




大家读完觉得有帮助记得关注和点赞!!!
抽象
尽管进行了广泛的调整工作,大型视觉语言模型 (LVLM) 仍然容易受到越狱攻击,带来严重的安全风险。尽管最近的检测工作由于其丰富的跨模态信息而转向内部表示,但大多数方法依赖于启发式规则而不是原则性目标,导致性能不理想。 为了解决这些局限性,我们提出了学习检测 (LoD),这是一种新型的无监督框架,将越狱检测表述为异常检测。LoD 引入了两个关键组件:多模态安全概念激活向量 (MSCAV),它捕获跨模态的层级安全相关表示,以及安全模式自动编码器,它对来自安全输入的 MSCAV 的分布进行建模,并通过重建错误检测异常。通过仅在没有攻击标签的安全样本上训练自动编码器 (AE),LoD 自然地将越狱输入识别为分布异常,从而能够准确、统一地检测越狱攻击。 对三种不同 LVLM 和五个基准的综合实验表明,LoD 实现了最先进的性能,平均 AUROC 为 0.9951,与最强基线相比,最小 AUROC 提高了 38.89%。
介绍
近年来,大型视觉语言模型(LVLM)发展迅速(张等人。202420242024),但它们对视觉模块的集成带来了重大的安全风险(顾等人。202420242024;罗等人。202420242024).最近的研究表明,LVLM 仍然极易受到越狱攻击,攻击成功率高达 96%(王等人。202420242024). 与大型语言模型 (LLM) 不同,LVLM 接受形成连续、高维攻击面的视觉输入,其中图像中细微的对抗扰动可以绕过安全过滤器而无法察觉(齐等人。202420242024).
为了减轻 LVLM 中的安全漏洞,各种检测方法已成为一种有前途的防御策略,旨在识别用户输入中潜在的越狱尝试。 先锋方法主要利用模型输入和输出进行攻击检测(徐等人。2024a2024a2024a;阿隆和坎福纳斯202320232023;张等人。202520252025). 最近,研究人员发现,该模型的内部表示 捕获复杂的跨模态语义并实现检测性能改进(谢等人。202420242024;江等人。202520252025). 虽然这些新兴方法显示了内部表示在为攻击检测提供细粒度信息方面的前景,但它们无法实现对所有类型的越狱攻击的稳健检测(例如,基于对抗性扰动的攻击和基于提示纵的攻击,分类为(刘等人。2024a2024a2024a))由于其启发式性质。这些方法没有学习最佳参数来区分攻击的内部模式和安全输入,而是直接采用可能有偏差的启发式规则来识别攻击,这不需要任何额外的学习或优化目标。 例如,HiddenDetect(江等人。202520252025)如果模型的内部表示更接近拒绝标记的内部表示(例如,“抱歉”)而不是安全输入的余弦相似性,则认为模型受到攻击。 缺乏主要优化目标以及对内部表示模式的潜在偏差理解会导致性能不佳。例如 在某些攻击中,HiddenDetect 的 AUROC 下降到大约 0.7(见表 111)。 这些方法更倾向于启发式规则而不是基于学习的策略,因为监督学习需要攻击分布和标签,这些分布和标签被有意视为未知,以防止过度拟合特定的攻击类型。
