




模型调优
大语言模型调优是通过准备训练数据,并在已有的预训练模型上进行调优,包括 llama、千问等模型,从而可以让模型学习到私有知识或者增强模型的已有知识。因此,如果要想训练一个效果好的模型,我们就需要提供大量的训练数据,数据格式包括问题和答案,例如下面这个例子,这种方式叫做 SFT(Supervised Fine Tuning):
{
"instruction": "列举消费者决策过程的五个阶段。",
"input": "",
"output": "消费者决策过程的五个阶段包括问题识别阶段、信息搜索阶段、替代方案评估阶段、购买决策阶段和购后评估阶段。在问题识别阶段,消费者会感知到需求并开始搜索信息。在信息搜索阶段,消费者会寻找更多信息来帮助他们选择产品。在替代方案评估阶段,消费者会评估可用选择并权衡各种选项。在购买决策阶段,消费者会做出购买决策。最后,在购后评估阶段,消费者会评估自己的购买,并决定是否满意自己的决策,或者是否需要再次购买。"
},
{
"instruction": "改写给定句子,使用适当的隐喻使其具有与原句相同的意义。",
"input": "跳入游泳池就像是跳入冰水中一样。",
"output": "跳入游泳池就像跳入冰浴中一样。"
},
上面这两条是取自alpaca_data_zh_51k中文数据集。SFT 并不能保证模型的回答和用户想要一致,RLHF(reinforcement learning from human feedback),这种方式是通过用户反馈对模型的参数进行调优,本文将介绍RLHF 中的 DPO 和 PPO 两种方式是如何进行调优的。
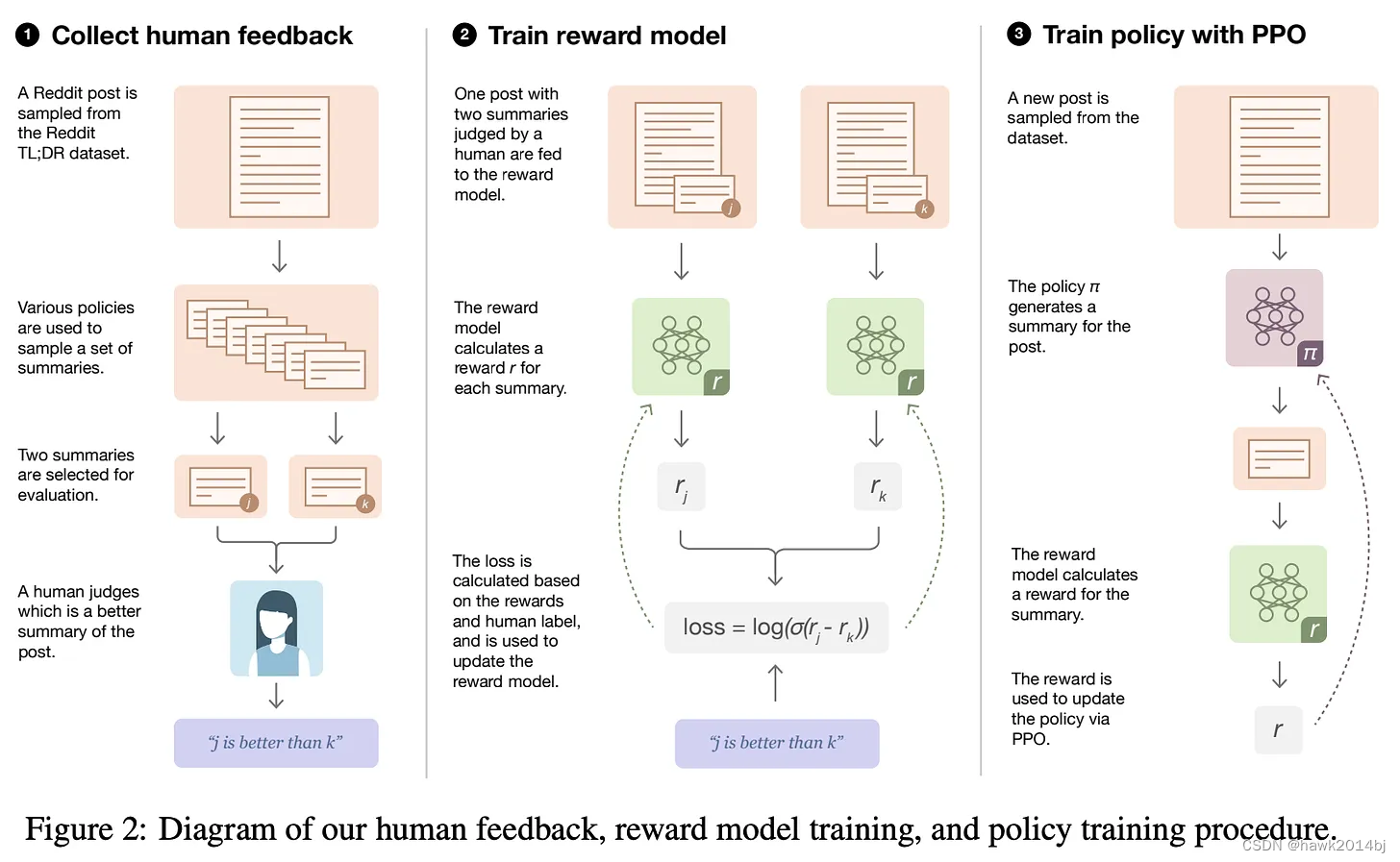
PPO(Proximal Policy Optimization)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









