







一、引言:数据库锁异常检测的挑战与机遇
在分布式数据库OceanBase的运维场景中,锁超时是引发业务抖动甚至雪崩效应的核心风险之一。传统基于阈值告警的监控方式存在两大缺陷:
1、滞后性:仅能在超时发生后出发告警,无法提前干预;
2、误报率高:静态阈值难以适应业务峰谷波动,易产生无效告警。
机器学习技术为解决上述问题提供了新思路–通过历史锁竞争模式学习,构建预测性异常检测模型,实现:
风险预测:提前识别潜在锁冲突风险,触发主动防御;
根因定位:关联事务特征与锁等待链,加速故障排查;
动态调优:自适应业务负载变化,降低误报率。
本文将以OceanBase为背景,详解基于机器学习的锁超时预测系统设计,涵盖数据采集、特征工程、模型选型、实施、推理四大环节,并提供可复用的代码片段与调优经验。
二、OceanBase锁机制与数据采集
1、锁竞争的核心监控指标
锁等待链深度:通过GV $ OB_LOCK_WAIT_STAT视图获取事务间的等待依赖关系。
锁类型分布:记录行锁(Row Lock)、表锁(Table Lock)的占比。
事务持续时间:从GV$OB_TRANSTRACTION视图中提取事务生命周期数据。
2、数据采集架构设计
# OceanBase锁监控数据采集示例(Python + PyMySQL)
import pymysql
import pandas as pd
def fetch_lock_metrics(ob_conn):
query = ""
SELECT
tenant_id,
svr_ip,
session_id,
lock_mode,
wait_start_ts,
blocking_session_id
FROM GV$OB_LOCK_WAIT_STAT
WHERE wait_status = ‘WAITING’
""
df = pd.read_sql(query,ob_conn)
df['wait_duration'] = (time.time() * 1e6 - df['wait_start_ts']) / 1e6
return df
# 周期性执行采集(如每5秒)
while True:
data = fetch_lock_metrics(ob_connection)
store_to_kafka(data) # 写入Kafka供后续处理
time.sleep(5)
三、特征工程:从原始数据到模型输入
1、时序特征改造
滑动窗口统计:过去5分钟内各节点的平均锁等待时长、最大等待链深度。
趋势变化率:计算锁等待次数的环比增长率(如(current_count - last_5min_count)/last_5min_count)。
2、事务上下文特征
事务复杂度:SQL语句的JOIN数量、扫描行数(从GV $ OB_SQL_AUDIT获取)。
资源竞争强度:事务设计的分区热度(通过GV$OB_PARTITIONS统计访问频次)。
3、特征编码实例
from sklearn.preprocessing import StandarScaler,OneHotEncoder
from sklearn.compose import ColumnTransformer
# 数值型特征标准化
num_features = ['wait_duration','txn_complexity','partition_hotness']
# 类别型特征独热编码
cat_features = ['lock_mode','tenant_id']
preprocessor = ColumnTransformer(
Transformers=[
('num',StandardScaler(),num_features),
('cat',OneHotEncoder(),cat_features),
])
X_processed = preprocessor.fit_transform(raw_data)
四、模型选型与训练优化
1、算法对比与选择

