







 本文介绍了一种自动化测试方法,该方法通过解析Excel文件中的SQL语句及其预期结果来进行数据库查询,并验证实际结果与预期结果的一致性。该方案利用Python实现,包括从Excel读取数据、执行SQL查询、比对结果等关键步骤。
本文介绍了一种自动化测试方法,该方法通过解析Excel文件中的SQL语句及其预期结果来进行数据库查询,并验证实际结果与预期结果的一致性。该方案利用Python实现,包括从Excel读取数据、执行SQL查询、比对结果等关键步骤。
一、创建utils.文件
import xlrd,pymysql
#从excle中生成sqls列表和查询参数、期望结果
def gen_sqls_queryparms_expectresult(excel_file_path, sheet_name):
sql_list=[]
with xlrd.open_workbook(excel_file_path) as f:
table = f.sheet_by_name(sheet_name)
#print(table.col_values(0))
sql_col=table.col_values(0)
query_parms_col=table.col_values(1)
expect_result_col=table.col_values(2)
#print(query_parms_col)
#获取sqls
for i in range(0,len(sql_col)):
if 'begin' in sql_col[i]:
sql=sql_col[i].split(':')[1]
sql_list.append(sql)
#获取每个sql查询字段
query_parms=[x for x in query_parms_col if x !='']
# 获取每个sql查询字段对应的期望结果
expect_result = [x for x in expect_result_col if x != '']
return sql_list,query_parms,expect_result
#将列表中无用的标识头部去除工具
def deal(list_ori,p):
list_new=[] #处理后的列表,是一个二维列表
list_short=[] #用于存放每一段列表
for i in list_ori:
if i!=p:
list_short.append(i)
else:
list_new.append(list_short)
#print(list_new)
list_short=[]
