



大家读完觉得有帮助记得关注和点赞!!!
抽象
随着网络攻击的复杂性日益增加,威胁情报的主动性和前瞻性对于威胁检测和来源分析变得更加重要。但是,将 Tactics, Techniques, and Procedures (TTP) 情报中描述的高级攻击模式转化为可作的安全策略仍然是一项重大挑战。这一挑战源于高级威胁情报和低级溯源日志之间的语义差距。为了解决这个问题,本文介绍了 CLIProv,这是一种检测主机系统中威胁行为的新方法。CLIProv 采用多模式框架,该框架利用对比学习将来源日志的语义与威胁情报保持一致,从而有效地将系统入侵活动与攻击模式相关联。此外,CLIProv 将威胁检测表述为语义搜索问题,通过搜索语义上与日志序列最相似的威胁情报来识别攻击行为。通过利用威胁情报中的攻击模式信息,CLIProv 可以识别 TTP 并生成完整简洁的攻击场景。对标准数据集的实验评估表明,CLIProv 可以有效地识别系统来源日志中的攻击行为,为潜在技术提供有价值的参考。与最先进的方法相比,CLIProv 实现了更高的精度并显著提高了检测效率。
关键字:
威胁情报、威胁检测、溯源分析、多模态、对比学习、攻击场景重构
1介绍
高级持续性威胁 (APT) 具有技术先进、持续时间长、针对性强等特点,已成为网络安全领域最重要的威胁之一[1].APT 攻击者通常通过利用零日漏洞获得初始访问权限[2]或采用社会工程技术[3].然后,它们建立持久性并执行横向移动,以长期隐藏在系统中,逐渐渗透到关键网络中。这些活动严重影响了能源和电信等关键行业,甚至威胁到国家安全和公共安全。
例如,VPNFilter 事件是 2018 年针对电信设备的臭名昭著的攻击,利用路由器安全漏洞实现初始访问.美国司法部已将该事件与 APT28 联系起来[5].这次攻击破坏了至少 54 个国家和地区的五十多万台设备。
传统的基于网络流量的入侵检测方法只能监控网络级模式,无法捕捉数据包背后的行为逻辑。此外,APT 攻击通常是分布式和多阶段的。基于流量的方法缺乏关联攻击行为的能力,因此难以识别感染源和跟踪攻击路径.加密和混淆技术的广泛使用进一步加剧了这些限制,使基于流量的方法不足以解密和解释数据包内容。根据最近的研究,来源日志可能是识别 APT 的更可靠的数据源。来源日志是描述系统执行历史记录的结构化审计日志.它们包括系统实体之间的交互关系,例如进程和文件之间的读写交互。来源日志中包含的丰富上下文关系提供了系统行为的全面视图,为威胁检测提供强大的支持。
基于溯源日志的威胁检测方法主要分为异常检测和威胁猎捕两大类。异常检测[7]通过监控与既定正常行为模式的偏差,使用机器学习或统计模型来检测系统内的异常情况,从而识别攻击。威胁搜寻[8,9]利用经验和情报建立合理的攻击假设,使用知识模板主动识别攻击迹象。随着威胁情报的发展,查询图[12]已成为主流知识模板。查询图从威胁情报中提取入侵指标 (IOC) 及其关系,以定向图的形式直观地表示不同系统实体之间的交互,这有助于识别和关联复杂的多步骤攻击。尽管当前的解决方案表现出出色的检测性能,但它们仍然存在一些固有的局限性。
限制 1.异常检测在很大程度上依赖于训练数据的质量和代表性,这通常会导致高误报率。为了最大限度地减少误报,理想情况下,训练数据应涵盖所有正常行为模式,这对计算资源构成挑战。
限制 2.威胁搜寻依赖于结构化查询模板。这些模板通常需要手动设计,这既费时又费力。此外,精确匹配方法缺乏灵活性,难以识别未知攻击。
限制 3.来源日志的规模限制了威胁查询的效率。APT 攻击具有隐蔽性,通常具有较长的时间段,导致日志规模大,这给溯源分析带来了挑战。大规模数据图中的查询作(例如路径搜索和模式匹配)需要遍历大量节点和边缘,从而导致响应时间变慢。
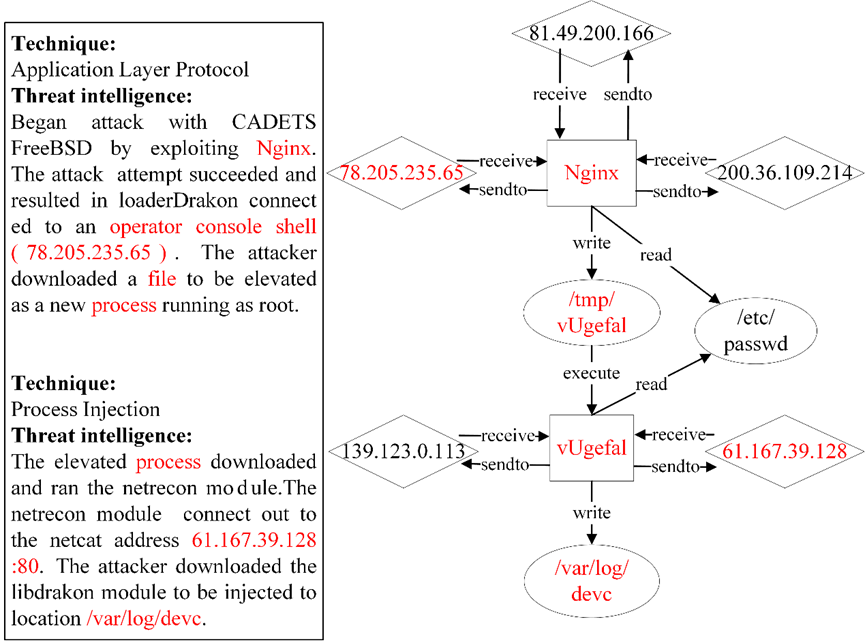
图 1:DRAPA TC 数据集中的攻击场景示例。
基于上述限制,本文考虑整合威胁情报以增强对攻击行为模式的理解。这是 APT 威胁搜寻的一个未充分开发的领域。无花果。1 显示了 DRAPA TC 中的攻击场景[13]数据集,包括 Threat Intelligence and Provenance 图。它以红色突出显示威胁情报和来源日志的相应部分。如图 1 所示。1、威胁情报以自然语言形式提供攻击过程的描述性信息。通过了解威胁情报与数据来源之间的相关性,威胁情报中的战术和技术信息可以帮助更深入地了解攻击行为语义。然而,语义级别和句法结构的差异对使高级智能与低级日志保持一致提出了挑战。