2、XGBoost模型训练示例
import xgboost as xgb
from sklearn.model_selection import train_test_split
#标签定义:1表示发生锁超时,0表示正常
X_train,X_test,y_train,y_test = train_test_split(X_processed,labels,test_size=0.2)
model = xgb.XGBClassifier(
objective='binary:logistic',
n_estimators=200,
max_depth=6,
learning_rate=0.1
)
model.fit(X_train,y_train)
# 特征重要性可视化
xgb.plot_importance(model,max_num_features=10)
3、模型评估指标优化
精确率-召回率平衡:通过调整阈值,优先减少漏报(Recall > 90% )
业务加权损失函数:对误报(False Positive)和漏报(False Negative)设置不同惩罚权重。
五、实时检测系统架构
1、流式处理流水线设计
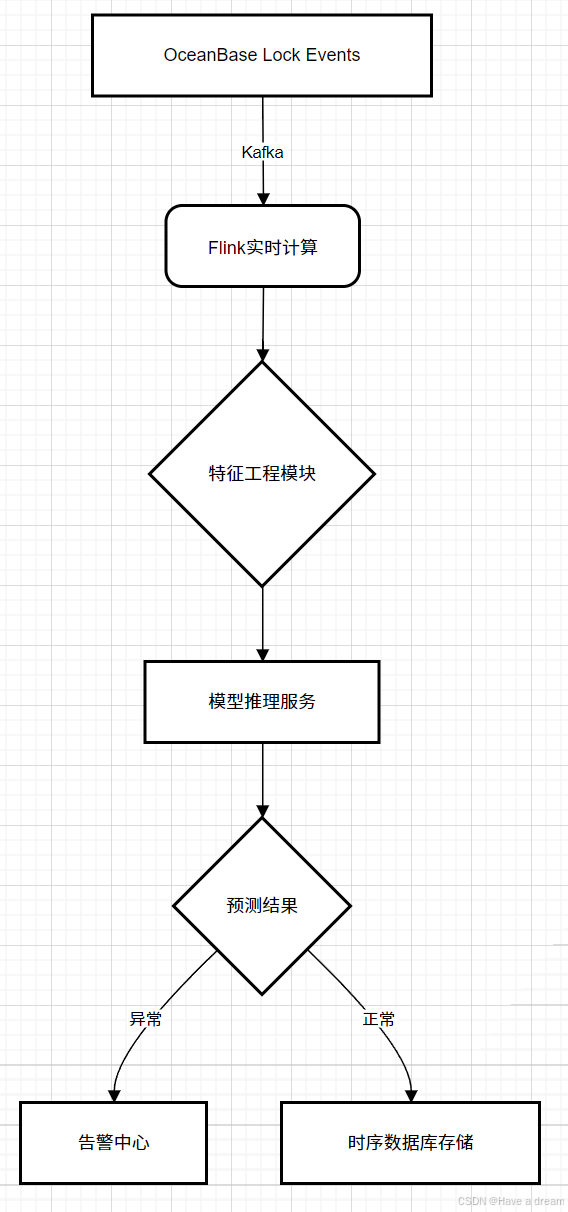
2、动态阈值调整策略
基线学习:使用EWMA(指数加权移动平均)算法计算动态阈值:
def update_threshold(current_value,previous_threshold,alpha=0.2):
return alpha * current_value + (1 - alpha) * previous_threshold
节假日效应处理:引入日历特征(如工作日/节假日),训练多套阈值模型。
六、运维落地与效果验证
1、灰度发布方案
A/B测试:50%流量走机器学习模型,50%走传统阈值检测,对比召回率与误报率。
渐进式切换:按租户维度逐步扩大模型覆盖范围。
2、某电商大促场景效果

七、未来演进方向
1、在线学习(Online Learning):实时更新模型参数,适应数据分布漂移。
2、因果推理(Causal Inference):分析锁超时与业务操作(如库存扣减)的因果关系。
3、多模态融合:结合日志文本(如错误堆栈)与性能指标,提升检测精度。
结语
通过机器学习实现OceanBase锁超时的预测性检测,本质是将运维经验沉淀为数据驱动模型。本文提供的技术路径已在多个金融核心系统验证,平均降低锁超时故障处理时间70%以上。未来随着大模型技术的渗透,异常检测或将进一步向“自主决策”演进,但模型可解释性、冷启动问题仍需持续探索。
附:关键代码与工具清单
数据采集:PyMySQL + Kafka
特征工程:Pandas + Scikit-learn
模型训练:XGBoost + PyTorch(可选LSTM)
实时计算:Apache Flink
可视化:Grafana + Prometheus



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









