入多张图片,输出每张图片的相机位姿,并与真实位姿对比,使用AUC(曲线下面积)作为核心指标。
- 几何重建评测:使用模型预测的位姿和深度图,融合成三维点云,并与真实的场景点云进行比较。使用F1分数和倒角距离(Chamfer Distance)作为指标。
- 视觉渲染评测:用于评估NVS任务,通过渲染新视角的图像并与真实图像对比,使用PSNR, SSIM, LPIPS等指标。
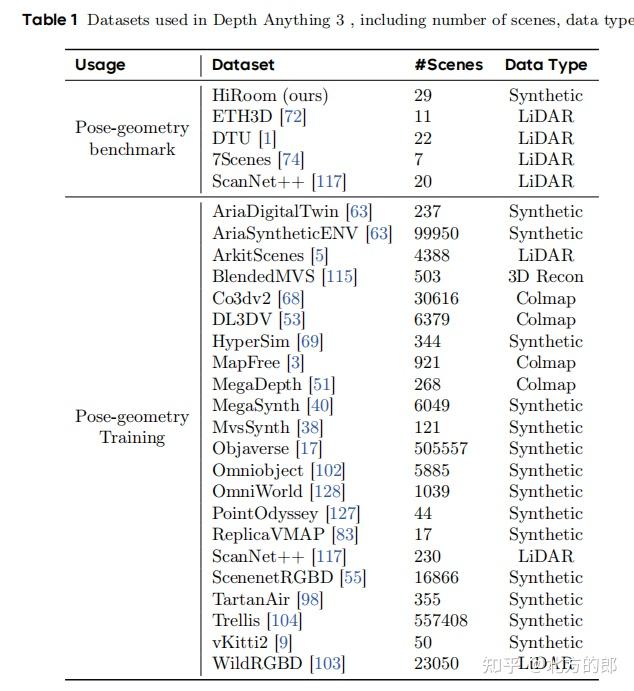
该基准整合了5个广为使用的数据集,包括HiRoom(合成)、ETH3D、DTU、7Scenes和ScanNet++,覆盖了从物体级别到室内外大场景的各种情况。
第七章:实验与分析 (Experiments)
本章是论文的“成果展示”环节,通过大量的定量和定性比较,证明了DA3的卓越性能。
7.1 与SOTA模型的对比
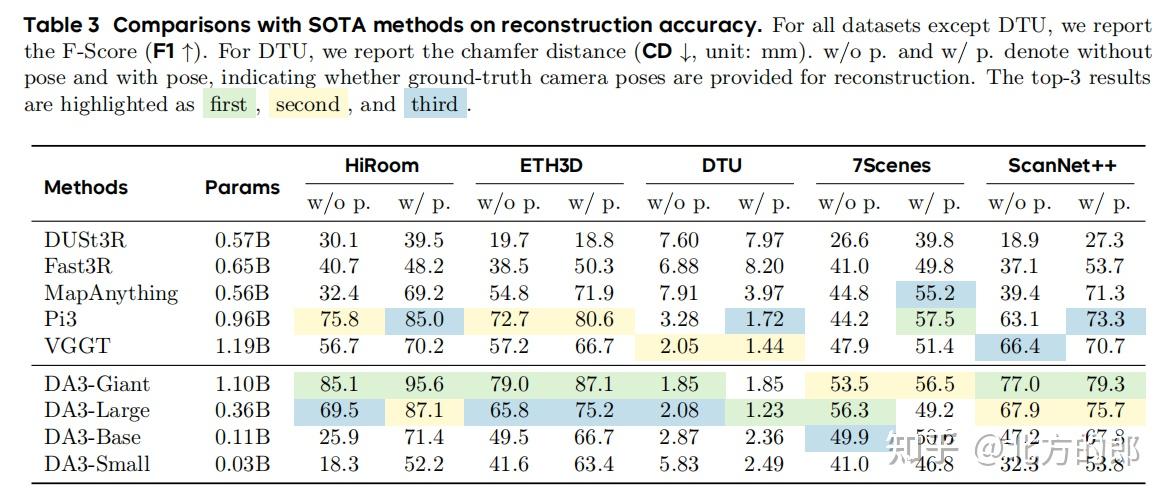
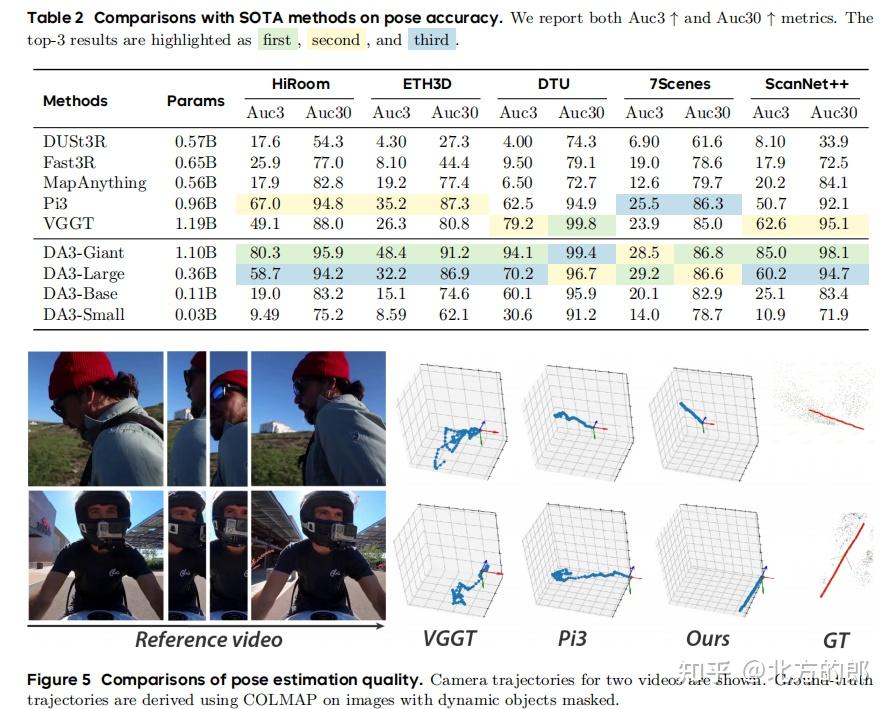
- 位姿与几何精度:如表2和表3所示,DA3-Giant模型在几乎所有数据集和所有指标上都达到了新的SOTA。相较于之前的最强模型VGGT和Pi3,DA3在位姿精度上实现了35.7%的平均提升,在几何重建精度上实现了21.5%(对Pi3)的平均提升。即使是参数量比VGGT小3倍的DA3-Large模型,也在多个设定下超越了VGGT,展示了极高的效率。
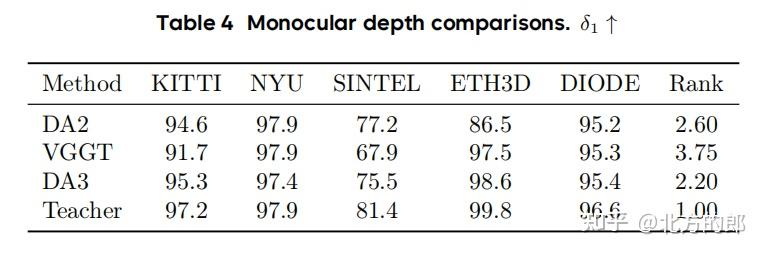
- 单目深度精度:如表4所示,在标准的单目深度估计基准上,DA3的表现优于其前身DA2和强劲对手VGGT。其教师模型DA3-Teacher更是达到了接近完美的性能。

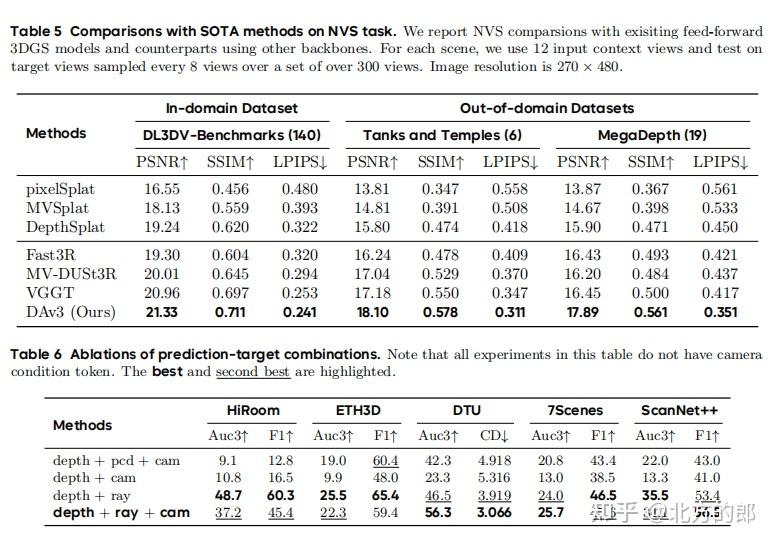
- 新视角合成:如表5所示,以DA3为骨干的NVS模型在所有数据集上均优于其他方法,证明了强大的几何理解能力对渲染质量的直接助益。
7.2 模型分析(消融实验)