本文提出了 CLIProv,一种基于多模态学习的新型威胁狩猎方法。CLIProv 专注于从来源日志中学习攻击行为模式,而不是学习依赖于大量正常样本的正常行为模式。它整合了威胁情报,以增强模型对复杂攻击语义的理解,并改进其跨场景的泛化。CLIProv 直接利用自然语言威胁情报和原始来源日志来构建正负样本对,无需二次提取情报。通过对比学习[14],该模型可以自动捕获攻击模式和系统行为之间的深层语义关系。CLIProv 采用语义搜索机制进行威胁搜寻。它根据系统实体的上下文依赖关系和作行为的密度来划分来源日志,然后将高维原始数据映射到低维向量空间,从而降低计算复杂性和资源消耗。
综上所述,本文的贡献如下。
- 该文提出一种物源测井的表示学习方法。CLIProv 是第一个将多模态技术应用于威胁情报和来源日志联合学习的框架。CLIProv 使用对比学习在共享语义空间中对齐日志和情报的嵌入,为对应于相同攻击模式的不同数据生成高效且一致的表示。
- 该文提出一种基于语义搜索的威胁调查方法。CLIProv 不依赖精确的查询模板,通过在共享语义空间内搜索与威胁情报中描述的攻击模式相匹配的日志序列来准确识别攻击行为。
- 我们评估了 CLIProv 在四个公共数据集上的检测性能。结果表明,CLIProv 在场景、漏洞和数据集中有效执行,具有更高的精度和更低的计算成本。重建的攻击场景可以提供可解释的高级技术摘要。
2相关工作
最近,基于来源日志的威胁检测方法大致可分为异常检测和威胁搜寻。在威胁搜寻方法中,威胁情报逐渐成为攻击知识体系的重要组成部分。本节详细回顾了这些领域的相关工作,并总结了研究的进展。
2.1基于异常检测的威胁检测方法
异常检测方法假定攻击行为与正常行为明显不同。这些方法通过对正常行为模式进行建模来检测威胁。StreamSpot 公司[15]提出了一种图形级检测方法。它根据局部子结构的相对频率设计异构图相似性函数,并使用聚类方法识别威胁。独 角 兽[16]通过在图形演变过程中引入摘要编码来解决攻击行为的动态性质。然而,图级特征提取方法对小规模异常不够敏感,尤其是当 APT 攻击经常将其恶意活动隐藏在大量正常作中时。Log2vec[17]通过采用改进的随机游走算法来学习日志条目的嵌入,引入了日志条目级检测方法。此外,Threatrace[18]建议进行节点级检测。它自定义了图形样本和聚合 (GraphSAGE) 框架,以捕获良性节点的上下文特征,并通过良性节点的结构差异来识别异常。凯罗斯[10]通过检查动态边变化和邻域结构来评估结点异常。尽管有其优势,但随着正常行为模式数量的增加,基于异常的方法面临着挑战,需要持续更新以保持性能和有效性。
2.2基于威胁搜寻的威胁检测方法
威胁搜寻方法使用现有或预期的攻击行为知识来定义启发式规则,并将其与来源日志进行匹配以进行攻击检测。
APTHunter[19]通过定义关键元素(如源主题、目标对象、syscall 详细信息、中间进程和进程树路径长度)来构建攻击查询。为了满足大型系统中对实时威胁搜索和高效数据存储的需求,ThreatRaptor[20,21]引入了威胁行为查询语言 (TBQL),其关键基元有助于高效查询复杂的多步骤系统行为。MEGR-APT[22]通过提出基于 RDF 的来源图表示来优化内存使用。它将候选子图提取到磁盘并在内存中执行威胁查询,从而显著减少内存消耗。同样,Yu 等人。[4]专注于 IoT 环境,并提出了一种经济高效的方法,用于在空间维度上生成低频来源图的快照,以解决资源限制。通过应用预定义的推理规则,他们识别了与症状节点直接或间接因果相关的文件和套接字,从而构建了全面的攻击场景。这些方法利用精确的查询规则和高效的图形表示来提高威胁搜寻的速度和准确性。
了解攻击者的策略和动机对于检测 APT 攻击至关重要。策略、技术和程序 (TTP)[23]提供了一个广泛使用的框架,用于对 APT 策略和技术进行分类。攻击行为的高级摘要可帮助分析师识别攻击链中的关键阶段并采取主动措施。福尔摩斯[24]通过定义相关事件集群将日志事件映射到可疑的 TTP,并采用修剪和降噪来生成简化的高级场景图。在此基础上,Rapsheet[25]将 TTP 规则从 16 条扩展到 67 条,并引入了基于杀伤链中因果关系的基于图的威胁评分方案。但是,这些方法严重依赖手动定义的规则,从而限制了它们的适应性。此外,当攻击行为略微偏离时,精确匹配往往会失败。随着攻击技术的动态发展,这些方法面临着不断更新规则库的挑战。
2.3基于威胁情报的威胁搜寻方法
