 强化学习Q表计算实践
强化学习Q表计算实践





 本文探讨了强化学习的基本原理,通过Python和numpy实现Q表的计算。在不同学习率下,Q表的收敛速度和稳定性有所不同。实验结果显示,学习率分别为0.6和0.8时,经过2100次迭代,Q值达到稳定,用于指导行动选择。
本文探讨了强化学习的基本原理,通过Python和numpy实现Q表的计算。在不同学习率下,Q表的收敛速度和稳定性有所不同。实验结果显示,学习率分别为0.6和0.8时,经过2100次迭代,Q值达到稳定,用于指导行动选择。
1原理
强化学习就是计算Q表,待Q表稳定之后用来为action服务




2代码
# -*- coding: utf-8 -*-
import numpy as np
import time
u=0.6#学习率
#构建Reward矩阵
R=np.zeros([6,6])
R[0]=[-1,-1,-1,-1,0,-1]
R[1]=[-1,-1,-1,0,-1,100]
R[2]=[-1,-1,-1,0,-1,-1]
R[3]=[-1,0,0,-1,0,-1]
R[4]=[0,-1,-1,0,-1,100]
R[5]=[-1,0,-1,-1,0,100]
#构造一个Q表
Q=np.zeros([6,6])
def getMaxQ(s,a):#返回最大的Q
l=[]
for i in range(6):
if R[a][i]!=-1:
l.append(Q[a][i])
return max(l)
def calcQ(s,a):#计算Q表
su=0
su+=R[s][a]
return su+u*getMaxQ(s, a)
def calc_a(s):#给出随机返回a,后面计算Q表用
l=[]
for i in range(6):
if R[s][i]!=-1:
l.append(i)
n=len(l)
#print(l)
a=np.random.randint(n)
return l[a]
def main():
for i in range(2100):
s=np.random.randint(6)
a=calc_a(s)
Q[s][a]=calcQ(s,a)
if __name__ == '__main__':
main()
print(Q)
3总结
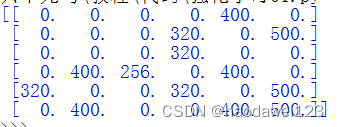
通过计算发现不同的学习率最终得到的Q是不一样的,我们只需要在S状态从Q表里面选取最大的A去执行就可以了
下面是u=0.6经过2100次计算后Q值达到稳定

下面是u=0.8经过2100次计算Q值稳定后的结果


















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