在本文中,我们通过提出一种在不知道具体攻击方法的情况下获得 L赚取 to Detect (LoD) 的方法来解决上述挑战, 实现准确和统一的检测,即一种单一、一致的方法,可泛化各种攻击,包括尚未开发的攻击。 基本思想是通过无监督学习来检测攻击。这是通过将攻击检测表述为异常检测问题来实现的,其中攻击被视为内部模式与正常安全输入的内部模式显着不同的异常。这里的关键是学习安全激活模式的准确表示 (G1) 以及将安全激活模式与攻击激活模式区分开来的有效措施 (G2)。前者(G1)是通过学习多模态安全概念激活向量(MSCAV)来实现的,该向量扩展了法学硕士的安全概念激活向量(SCAV)(徐等人。2024b2024b2024b)到多模态场景。MSCAV 通过忠实地解释模型的内部安全机制,准确估计模型认为输入在所有层都是不安全的概率,从而提供细粒度的层级信息,从而能够准确分离安全输入和攻击。 后一个目标(G2)是通过提出一种安全模式自动编码器来实现的,该编码器是通过使用仅安全输入的MSCAV以无监督方式学习的,而不依赖于有关攻击的信息。 自动编码器 (AE) 的重建误差是异常检测的良好衡量标准(樱田和亚伊里201420142014):低重建误差对应于 AE 充分建模的安全输入,而高重建误差对应于 AE 尚未学习的攻击(异常)。
总的来说,我们的贡献可以概括为:
- 多模态安全概念激活向量,提供细粒度的分层信息,通过忠实地解释模型的安全机制,能够准确分离安全输入和攻击。
- 安全模式自动编码器,仅使用安全输入来学习,但它们的重建错误为攻击(异常)提供了有效的措施。
- 综合实验表明,我们的方法无需任何攻击类型的先验知识即可实现最先进的越狱检测性能。我们报告说,AUROC 对三种模型中的每一种都进行了五种攻击方法的平均值,得分范围为 0.9943 至 0.9969。与最强基线相比,这对应于最低 AUROC 的相对改进高达 38.89%,平均 AUROC 的相对改进高达 18.21%。
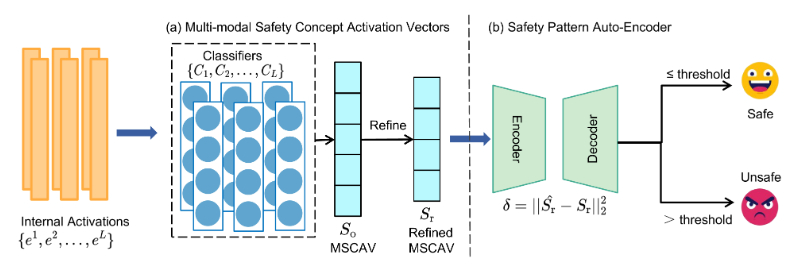
图 1:学习检测管道概述。 我们的方法利用内部激活作为输入,利用其丰富的信息来检测攻击。这些激活通过一组特定于层的分类器转换为多模态安全概念激活向量 (MSCAV),每个分类器都会产生作为层安全特征的连续输出。 为了提高可靠性,我们从在区分验证数据上的安全输入和自然有害(非攻击)输入方面表现不佳的层中删除输出,确保只保留信息量最大的表示。 然后,将精细的 MSCAV 输入安全模式自动编码器,该编码器专门针对安全样本进行训练,以有效地模拟安全和对抗性 MSCAV 模式之间的差异。最后,自动编码器通过在精细化的MSCAV上计算重建误差来检测越狱攻击,从而能够在不同攻击场景下进行准确检测。
方法论
问题定义
给定一个 LVLM,我们的目标是根据模型的内部激活来识别越狱攻击。在本文中,我们区分了两种类型的不安全输入:自然有害内容(例如,暴力图像和指令)和恶意内容,后者涉及故意和对抗性越狱攻击。
输入:我们的方法将中间激活作为输入11这是指每个变压器层输出端的隐藏状态。 {𝐞1,…,𝐞L},其中每个𝐞l∈𝐑d表示多模态输入的激活向量我在l-th 层。 这些激活是通过我通过 LVLMf和d表示模型的隐藏尺寸。
输出:基于内部激活,我们的方法确定多模态输入是否我包含越狱攻击。我们将越狱攻击定义为任何输入作,这些作诱导模型生成违反其安全一致性的响应,这与文献中的先前定义一致(刘等人。2024a2024a2024a).我们的方法不依赖于特定越狱方法的先验知识,使其能够在看不见的对抗性场景中进行推广。
方法概述
我们的学习检测 (LoD) 框架如图 111 所示。 它将派生自我并预测是否我包含越狱攻击。 我们没有使用原始激活,而是通过一组特定于层的分类器将它们转换为多模态安全概念激活向量(MSCAV),这些分类器提供了准确和细粒度的安全表示,用于区分安全输入和攻击。 MSCAV 的每个元素都估计模型考虑的概率我不安全的。 然后将 MSCAV 输入安全模式自动编码器,以便在未知越狱场景中实现无监督检测。 自动编码器 (AE) 专门针对安全样品进行训练,并通过计算重建误差来执行异常检测。 对抗性输入偏离了学习到的安全分布,因此被视为异常。AE的重建损失可以作为异常检测的有效措施(樱田和亚伊里201420142014). 在以下部分中,我们将详细介绍这两个关键组件:多模态安全概念激活向量和安全模式自动编码器。