随着威胁情报的发展,研究人员倾向于在情报中使用攻击知识,以减少对传统查询规则的依赖,从而提高检测准确性并增强对不断发展的攻击技术的适应性。波洛[12]首先引入了查询图的概念,它利用了威胁情报中的因果关系。它将 IOC 表示为节点,将其相互关系表示为边缘,从而形成攻击者行为的通用模型。Poirot 将威胁狩猎定义为图模式匹配 (GPM) 问题,并提出了一个近似函数来评估查询图和源图之间的一致性,有效地解决了图匹配的 NP 完备性问题。但是,当攻击场景碎片化时,Poirot 等基于结构的匹配方法可能会失败。为了克服这一限制,Deephunter[26]和 ProvG-Searcher[9]使用图神经网络 (GNN) 来学习来源图的向量表示,从而显著提高查询效率。虽然查询图提高了威胁搜寻的稳健性,但安全专家手动提取它们仍然是劳动密集型和耗时的,这凸显了对自动化解决方案的需求。
提取[27]应用自然语言处理 (NLP) 技术从威胁情报中提取威胁实体和关系,并设计语义角色标记方法以自动生成查询图。AttacKG[28]将查询图映射到 TTP,使用更高级别的语义特征丰富它们。随着网络安全知识图谱的发展,最近的研究[29,30,31]应用图形遍历算法和链接预测技术来生成攻击假设。
3背景和动机
在本节中,我们介绍了实施 CLIProv 的必要背景知识,并提供了一个激励性示例,以突出它与其他基于威胁情报的威胁搜寻方法的区别和优势。
3.1数据来源和威胁情报
来源日志通常由系统审计工具(如 Windows ETW 和 Linux Audit)生成,这些工具详细记录系统调用、文件访问和用户登录等活动。数据来源根据这些日志中的信息流建模为有向图,如图 2 所示。2. 节点表示系统级对象,边表示它们的交互。
威胁情报是基于证据的知识,包括有关资产现有或新出现的威胁或危害的上下文、机制、指标、影响和可作的建议,可用于为主体对该威胁或危害的响应决策提供信息[32].它可以为来源分析提供有价值的假设。
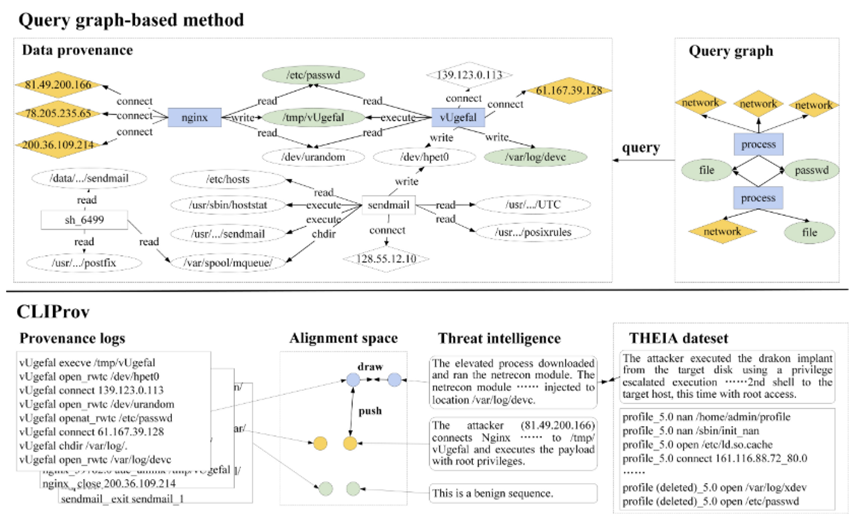
图 2:基于查询图的方法与 CLIProv 的比较。
但是,数据来源是记录系统实体之间作的低级、微观和结构化信息。相比之下,威胁情报是用自然语言表述的[33],提供关于威胁的高级宏观视角,包括对威胁意图和策略的全面分析。由于它们在结构和表达上的差异,它们之间存在语义上的差距。根据 2024 年 SANS 威胁情报调查[34],74% 的威胁情报以报告的形式发布,但大多数应用情报由 IOC 组成。虽然自然语言形式的威胁情报包含了大量的攻击知识,但目前还没有找到与威胁狩猎的良好集成方法。
3.2多模态学习
在表征学习领域,“模态”是指应用于信息的特定编码类型[35].多模态数据从不同的角度描述对象,提供互补信息。不同模态的特征向量存在于不同的语义空间中。多模态学习旨在将来自不同模态的特征投影到一个共享的子空间中,允许具有相似语义的数据具有相似的特征表示。
为了解决语义差距问题,CLIProv 采用了多模态表示对齐方法。这种方法学习每种模态的单独表示,同时引入约束以确保它们之间的协调。给定两个数据集X和Y不同模态的 multi modal representation alignment 公式如下。

哪里f和g是将原始空间映射到共享多模式对齐空间的投影函数。∼表示协调方法,包括最小化余弦距离[36]、最大化相关性[37]等等。以 L2 范数为例,不同模态数据之间距离的最小化可以表示为:

在多模态任务中,无监督学习可以通过数据的统计特征和分布自动发现数据中的底层结构和模式。它可以通过识别数据中的相似性和差异性,从数据中提取更有效的特征表示。对比学习提供了正样本和负样本的灵活定义,并展示了卓越的性能,使其成为无监督学习的杰出研究方向。该方法在最小化负样本对相似性的同时,使正样本对的相似性最大化,使得到的特征表示具有更强的判别和泛化能力。
3.3动机示例
我们提供了一个示例来说明基于查询图和我们方法背后的直觉的最先进的威胁搜寻方法的局限性。该示例来自 DARPA TC Engagement #3 学员。如图 1 所示。2、溯源图记录了攻击者通过 Nginx 后门将 Dragon APT 注入服务器内存的过程。在图中,菱形表示 IP 地址,矩形表示进程,省略号表示文件。攻击者发送格式错误的 HTTP 请求,将易受攻击的 Nginx 服务器连接到位于 78.205.235.65 的 shellcode 服务器。攻击者利用该 shell,将恶意负载下载到 /tmp/vUgefal,并使用 passwd 提升权限。然后,提升的进程连接到 61.167.39.128,将另一个恶意负载下载到 /var/log/devc。来源图的下半部分记录了邮件发送的正常系统行为。
3.3.1现有威胁搜寻工作的限制
随着网络攻击的复杂性和多样性,现有的基于查询图的威胁猎捕方法面临越来越多的局限性,给威胁检测带来了挑战。