为了验证各个设计选择的有效性,作者进行了一系列消融实验:
- 预测目标的充分性:实验(表6)证明,“深度+光线”的组合显著优于其他预测目标组合(如“深度+点云+相机参数”)。增加一个额外的相机参数预测头并不能带来性能提升,证实了“深度+光线”表示的充分性和简洁性。
- 单一Transformer架构的优越性:与VGGT风格的堆叠式Transformer架构相比,DA3的单一Transformer设计在参数量相似的情况下性能高出约20%,这得益于其骨干网络可以被完整地预训练。
- 关键组件的有效性:实验还分别验证了双分支DPT解码头、教师模型监督以及位姿条件注入模块的有效性,移除任何一个都会导致性能的显著下降。
定性结果(图6、图7)同样令人印象深刻,DA3生成的深度图细节更丰富、语义更准确,重建的点云也更规整、噪声更少。
第八章:结论与展望 (Conclusion and Discussion)
Depth Anything 3成功证明,一个简洁的、基于Transformer的统一模型,通过巧妙的深度-光线表示和高效的教师-学生学习范式,可以有效地解决从任意视角恢复三维几何这一基本问题。它不仅在位姿估计和三维重建任务上创造了新的技术高峰,还展示了作为下游任务(如新视角合成)强大基础模型的巨大潜力。
DA3为通用的3D基础模型铺平了道路。未来的工作可以将DA3的能力扩展到动态场景,融合语言和交互指令,并探索更大规模的预训练,最终实现一个能够像人一样理解并与三维世界交互的智能体。DA3及其开源的模型、基准和简洁的设计理念,无疑将催化通用3D感知领域的进一步研究与发展。
实际效果测试
Demo地址:https://huggingface.co/spaces/depth-anything/depth-anything-3
简单测试了一下,感觉效果还不错
——完——
@北方的郎 · 专注模型与代码
喜欢的朋友,欢迎赞同、关注、分享三连 ^O^

















 1163
1163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