list_new.append(list_short) #最后一段遇不到切割标识,需要手动放入
list_new=[a for a in list_new if a!=[]]
return list_new
#将查询字段和期望结果构建成字典结构
def parms_mix_result(x,y):
parms_mix_result=[]
for i in range(0,len(x)):
dict1=dict(zip(x[i],y[i]))
parms_mix_result.append(dict1)
return parms_mix_result
# 封装SQL语句函数
def func(sql,args=None):
# 打开数据库
py = pymysql.connect(host="localhost", user="root", password="123456", db="forum", port=3306,
use_unicode=True, charset="utf8",cursorclass=pymysql.cursors.DictCursor)
cursor = py.cursor ()
try:
cursor.execute (sql,args)
data = cursor.fetchall()
py.commit()
except:
data = False
py.rollback ()
py.close ()
return data
#将sql查询结果包含字段的结果value和excle中对应字段的期望结果value分别封装成2个列表,并且将它们构建一个二维数组
def query_result_list(sql_list,parms_mix_result):
query_list=[]
result_list=[]
for i in range (0,len(sql_list)):
aa=func(sql_list[i])
bb = list(parms_mix_result[i].keys())
for cc in bb:
#期望结果
expect_result=parms_mix_result[i][cc]
print(expect_result)
#SQL查询结果包含字段的结果
sql_query_result=aa[0][cc]
print(sql_query_result)
query_list.append(sql_query_result)
result_list.append(expect_result)
#将查询的结果与期望结果构建一个二维数组,待后面校验结果断言用