- 费力的查询图生成。查询图是通过对原始威胁情报的二次处理生成的。将自然语言文本转换为图形需要具有丰富网络安全知识的注释者。查询图的数量和质量对于确保准确检测威胁至关重要,这使得创建高质量的大规模查询图库成为一项重大挑战。虽然一些研究人员[27,28]已经尝试使用 NLP 技术自动化此转换过程,但一个好的 NLP 模型仍然需要大量带注释的数据。这并没有从根本上解决查询图生成的劳动密集型问题,手动注释和上下文理解仍然是必不可少的。
- 昂贵的查询过程。APT 攻击通常隐藏在大量良性行为中。例如,CADETS 数据集包含超过 1000 万条日志,但只有大约 100 条与攻击相关,仅占整个日志序列的 0.001%。基于查询图的方法需要评估整个来源图中的潜在比对。在图 .2,则 Provenance 和 Query 图表中颜色相同的节点表示相应的匹配项。为了降低搜索复杂性,Poirot[12]估计 APT 入口点以筛选候选查询节点。但是,由于图结构的复杂性,这种基于路径的方法仍然需要多次遍历。深度猎人[26]识别 IOC 周围的子图,并使用图表示学习来计算语义相似性。虽然基于语义的方法提高了子图匹配效率,但它仍然需要对查询和采样子图进行详尽的成对比较才能完全确定。ProvG 搜索器[9]提出了一种用于子图分区的动态规划算法,从而降低了查询计算的复杂性。然而,来源图的大规模和高连通性继续对图表示学习构成重大挑战。
- 可解释性差。威胁情报包含安全专家对攻击技术和策略的广泛分析,可帮助分析师有效地识别和了解网络威胁。例如,图 2 中所示的两个威胁情报实例。2 描述了攻击者提升权限和下载恶意负载的过程。这些描述不仅概述了攻击过程,还强调了使用“提升”和“根访问权限”等关键字的攻击技术和策略。相比之下,Query Graph 仅提供用于威胁检测的模板,缺乏与攻击技术相关的语义信息。因此,仍然需要对已识别的威胁行为进行手动分析。这些方法无法充分利用威胁情报进行全面的威胁解释。
3.3.2我们方法的直觉
我们方法背后的核心思想是利用对比学习将描述相同攻击模式的日志序列和威胁情报对齐到一个共享的对齐空间中。通过拟合匹配的样本对,远离不匹配的样本对,模型可以自动学习 intelligence 和 log 之间的语义关联,避免了手动设计查询图的高成本。对比学习可以自动发现数据的潜在结构,并将学习到的攻击模式推广到其他语义相似的行为。如图 1 所示。2、THEIA 和 CADETS 数据集的日志行为不同,但都代表着提权、恶意服务器连接和有效负载下载。CLIProv 可以利用情报的语义相似性,在相似的语义空间中收集具有相同攻击模式的日志序列,帮助模型理解特定攻击模式对应的关键行为逻辑。在威胁查询阶段,即使攻击过程描述缺乏完美匹配,模型也可以利用情报中的攻击模式信息来识别潜在的攻击行为。此外,CLIProv 引入了一种基于行为依赖和时间密度的子图分区方法,通过语义搜索机制将高维原始数据映射到低维语义空间,降低了威胁查询的复杂度。CLIProv 以威胁情报为媒介,将底层攻击行为抽象为更具可解释性的攻击技术,提高威胁识别效率,为安全分析师提供更直观、更全面的防御视角。
4威胁模型
我们假设来自主机系统的来源数据是完整的,并且没有被攻击者恶意更改或伪造。我们也不考虑硬件级、侧信道或隐蔽通道攻击,因为内核级审计系统通常不会捕获这些行为。CLIProv 是一种基于知识的威胁搜寻方法,我们假设攻击者的行为将在来源数据中保留某些攻击模式。类似的攻击技术反映在类似的攻击序列中。例如,在图 .2,CADETS 数据集显示攻击者通过 Nginx 植入后门,而 THEIA 数据集显示通过 Firefox 植入类似过程。两者都遵循 shell 连接的核心模式→payload 下载→权限提升→进程执行。战术和技术的频繁变化给对手带来了重大挑战。因此,我们进一步假设攻击行为的基本特征将基本保持不变。但是,CLIProv 受到所学威胁情报范围的限制,使其无法检测明显偏离已知模式的攻击。此限制在基于知识的检测系统中很常见[9,12,26],我们将在第 7 节中进一步讨论。尽管如此,如 Section 6.2 所示,CLIProv 对具有细微变化的攻击模式表现出良好的泛化。
5系统设计和方法
5.1概述
CLIProv 是一种基于知识的威胁搜寻系统,它采用多模态学习来实现来源日志和威胁情报之间的语义对齐。通过利用富含攻击模式的威胁情报,CLIProv 能够从日志中搜索潜在的攻击技术。无花果。图 3 说明了 CLIProv 的架构,它由三个主要组件组成。
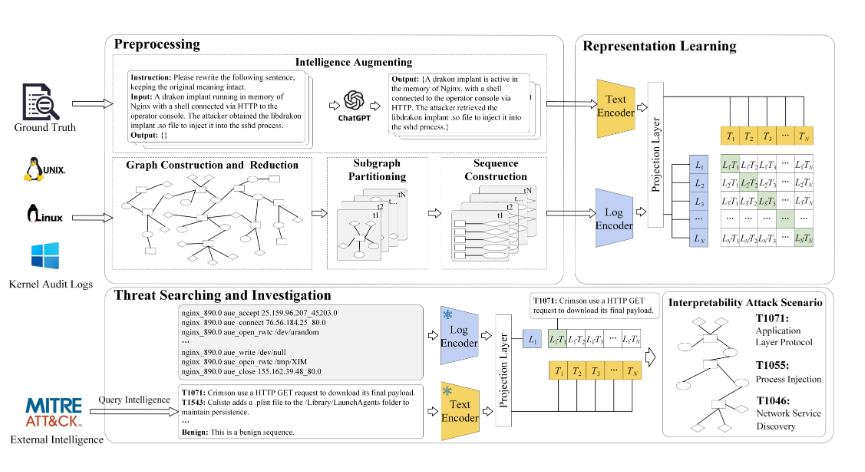
图 3:CLIProv 架构概述。
- 预处理。CLIProv 会自动处理来源日志和威胁情报,以生成用于表示学习的正负样本对。