多模态安全概念激活载体
该模块旨在从激活中提取最具辨别性的信息,以区分安全和对抗性输入。 实现这一目标需要转换激活{𝐞1,…𝐞L}过滤掉与安全无关的特征(例如,主题或一般语义),仅保留与安全相关的表示。然而,现有的方法未能实现这一目标。隐藏检测(江等人。202520252025)在计算相似性之前直接使用原始激活,无需任何处理, 而 GradSafe(谢等人。202420242024)在没有理论理由的情况下启发式地选择安全关键参数,并在表 111 中显示出有限的有效性。
为了实现准确提取安全相关信息的目标,我们引入了 SCAV 的扩展多模态安全概念激活向量 (MSCAV)(徐等人。2024b2024b2024b). SCAV 表明,在对齐的 LLM 中,安全和有害输入的内部激活从第 10 层左右开始变得线性分离。 给定层中的内部激活,SCAV 通过忠实地解释模型的安全机制,准确输出模型认为该层的输入不安全的概率。概率对于检测攻击很有效,因为它们可以过滤掉与安全无关的信息(例如主题),同时保留与安全相关的信息。接下来,我们讨论如何将 SCAV 扩展到多模态设置,验证线性可解释性在 LVLM 中仍然成立,并证明 MSCAV 在区分安全输入和受攻击输入方面的有效性。
MSCAV 估计和细化。 为了使 LLM 的 SCAV 适应多模态设置,我们构建了两组多模态输入:我+,表示文本和图像内容都是安全的输入,以及我−,表示有害输入,其中文本包含自然有害内容(例如,“如何制造炸弹”),并且图像描绘了匹配的有害场景(例如,炸弹图像)。
在线性可分离性假设(在图222中得到验证)下, 安全和有害的激活𝐞l被认为在层中线性分离l如果线性分类器的测试精度超过阈值P0. 这假设激活可以线性映射以表示一个概念(我们论文中的“安全”概念),该概念可以深入了解模型的内部安全机制。 因此,我们估计模型将输入视为层中不安全的概率l通过线性分类器:

哪里𝐰∈𝐑d和b∈𝐑。总共L分类{C1,…,CL}进行训练,每个分类器都在线性可分离性下方的相应层中捕获安全概念。具体来说,我们训练每个分类器Cl使用二进制交叉熵损失:
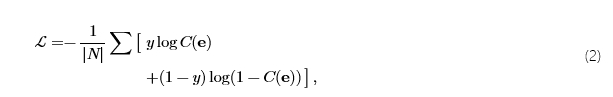
哪里y∈{0,1}表示安全 (0) 或不安全 (1),并且N是数据大小。激活和相应的标签是从我+和我−。所有分类器的连续输出提供了跨层输入安全性的细粒度视图,我们将其定义为 MSCAV:

哪里𝐒o∈𝐑L是一个仅包含安全相关信息的紧凑表示。
为了提高可靠性,我们改进了𝐒o通过仅保留分类器达到高于阈值的测试精度的层P0如图222所示,即ℒs={l∣𝒫l≥P0}。其余层在安全概念和改进的 MSCAV 方面被认为是线性可分离的𝐒r∈𝐑|ℒs|构造为:

验证 LVLM 中的线性可解释性。我们通过训练每一层中的分类器并测量它们在区分安全输入(我+) 来自有害的 (我−).
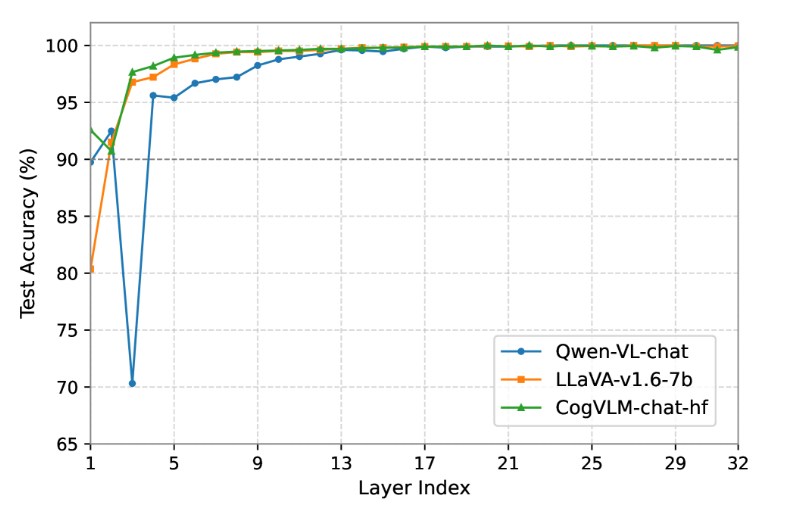
图2:测试线性分类器的精度,区分 LVLM 中中间层的安全和有害输入。
如图 222 所示,分类器在各层之间实现了始终如一的高精度,这表明安全和有害输入在激活空间中得到了很好的分离。值得注意的是,早在第 90 层的准确率就超过 4%,远早于∼第 10 层通常在 LLM 中观察到。这一结果验证了 LVLM 中的线性可解释性,并表明视觉信息能够更早地出现与安全相关的区别。