new_list=list(zip(query_list,result_list))
return new_list
二、准备测试数据(excle,mysql)
2.1 excel测试用例数据
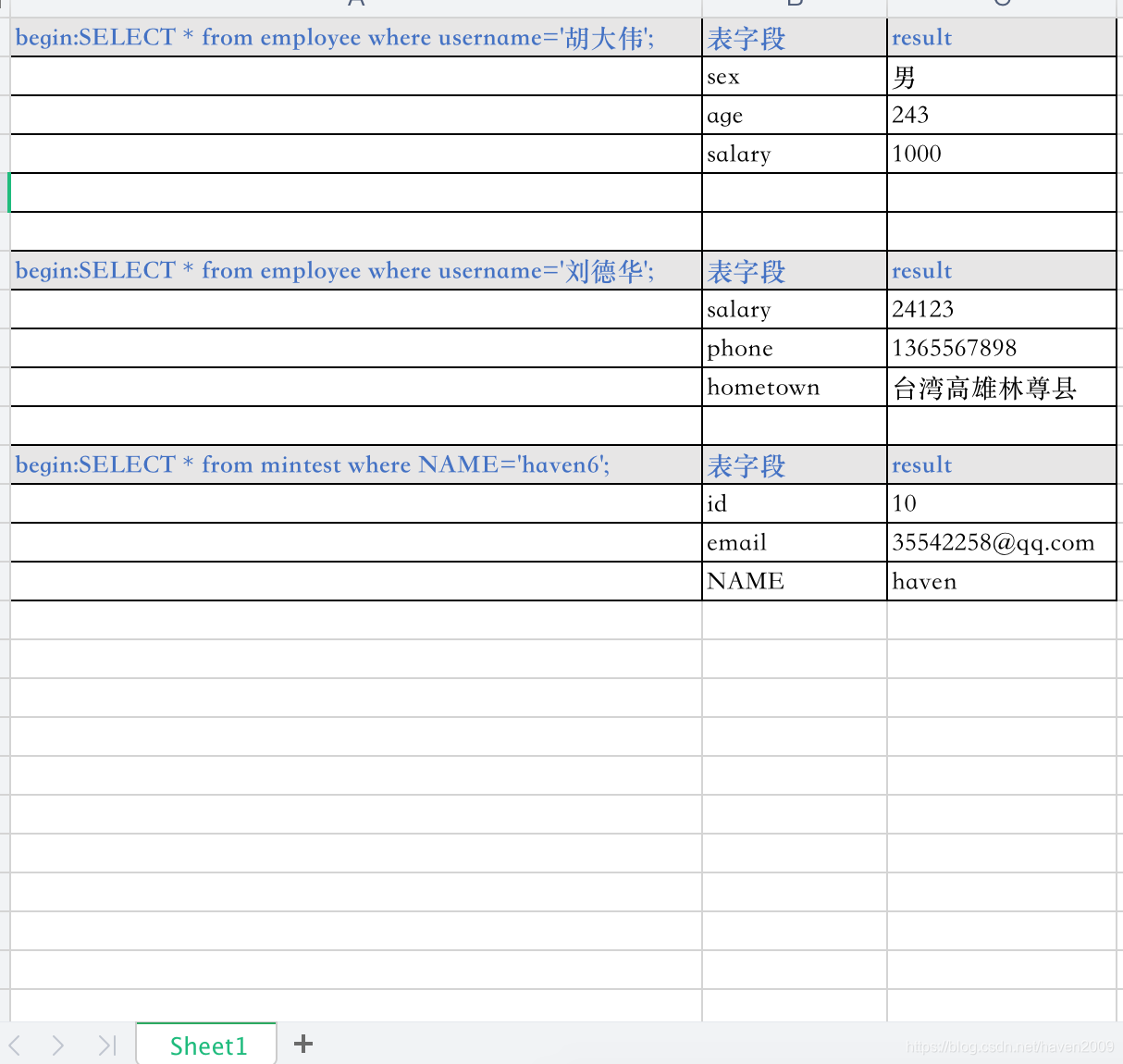
2.2 准备employee表数据
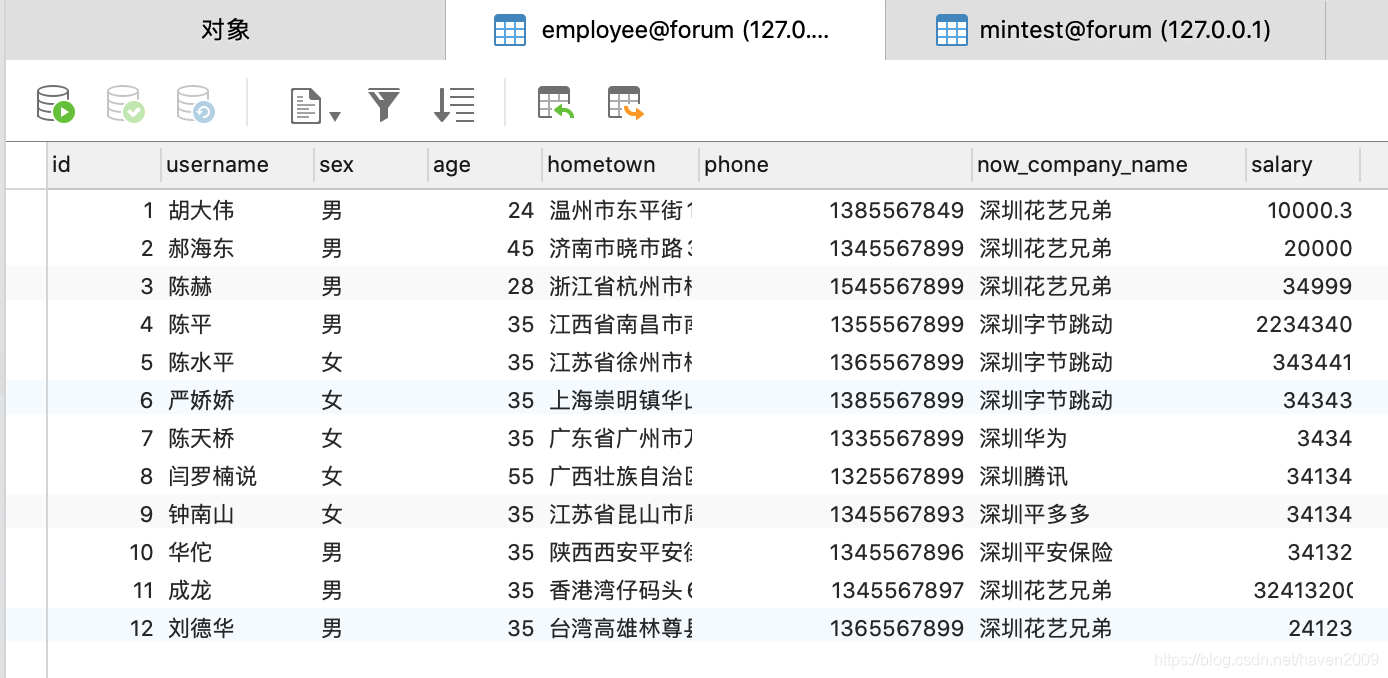
2.3 准备mintest表数据
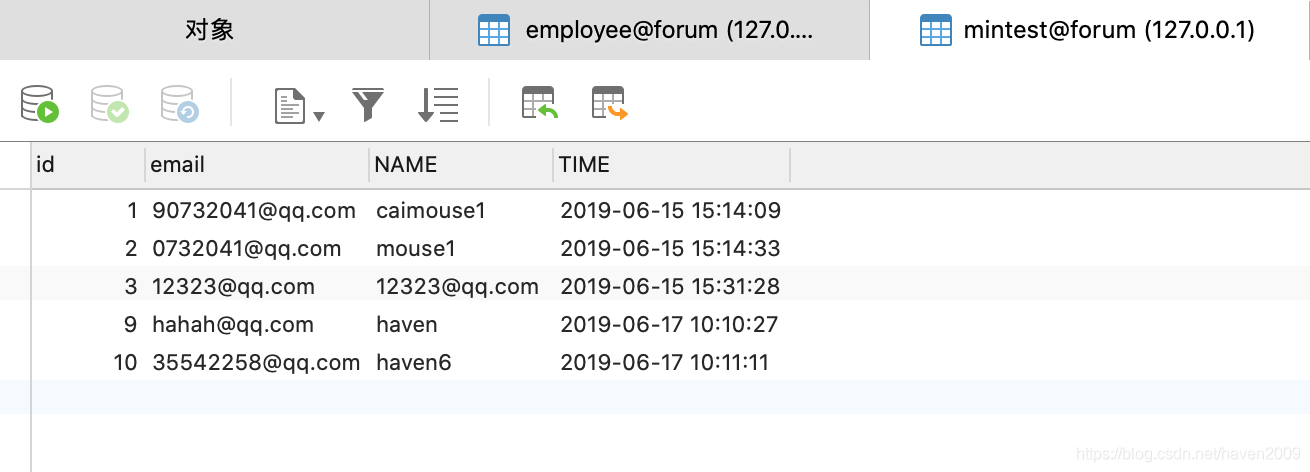
三、测试用例脚本test_case.py
import pytest
from utils import *
file_path = "/Users/ldd/Downloads/myjob/add_example.xlsx"
sheet_name = "Sheet1"
#从excle中生成sqls列表和查询参数、期望结果
sql_list,query_parms,query_parms_expect_result=gen_sqls_queryparms_expectresult(file_path,sheet_name)
#print(sql_list,query_parms,query_parms_expect_result)
#将列表中无用的标识头部去除工具
x=deal(query_parms,'表字段')
#print(x)
y=deal(query_parms_expect_result,'result')
#print(y)
#将查询字段和期望结果构建成字典结构
parms_mix_result=parms_mix_result(x,y)
#print("parms_mix_result",parms_mix_result)
#将sql查询结果包含字段的结果value和excle中对应字段的期望结果value分别封装成2个列表,构建一个二维数组
new_list=query_result_list(sql_list,parms_mix_result)
@pytest.mark.parametrize("a,b",new_list)
def test_case(a,b):
assert a==b
四、终端运行测试用例脚本
$ pytest /Users/ldd/Downloads/myjob/huahua/test_case.py -v


















 1584
1584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