- 表征学习。CLIProv 采用预训练模型稳健优化的 BERT 方法 (RoBERTa)[38]为威胁情报文本和日志序列构建编码器,并为每个序列生成向量表示。通过投影层,来自不同模态的数据被投影到一个统一的语义空间中。使用对比学习,文本编码器和对数编码器被联合训练以生成相似的向量表示,从而在语义空间中对齐匹配的文本-对数对。
- 威胁搜索和调查。CLIProv 通过查询来源日志中的日志序列来检测威胁,这些日志序列在语义上类似于威胁情报。MITRE ATT&CK[39]是一个公开可用的威胁情报存储库,用于记录对抗策略、技术和常识。使用经过训练的编码器,系统在 ATT&CK 数据库中搜索语义上与日志序列匹配的情报,从而识别出处日志中的攻击技术。在整个来源图中执行语义搜索后,CLIProv 设计了一种时间因果推理方法来重建攻击场景,从而提供全面而简洁的威胁态势视图。
5.2预处理
CLIProv 处理来自各种来源(包括 Unix、Linux 和 Windows)的来源日志,以生成日志来源图。这些图根据时间和空间特征进行简化和分区,以获得出处子图并构建对数序列。CLIProv 使用来自地面实况的攻击进程记录,生成成对的威胁情报和日志序列。
5.2.1图构造和缩减
来源图是表示系统内事件的因果关系和数据流的有向图。出处图可以形式化为元组Gprov=(V,E)哪里
V是表示系统中对象的顶点集。CLIProv 专注于三种类型的内核对象,包括进程、文件和网络套接字。
E是一组有向边,表示对象之间的作和因果关系,其中源节点表示启动事件的主题,目标节点表示对象。边缘类型表示事件类型,例如 open、read、execute 和 connect。时间戳用作边缘属性,以促进图形缩减和分区。
Provenance 日志记录对系统对象的详细作,通常会生成大量重复和冗余条目,从而阻碍有效的威胁监控。为了解决这个问题,CLIProv 通过关注三个关键方面来减少有向断开连接的图。
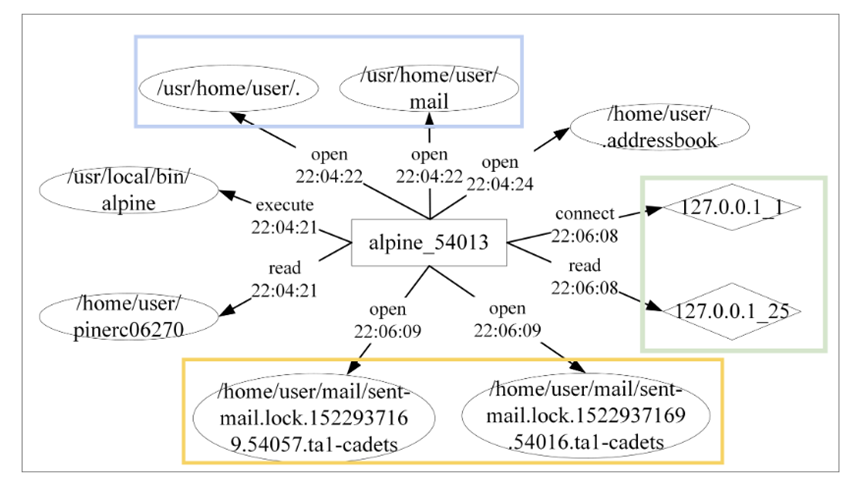
图 4:Alpine 电子邮件客户端作的流程图。
- 网络连接和通信。在主机系统内,许多进程与其他服务进行通信,例如连接建立和数据传输,这些作通常会被记录下来。在网络不稳定的情况下,系统可能会反复尝试重新连接,从而导致 Provenance 日志中出现大量相似的条目。此外,在单个通信会话期间,一个进程可能会在短时间内访问多个端口。如图 1 中绿色框内的示例所示。4、Alpine 邮件客户端首先通过端口 1 连接到 127.0.0.1 进行初始网络检查,随后通过端口 25 连接到本地邮件服务器发送电子邮件。这两个动作发生在一秒内,并且彼此前后都发生,所以我们认为这两个动作可以合并成同一个动作。这两个作都在 1 秒内发生。CLIProv 通过分析在固定时间窗口内从同一进程到同一 IP 地址的通信来合并实体和作行为。如果可以访问多个不同的端口,则多个端口都使用 _ 连接。如果边的类型不同,则不同的事件类型用 _ 连接形成新的边。合并的时间戳定义为集合中最早的时间戳。在图 .4,将绿色框中的两条边合并为一条边,事件类型为 “connect_read”,时间戳为 “22:06:08”。
- 文件目录级联作。在主机系统中,文件需要逐步访问,因此对文件目录的级联作经常出现在 Provenance Log 中,导致大量冗余。图 1 中的蓝色框4 记录 Alpine 进程访问已发送文件夹的顺序。在本例中,/usr/home/user 是 /usr/home/user/mail 的父目录。访问父目录不会为跟踪系统作流提供额外价值。CLIProv 从来源图中消除了与级联目录作相关的事件,仅保留与最终目录级别对应的事件。
- 类似的文件对象。主机系统中通常存在具有相似功能但名称略有不同的文件实体。它们通常看起来具有相同的父目录,但文件命名略有不同。这些文件通常是系统自动生成的临时文件、日志文件或高速缓存文件。这些文件是在执行某些任务以记录状态、存储中间数据或支持流程作时创建的。它们的名称往往遵循某些模式,例如添加时间戳、进程 ID 或随机字符串,以标识文件的来源或生成时间。例如,被锁定的邮件在用户 mail 文件夹中的黄色框中图 1 中。4. 为了减少这种冗余,CLIProv 计算了在固定时间范围内连接到同一源节点并共享同一父目录的文件节点的字符串相似性。字符串相似度是使用 Levenshtein 距离测量的[40].相似度得分超过 0.7 的节点将合并为单个实体。
这种方法允许 Provenance Graph 全面捕获系统行为,同时保持简洁的结构。
5.2.2子图分区
威胁情报一般描述单一的攻击技术,而溯源日志通常包含系统长时间的完整运行行为。为了有效地匹配威胁情报文本,需要将来源图划分为更精细的子图。一种简单的方法是根据时间窗口进行分区[16].但是,这种方法可能会破坏事件之间的因果关系,从而导致碎片化的攻击场景。确定适当的时间跨度也具有挑战性,因为太短的跨度可能会错过关键步骤,而太长的跨度可能会引入不相关的噪声并降低威胁识别的准确性。