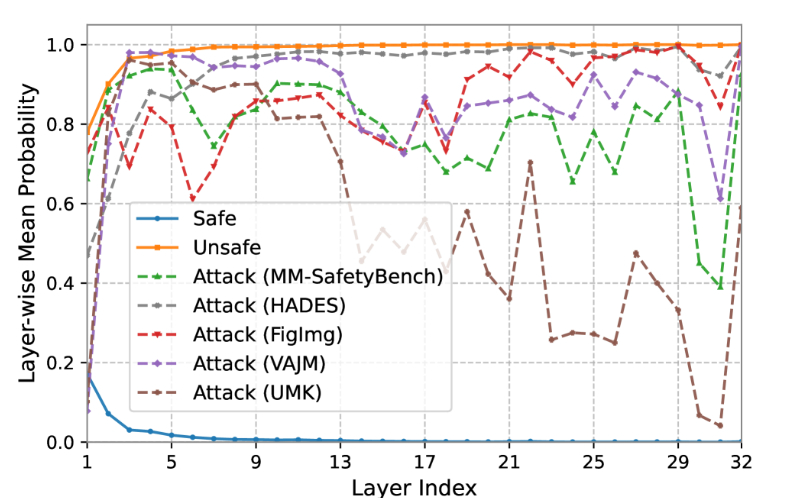
图 3:安全和有害查询的层平均概率值。还显示了五种看不见的越狱攻击方法的曲线,说明了安全和恶意输入之间的明显可分离性。
MSCAV 在区分攻击方面的有效性。我们分析了线性分类器在训练过程中从未遇到过的越狱攻击的 MSCAV 模式。 如图 333 所示,恶意攻击曲线通常低于有害输入的曲线,但仍远高于安全输入的曲线。 这表明攻击降低了跨层的安全概率,但与安全输入仍然有明显的区别(例如,它们的概率远非零)。 一个合理的解释是,攻击会优化以获得最终成功,而无需实质性地重塑所有层的内部表示。 使用层级安全判断,MSCAV 提供有效的安全表示,清楚地区分攻击和安全输入。
安全模式自动编码器
在本节中,我们将重点关注确定一种可靠的措施来区分安全输入和攻击的目标。 利用改进的 MSCAV,它为安全和恶意输入提供可分离的层级功能,一个简单的解决方案是训练监督分类器。然而,这需要标记的越狱攻击样本,这些样本很难获得,并且将泛化限制在看不见的威胁上。为了解决这一限制,我们采用了一种无监督的异常检测方法,将越狱攻击视为异常输入。
为了区分安全和异常输入,我们提出了安全模式自动编码器,它通过重建对细化的 MSCAV 模式的潜在分布进行建模。AE 专门接受安全输入训练,学会忠实地重建其安全相关特征。如图333所示,对抗性MSCAV模式与安全模式有很大偏差,导致自动编码器产生高重建误差(樱田和亚伊里201420142014)为统一检测提供直接信号。
至关重要的是,这种有效性依赖于 MSCAV 而不是原始激活。如果使用原始激活,异常输入可能在不相关的方面(例如主题或模式)与安全输入不同,从而导致检测不可靠。相比之下,MSCAV 仅保留与安全相关的表示,确保 AE 专门专注于重建安全特征。因此,与学习到的安全分布的偏差允许可靠的对抗检测。我们的消融研究(图 444)证实了这一点:用原始激活代替 MSCAV 会导致性能大幅下降,强调了安全引导表示对于有效检测的必要性。
为了实现安全模式自动编码器,我们采用了带有三层编码器和对称解码器的标准 AE。每个隐藏层都是一个全连接层,然后是 ReLU 激活。编码器逐步压缩细化的 MSCAV 表示𝐒r到低维潜在空间,将维度降低为二维瓶颈表示。然后解码器镜像这个过程,将潜在表示扩展回原始维度|ℒs|.形式上,自动编码器被定义为编码器和解码器功能的组合:

哪里fenc和f12 月表示编码器和解码器网络。 自动编码器专门针对安全输入进行训练,以最大限度地减少𝐒r及其重建𝐒^r:

哪里N是训练样本的数量。这种设计鼓励模型捕获安全相关特征的紧凑流形。
在推理过程中,异常检测是通过计算测试输入的重建误差来执行的:

哪里δ表示平方ℓ2重建错误,以及输入δ超过预定义的阈值τ被视为恶意攻击。
实验
|
型 |
方法 |
越狱攻击的结果 |
最小值 |
平均 | ||||
|
图图像 |
MM-安全台 |
哈迪斯 |
瓦吉姆 |
UMK的 | ||||
|
LLaVA的 |
镜像检查(一) |
0.2363 |
0.5561 |
0.5840 |
0.0989 |
0.4312 |
0.0989 |
0.3813 |
|
苹果酒(一) |
0.2483 |
0.6996 |
0.6809 |
0.8761 |
0.9013 |
0.2483 |
0.6812 | |
|
监狱警卫(一) |
0.7994 |
0.6155 |
0.5771 |
0.7552 |