根据作系统中时间局部性原则和行为一致性的假设,系统行为中涉及的事件在逻辑上是高度相关的,并表现出时间密度。进程 A 创建进程 B 后,B 对文件 C 的访问通常会在短时间内发生。相比之下,不同行为之间存在逻辑间隙和时间间隔,长时间的暂停通常表示任务切换或条件等待。在实际攻击中,APT 攻击者通常会采用多步骤和低频率的策略来增强其行动的隐身性和持久性。他们故意延长攻击步骤之间的时间间隔,以逃避安全检测。因此,CLIProv 将系统行为子图定义为训练的最小单位。系统行为子图表示特定进程在连续时间段内对不同对象执行的一系列作。
对于过程p及其交互对象集、其系统行为子图G(p)定义为满足以下条件的事件序列:

哪里V(p)表示节点集,包括p及其访问的对象集O={o1,o2,…,on}.E(p)表示交互事件集。(p)表示时间戳的集合,满足时间的连续性和密度。对于任意两个连续事件e我,e我+1∈E(p),则以下公式成立:

θ麦克斯是用于定义行为边界的时间阈值,可以根据具体场景动态调整。
首先,为了保持系统行为的完整性,深度优先搜索 (DFS)[41]用于对图形进行分区。从可验证性图中未访问的节点开始,沿边的方向递归访问所有后续节点,直到访问所有可访问的节点。访问的节点及其连接边形成一个依赖子图。然后,基于事件的时间密度特征,分析事件之间的时间间隔,并将依赖关系子图进一步划分为不同的系统行为子图。通过遍历 Provenance Graph 中的所有节点,生成最终的系统行为子图集。
5.2.3序列构建
我们将系统行为子图转换为日志序列,表示为L={l1,l2,…,lN}.日志序列l我=[(vsrc(1,我),e(1,我), vdest(1,我)),(vsrc(2,我),e(2,我),vdest(2,我)),…, (vsrc(ℕ我,我),e(ℕ我,我),vdest(ℕ我,我))]哪里ℕ我是我-th 序列,vsrc(1,我)是第一个行为的源节点名称,e(1,我)是边类型,而vdest(1,我)是目标节点名称。
5.2.4智能增强
我们根据生成的攻击日志序列,手动将威胁情报划分为地面实况。以图 1 中的攻击场景为例。以 1 为例,上述子图分区算法将攻击场景划分为两个子图,对应的威胁情报也分为两部分。与 nginx 进程的日志序列对应的威胁情报为“通过利用 Nginx 开始使用 CADETS FreeBSD 进行攻击。攻击尝试成功,并导致 loaderDrakon 连接到作员控制台外壳 (78.205.235.65)。攻击者下载了一个文件,要提升为以 root 身份运行的新进程。
鉴于攻击序列样本的数量有限,CLIProv 通过增强威胁情报来扩展样本对的数量。近年来,大型语言模型由于其强大的小样本学习能力,在文本数据增强方面显示出广泛的应用潜力[42,43].CLIProv 利用提示模板和 GPT-3[44]以增强威胁情报。提示模板定义为 “Please rewrite the following sentence, keep the original meaning intact”。我们将初始的、未更改的威胁情报输入到 GPT 模型中,该模型会生成增强的威胁情报数据。该方法扩展了威胁情报以获取更多的样本对,帮助模型学习更全面和可泛化的特征。
对于良性对数序列,我们使用 “This is a benign sequence.” 作为其相应的文本描述。威胁情报样本集表示为T={t1,t2,…,tM}哪里tj是j-th 情报文本。
5.3对数序列表示学习
CLIProv 采用双编码器架构对来源日志和威胁情报样本分别进行编码。投影层旨在将来自不同模态的特征映射到共享特征空间,其中对比学习用于跨模态对齐和拟合特征。
5.3.1编码器
如图 1 所示。3、CLIProv 由文本编码器和对数编码器组成。我们将日志序列视为由系统实体和事件组成的句子,使用预先训练的 RoBERTa 模型作为日志编码器。同样,文本编码器也使用 RoBERTa。我们将 L 和 T 的样本配对,形成用于多模态训练的样本集。相应的 intelligence-log 对被视为正样本,而其他则被视为负样本。对于每个日志序列l∈L,我们使用 log 编码器对其进行编码fθ(l)parameterized by 参数化θ,并获取 “[CLS]” 特征作为对数序列的向量表示v=fθ(l)∈ℝd.对于每个情报文本t∈T,我们使用文本编码器对其进行编码fφ(t)parameterized by 参数化φ,并获取 “[CLS]” 特征作为智能文本的向量表示u=fφ(t)∈ℝd.
5.3.2投影网络
为了实现对数序列和威胁情报在共享语义空间中的对齐,我们将一个两层神经网络定义为投影网络。为了缓解梯度消失问题并提高网络收敛速度,我们利用残差连接将两种模态的数据投影到同一个向量空间中。给定一个输入向量x∈ℝd,则第一层网络的输出为h1=σ(W1x+b1)哪里σ是激活函数(例如 ReLU),W1∈ℝdout×d是第一层的权重矩阵,b1∈ℝdout是偏差向量。残差连接的输出为g(x)=h1+σ(W2h1+b2).在投影层之后,我们获得对数序列和威胁情报的向量表示,分别为g(fθ(l))和g(fφ(t)).
5.3.3训练
为我-第 个 logl我和j-TH 智能tj,我们使用v我=g(fθ(l我))‖g(fθ(l我))‖和uj=g(fφ(tj))‖g(fφ(tj))‖,它们的相似度计算为v我Tuj.考虑使用双向监督对比物镜来训练模型,该物镜使用 InfoNCE[45]作为损失函数来增强模型鲁棒性。在这里,log-to-text loss 函数定义为:

文本到日志损失函数定义为:

哪里τ是可学习的温度超参数[46]缩放 Logits,初始化为 0.07。最终的损失是两者的平均值:

CLIProv 从原始预训练模型进一步进行了预训练,使我们能够利用对数编码器和文本编码器来获得对数序列和威胁情报的矢量表示。
5.4威胁搜索和调查
威胁搜索和调查的目标是在一个完整的来源场景中发现和重建整个攻击过程。首先,对来源图进行预处理并划分为系统行为子图,然后使用这些子图获取日志序列。接下来,对数编码器生成这些序列的向量表示。通过从查询数据库中搜索语义最相似的情报文本,CLIProv 识别所有可疑的日志序列,从而重建整个攻击场景。
CLIProv 构造查询数据库Q={Q1,Q2,…, QK},使用 MITRE ATT&CK 威胁情报存储库。对于k-th 查询Qk=(qk,yk),qk是文本描述,yk是智能标签。如果qk是一种威胁情报,yk是其关联的 TTP。例如Qk=(“Crimson 可以使用 HTTP GET 请求下载其最终有效负载。”, “T1071”)。如果qk是 “This is a benign sequence.”,yk是 “良性” 的。查询文本被馈送到预先训练的文本编码器中,以获得查询向量fφ(qk).日志序列l使用fθ(l).在对齐空间中,CLIProv 选择语义距离最小的查询向量l并获取其关联的智能标签。

CLIProv 将所有标有 TTP 的日志序列识别为攻击。通过搜索整个溯源图,可以得到所有的攻击序列,可以表示为一组攻击序列L一个tt一个ck={l1,l2,…,ln}.每个日志序列l我表示系统行为子图G(我).为了连接这些孤立的子图,CLIProv 考虑了攻击行为之间的来源关系,并提出了一种高效的时间因果推理方法。它引入了一个虚拟节点v我′对于每个子图,并将v我′与所有其他节点一起使用v∈V(我)在子图中。生成的虚拟子图表示如下。

哪里t我表示子图的时间戳,取子图中边最早出现的时间来表示虚拟节点的时间。
CLIProv 使用虚拟节点表示行为子图,并根据虚拟节点之间的因果关系重构攻击路径。具体来说,CLIProv 对v我′由t我.对于每个v我′,推理它和上一个时间步的虚拟节点的因果关系。如果相邻虚拟节点之间没有直接关联,则 CLIProv 会向前遍历,直到找到与v我′.因果关系是虚拟节点之间的最短攻击路径,由瞬态 Dijkstra 算法计算[47].它确保它们按照攻击发生的顺序进行连接。识别出的攻击路径如下。
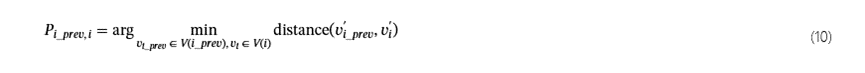
哪里v我_prev′表示具有前置任务关系的最近虚拟节点v我′,t我_prev<t我.
通过不断迭代,CLIProv 将所有孤立的子图连接起来,形成完整的攻击图G一个tt一个ck.重建过程如下。
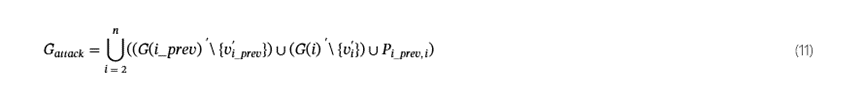
哪里\表示从图表中删除虚拟节点。
通过时间因果推理,CLIProv 可以将孤立的行为序列重建为完整的攻击场景。子图中的 TTP 标签提供高级战术和技术知识,帮助安全分析师快速识别攻击模式和目标,从而实现更有效的防御。
6评估
我们开发了 CLIProv 的原型,并使用四个公共数据集对其进行了评估。本节首先介绍我们的实验设置,包括开发框架、运行时环境和数据集。然后,我们评估了 CLIProv 的有效性和泛化性,并将其与其他四种威胁调查方法进行比较。最后,我们评估了各种参数的影响、运行时开销以及生成的可解释攻击场景的可靠性。
6.1实验设置
我们在 Python 3.8 中实现了一个 CLIProv 原型。我们使用 NetworkX[47]实现 Provenance Graph Processing 和 PyTorch[48]实现编码器模型。所有实验均在配备 GeForce RTX A6000 GPU、80 个 3.10GHz CPU 和 1TB 主内存的 Ubuntu 20.04 机器上进行。
6.1.1数据
我们在 CADETS、THEIA、ATLAS 和 CICAPT-IIoT 数据集上评估我们的方法,并使用 ATT&CK 数据库作为查询智能存储库。我们减小了日志数据集的来源图的大小,并选择了特定的攻击场景来训练 CLIProv,同时使用其他攻击场景来测试模型的有效性。表 1 总结了数据集的统计数据。
表 1:日志数据集的统计信息
| 数据 | 原始节点 | 原始边 | 大小 | 预处理节点 | 预处理边 | 训练图 | 测试图 | 威胁情报 | 查询智能 |
| 学员 | 454.1K | 1.1 米 | 11.1吉字节(GB) | 236.7K | 673.4K | 2 | 2 | 3 | 10358 |