0.8437 |
0.5771 |
0.7182 | |
|
GradSafe(二) |
0.5578 |
0.7869 |
0.9419 |
0.7066 |
0.0006 |
0.0006 |
0.5988 | |
|
隐藏检测(二) |
0.9157 |
0.9716 |
0.9942 |
0.9881 |
0.8308 |
0.8308 |
0.9401 | |
|
我们(二) |
1.0 |
0.9929 |
0.9999 |
0.9999 |
0.9919 |
0.9919 |
0.9969 | |
|
Δ |
+9.21% |
+2.19% |
+0.57% |
+1.94% |
+10.05% |
+19.39% |
+6.04% | |
|
Qwen-VL |
镜像检查(一) |
0.2136 |
0.4854 |
0.4501 |
0.2497 |
0.4681 |
0.2136 |
0.3734 |
|
苹果酒(一) |
0.3272 |
0.7046 |
0.6723 |
0.9106 |
0.9014 |
0.3272 |
0.7032 | |
|
监狱警卫(一) |
0.6313 |
0.6136 |
0.2791 |
0.4761 |
0.7887 |
0.2791 |
0.5578 | |
|
GradSafe(二) |
1.0 |
0.9515 |
0.9439 |
0.9301 |
0.0578 |
0.0578 |
0.7767 | |
|
隐藏检测(二) |
0.9922 |
0.7993 |
0.9956 |
0.9898 |
0.7035 |
0.7035 |
0.8961 | |
|
我们(二) |
1.0 |
0.9773 |
1.0 |
0.9999 |
0.9985 |
0.9773 |
0.9951 | |
|
Δ |
+0% |
+2.71% |
+0.44% |
+1.02% |
+10.77% |
+38.89% |
+11.04% | |
|
CogVLM |
镜像检查(一) |
0.2085 |
0.5403 |
0.5784 |
0.4146 |
0.2657 |
0.2085 |
0.4015 |
|
苹果酒(一) |
0.2 |
0.7398 |
0.6917 |
0.8945 |
0.8739 |
0.2 |
0.6800 | |
|
监狱警卫(一) |
0.6866 |
0.5918 |
0.5605 |
0.8622 |
0.8333 |
0.5605 |
0.7069 | |
|
GradSafe(二) |
0.5120 |
0.3024 |
0.4805 |
0.8503 |
0.7871 |
0.3024 |
0.5865 | |
|
隐藏检测(二) |
0.7487 |
0.8230 |
0.8884 |
0.8794 |
0.866 |
0.7487 |
0.8411 | |
|
我们(二) |
0.9967 |
0.9814 |
0.9992 |
0.9978 |
0.9963 |
0.9814 |
0.9943 | |
|
Δ |
+33.12% |
+19.25% |
+12.47% |
+11.55% |
+14.01% |
+31.08% |
+18.21% | |
表1:不同模型、方法和数据集的检测分数 (AUROC) 比较。 方法分为 (a) 无内部表示的检测和 (b) 通过内部表示的检测。最佳结果以粗体显示,次好结果以下划线.Δ表示我们的 LoD 方法相对于最佳基线的相对改进,计算为Δ=(LoD−最佳基线)/最佳基线.
实验设置
用于训练 LoD 的数据集。在这项工作中,我们使用来自 AdvBench 的文本提示(陈等人。202220222022)作为有害输入我−. AdvBench 包含大约 500 个描述有害行为的提示。 用于安全输入我+,我们从 GQA 中随机选择 500 个文本查询(哈德逊和曼宁201920192019),一个专为组合式问答而设计的大规模视觉推理数据集。 为了构建多模态输入,我们使用 Pixart-Sigma 合成安全和有害文本的图像(陈等人。202420242024). 对于训练,我们对 100 对有害和安全输入进行采样,以训练捕获内部安全机制的线性分类器,并使用剩余的对来评估测试准确性。此外,我们还使用 320 个安全输入来训练自动编码器进行异常检测,其余 80 个安全样本保留为验证集。
用于越狱攻击的数据集。为了评估我们的检测方法的性能,我们选择了具有代表性的攻击方法及其相应的数据集。对于基于即时纵的攻击,我们使用:(a) MM-SafetyBench(刘等人。2024c2024c2024c),通过文本提示搭配排版攻击和合成有害图像,涵盖 13 种有害场景;(b) 图步骤(龚等人。202320232023),包含通过排版攻击制作的图像及其相关文本,此处称为 FigImg;(c) 阴间(李等人。202520252025),它集成了图像构建和扰动以创建越狱样本。 对于基于扰动的对抗性攻击,我们采用:(a) VAJM(齐等人。202420242024),在使用 MM-SafetyBench 中的有害文本时对图像施加扰动;及 (b) UMK(王等人。202420242024),它同时扰乱图像和文本,还利用了 MM-SafetyBench 中的有害文本。 作为这些有害输入的对应物,我们采用 MM-Vet(Yu 等人。202320232023)作为安全输入的来源。MM-Vet 是一个基准测试,旨在评估基本的 LVLM 功能,包括识别、OCR 和语言生成。
基线。为了确保全面评估并突出我们所提出方法的优势,我们从两大类检测方法中选择了具有代表性的基线。对于不使用内部表示的方法,我们包括 CIDER(徐等人。2024a2024a2024a)、镜像检查(法雷斯等人。202420242024)和 JailGuard(张等人。202520252025). 对于利用内部表示的方法,我们合并了 HiddenDetect(江等人。202520252025)和 GradSafe(谢等人。202420242024).
度量。我们采用AUROC作为主要评估指标。AUROC 通过共同考虑正样本和负样本,全面衡量模型在所有决策阈值上的判别能力。这一特性确保了对依赖特定阈值选择可能产生的偏差的鲁棒性。我们选择AUROC也与之前的研究一致(江等人。202520252025;谢等人。202420242024;阿隆和坎福纳斯202320232023). 为了完整起见,我们还在附录中报告了其他指标的结果。
模型。我们在三种代表性的 LVLM 上评估了我们的方法:LLaVA-1.6-7B(刘等人。2024b2024b2024b), CogVLM-聊天-v1.1(王等人。202320232023)和 Qwen-VL-Chat(Bai 等人。202320232023).
主要结果
表 111 报告了三种不同 LVLM 和五种越狱攻击方法中各种检测方法的 AUROC 分数。我们提出的 LoD 始终优于所有基线。
具体来说,LoD 的平均 AUROC 分数0.9969,0.9951和0.9943分别在 LLaVA、Qwen-VL 和 CogVLM 上,通过相对改善6.04%,11.04%和18.21%.此外,LoD 显着提高了最坏情况的性能(即跨数据集的最小 AUROC),相对增益高达19.39%在 LLaVA 上,38.89%在 Qwen-VL 上,以及31.08%在 CogVLM 上,强调了其跨攻击的鲁棒性。 还值得注意的是,基于内部表示的现有方法(例如 HiddenDetect 和 GradSafe)通常在不同的攻击或模型中表现出不稳定的性能。相比之下,LoD 始终取得较高的检测分数,表明 MSCAV 和 AE 的集成可以准确、统一地检测越狱攻击。
消融研究
为了更好地了解LoD框架中每个核心组件的贡献并验证其整体有效性,我们进行了一系列消融研究。完整的LoD模型由两个主要组成部分组成:(1)多模态安全概念激活向量,根据安全概念解释内部激活;(2) 安全模式自动编码器,它对安全输入的分布进行建模,以无监督的方式检测异常。
我们评估以下消融变体:
- 没有 MSCAV 的 LoD:此变体绕过基于 MSCAV 的特征提取模块,并连接所有层的原始内部激活以形成特征𝐒生.此设置评估 MSCAV 在选择与安全相关的判别表示和减少特征冗余方面的有效性。
- 没有 AE 的 LoD:我们删除了 AE,而是采用简单的启发式方法:如果细化的 MSCAV 的任何维度𝐒r超过预定义的阈值(例如 0.1),则输入被标记为不安全。这种变体强调了通过 AE 学习紧凑分布表示的重要性,而不是依赖固定规则。
- 使用 HiddenDetect 的 LoD:我们用 HiddenDetect 中提出的特征提取方法替换了我们的特征提取模块(江等人。202520252025).这种变体可以直接比较我们基于 MSCAV 的特征提取和现有的最先进的方法。
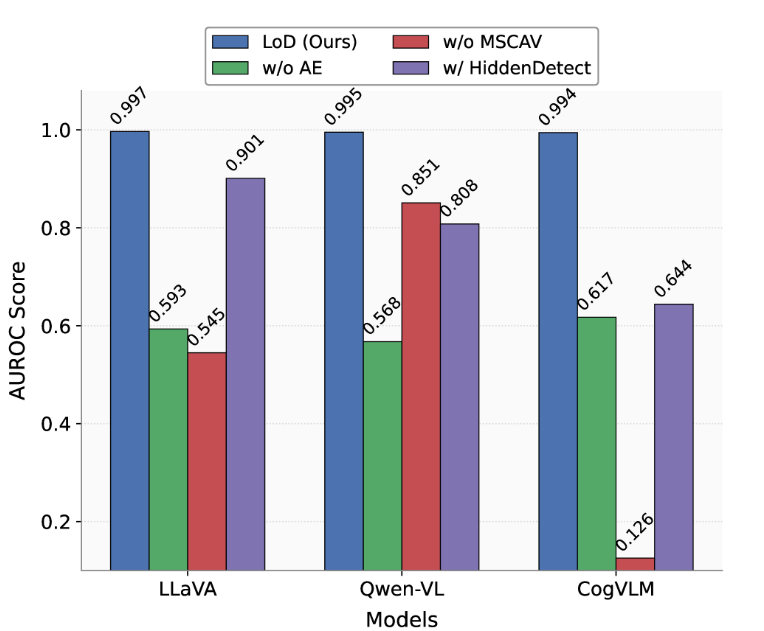
图4:该图显示了三个模型(LLaVA、Qwen-VL 和 CogVLM)在不同消融设置下五个基准测试的平均 AUROC 分数,突出了每个关键组件对 LoD 框架整体性能的贡献。
图 444 中的消融研究强调了 LoD 框架中两个关键组件的基本贡献,并提供了与 HiddenDetect 等启发式策略的直接比较。删除特征提取模块 (MSCAV) 会导致 LLaVA 和 CogVLM 的性能显着下降,AUROC 分别降至 0.545 和 0.126。相比之下,Qwen-VL 的性能仍然相对较高,为 0.851,这表明 MSCAV 在过滤不相关信息以进行安全检测方面发挥着至关重要的作用,尤其是在 LLaVA 和 CogVLM 模型中。同样,删除 AE 模块会导致所有模型的一致降级。这进一步强调了通过 AE 对安全特征的潜在分布进行建模的重要性,而不仅仅是简单的启发式阈值。我们还评估了 HiddenDetect 作为基线。尽管它在 Qwen-VL (0.808) 和 LLaVA (0.901) 上取得了中等性能,但在 CogVLM (0.644) 上的得分明显低于完整 LoD 模型。这揭示了 HiddenDetect 在捕获不同模型的安全相关表示方面的泛化性和有效性有限。
总体而言,这些结果证实了 LoD 设计的有效性:通过将基于 MSCAV 的表示与通过安全模式自动编码器的无监督异常检测集成在一起,LoD 实现了卓越的性能和跨模型越狱攻击的统一检测。
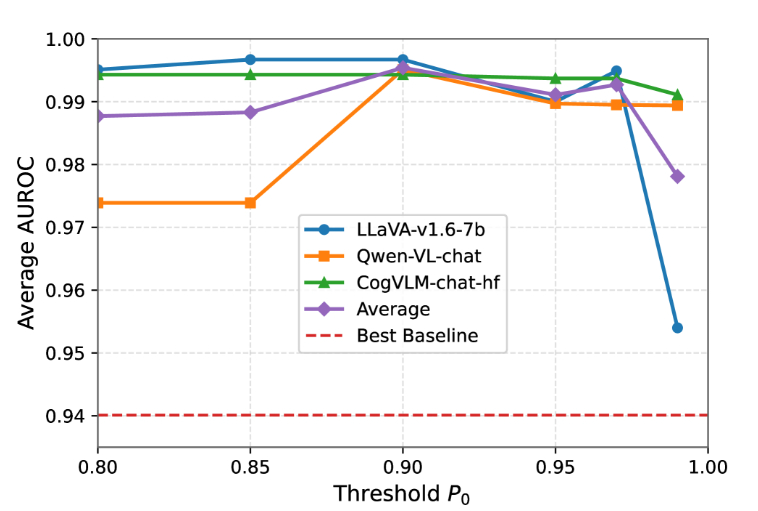
图5:三种模型在不同阈值下的五个基准测试的平均 AUROC 得分P0∈{0.8,0.85,0.9,0.95,0.97,0.99}.虚线表示现有基线实现的最佳 AUROC。
参数灵敏度分析
我们的方法涉及两个超参数:层选择阈值P0和决策阈值τ.由于 AUROC 独立于τ,我们评估了P0.
如图 555 所示,AUROC 在不同的P0值并超过最佳基线,只有微小的变化。 较大P0值保留较少但更可靠的安全层,这减少了噪声,但可能会丢弃有用的激活,这解释了P0=0.99.总体而言,稳定的性能表明我们的方法是稳健的,并且对P0,确保稳定的检测性能。
计算效率分析
如表 222 所示,我们的 LoD 方法在 FigImg 基准测试上实现了所有三个模型中每个输入的最短推理时间(0.13–0.18s),明显快于所有基线(例如,超过 4×比 HiddenDetect 更快,超过 200×比 JailGuard 更快)。此外,训练线性分类器和 AE 模块分别需要大约 12 秒和 2 秒,只需要一次性的轻量级设置。 所有实验都在单个 NVIDIA A800 GPU 上进行。这些结果表明,与现有方法相比,我们的方法具有很高的效率。
|
方法型 |
LLaVA的 |
Qwen-VL |
CogVLM |
|
镜像检查 |
1.16 |
1.14 |
1.64 |
|
苹果酒 |
0.47 |
1.4 |
0.90 |
|
监狱警卫 |
46.11 |
31.31 |
100.78 |
|
GradSafe |
0.56 |
0.55 |
0.81 |
|
隐藏检测 |
0.56 |
0.27 |
0.35 |
|
我们 |
0.13 |
0.13 |
0.18 |
表2:FigImg 上不同方法在三个模型中的平均每个输入检测时间。最佳(最短)时间以粗体显示。
局限性
尽管我们提出的方法在不同模型和越狱攻击中表现出强大且一致的性能,但它仍然存在一定的局限性,为未来的工作指明了方向。
首先,我们的方法取决于 LVLM 的内部激活。 这意味着重大的架构变化或在未来模型中采用替代安全对准机制可能需要调整我们的探测器。 然而,由于当前和可预见的 LVLM 从根本上仍然是基于深度神经网络架构, 我们相信,我们的方法在提取分层表示和检测此类模型中的越狱攻击方面将保持有效。
其次,尽管我们已经证明了对各种未知越狱攻击的稳健性,但我们目前的评估可能无法完全捕获更复杂或未来明确设计用于纵内部表示的攻击策略。调查此类自适应攻击是进一步加强我们检测框架弹性的重要方向。
相关工作
检测方法。检测方法可以根据它们是否依赖于内部表示进行大致分类。 没有内部表示的方法仅分析输入或输出,例如检查文本-图像一致性(徐等人。2024a2024a2024a;法雷斯等人。202420242024),测量文本困惑度(阿隆和坎福纳斯202320232023),监控输出鲁棒性(张等人。202520252025),或直接评估生成输出的安全性(Pi 等人。202420242024;团队202420242024;郭台铭等人。202420242024). 相比之下,利用内部表示的方法(谢等人。202420242024;江等人。202520252025)依赖启发式规则,例如,识别梯度或激活中的有害输入模式,并假设恶意输入与它们相似。尽管在某些情况下有效,但这种方法在性能和推广方面仍然有限。 与这些启发式设计不同,我们的方法引入了一个可学习的框架,该框架优化了从内部激活中提取安全相关信息,并以无监督的方式采用异常检测,实现了最先进的性能和越狱攻击的统一检测。
越狱攻击。LVLM 的多模式特性引入了新的攻击面,特别是从视觉方面,使它们更容易受到越狱尝试的影响(范等人。202420242024;金等人。202420242024;刘等人。2024年20242024年年,一个一个一个). 现有的越狱攻击大致可分为两种类型(刘等人。2024a2024a2024a):基于提示纵和基于对抗性扰动的攻击。 提示作修改文本或视觉输入以伪装不安全的意图或绕过安全过滤器,通常不依赖于渐度(龚等人。202320232023;马等人。202420242024;刘等人。2024c2024c2024c;李等人。202520252025). 相比之下,对抗性扰动通常对图像或文本应用基于梯度的修改,诱导模型生成不安全的输出(牛等人。202420242024;齐等人。202420242024;王等人。202420242024;沙耶加尼、董和阿布-加扎勒202320232023). 尽管现有的检测方法通常无法在不同的攻击中推广,但我们的可训练异常检测方法在未知越狱攻击中实现了强大的检测性能。
结论
在这项工作中,我们引入了学习检测(LoD),这是一个可训练的异常检测框架,用于识别 LVLM 中的越狱攻击。 LoD 利用 MSCAV 从内部激活中准确捕获安全相关信息,并将攻击检测重新表述为基于自动编码器的异常检测,无需针对特定于攻击的监督。 大量实验表明,LoD 实现了最先进的性能,并为未知越狱攻击提供准确和统一的检测。


















 4930
4930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