| 忒伊亚 | 426.8K | 1.6 米 | 43.2千兆字节(GB) | 354.9K | 743.4K | 2 | 1 | 3 | |
| 地图集 | 200.9千米 | 2.5 米 | 4.1千兆字节(GB) | 76.5 千米 | 1.4 米 | 10 | 6 | 6 | |
| CICAPT-IIoT 型 | 53,3K | 143.5K | 28.5兆字节(MB) | 27.9K | 92.4K | 0 | 1 | 0 |
学员[13]来自 DARPA TC 计划的第 3 次参与,包括为期两周的系统日志,记录红队与蓝队的情景。模拟攻击活动包括通过 Nginx 后门渗透 FreeBSD 主机并部署恶意负载。攻击者进行了四次攻击,每次持续时间不超过一小时。DARPA 为这些攻击提供了基本事实,使我们能够标记与攻击相关的子图并获取威胁情报。我们还从 KAIROS 收集了攻击场景描述[10].为了评估 CLIProv 在攻击场景中的泛化能力,我们从 CADETS 中选择了两个场景作为训练集,选择了两个场景作为测试集。
忒伊亚[13]也来自 DARPA TC 计划的第 3 次参与,记录了对 Ubuntu 主机的三次攻击。这些攻击使用了三种不同的方法:Firefox 后门、浏览器扩展和网络钓鱼。攻击标记和威胁情报收集过程与 CADETS 数据集中使用的过程一致。我们从 THEIA 中选择了两个场景作为训练集,一个作为测试集。
地图集[49]来自 ATLAS,包含对 Windows 主机的公开模拟攻击。这些攻击是根据 APT 报告复制的,包括 16 个事件,利用了 6 个漏洞:CVE-2015-5122、CVE-2015-3105、CVE-2015-5119、CVE-2017-11882、CVE-2017-0199 和 CVE-2018-8174。我们使用披露的攻击节点来标记与攻击相关的子图。攻击子图的相应威胁情报是根据引用的 APT 报告手动生成的。我们选择了 ATLAS 数据集中与 CVE-2015-5122 和 CVE-2015-5119 相关的攻击场景作为测试集,其余作为训练集。
CICAPT-IIoT 型[50]由新不伦瑞克大学在工业 IoT 环境中捕获,专注于 APT 攻击的检测和分析。数据集是在三天内收集的。它模拟通过 Kali VM29 和 MITRE Caldera 执行的 APT1 技术,包括 20 多种不同的攻击技术和 8 种攻击策略。由于该数据集没有为攻击过程提供真实数据,因此仅用于测试 CLIProv 的泛化能力。
ATT&CK[39]是一个 TTP 数据集,由多位网络安全专家进行了注释,其中包含策略和技术的描述和示例。它包括 14 种策略、177 种技术和 10358 种威胁情报。
6.1.2参数设置
为了在出处图中实现对数序列的更细粒度分区,我们采用了 Section 5.2.2 中描述的子图分区算法,将出处图转换为系统行为子图。行为边界阈值设置为θ麦克斯=20m我n.为了解决来源日志中正样本和负样本之间的不平衡问题,我们使用 GPT-3 来增强威胁情报文本。增强文本的数量为n一个ug=3.最终数据集的详细统计信息如表 2 所示。
对于 CLIProv 模型,我们选择了预先训练的 RoBERTa 模型作为对数编码器和文本编码器。与 BERT 相比,RoBERTa 以其更高的稳定性和泛化性而闻名,对日志和文本的嵌入维度为 768。投影层由一个两层神经网络组成,每层有 128 个隐藏单元。在训练期间,我们使用了 64 的批量大小并执行了 100 个 epoch。为了选择最佳超参数,我们使用了网格搜索策略,初始学习率为 1e-5,退出率为 0.5。
表 2:最终数据集的统计信息
| 数据 | 用于训练的攻击图 | 用于训练的良性图 | 用于测试的攻击图 | 用于测试的良性图 | 威胁情报 |
| 学员 | 5 | 24,691 | 4 | 6,043 | 28 |
| 忒伊亚 | 7 | 8,979 | 3 | 3,824 | 44 |
| 地图集 | 37 | 6,001 | 21 | 3,907 | 148 |
| CICAPT-IIoT 型 | 0 | 0 | 58 | 6,222 | 0 |
6.2有效性
我们利用三个训练集:CADETS、THEIA 和 ATLAS 以及它们各自的威胁情报来训练 CLIProv 以学习对数序列和威胁情报的向量表示。然后在测试集上评估模型。表 3 显示了在节点级和图形级检测下每个测试集的调查结果。在节点级检测中,我们将已识别的攻击子图中的节点标记为攻击,将良性子图中的节点标记为良性,然后将识别的攻击节点与真实值进行比较。在图形级检测中,我们将识别的攻击子图与真实攻击子图进行比较。表 4 显示了在不同测试场景中识别的 TTP 结果。CICAPT-IIoT 数据集包含大量子图,仅显示前 5 种最常识别的技术。
表 3:不同数据集中攻击的检测结果
| 数据 | 节点级精度 (%) | 节点级召回率 (%) | 图形级精度 (%) | 图形级召回率 (%) |
| 学员 | 76.67 | 100 | 100 | 100 |
| 忒伊亚 | 82.14 | 100 | 100 | 100 |
| 地图集 | 62.09 | 100 | 100 | 100 |
| CICAPT-IIoT 型 | 52.38 | 84.36 | 60.96 | 86.21 |
表 4:在测试场景中识别的 TTP 结果
| 数据 | G1 系列 | G1 系列 | G1 系列 | G1 系列 | G1 系列 |
| CADETS_1 | T1071 | 那 | 那 | 那 | 那 |
| CADETS_2 | T1071 | T1055 | T1046 | 那 | 那 |
| 忒伊亚 | T1189 | T1546 | T1046 | 那 | 那 |
| ATLAS_M1h1 | T1204 系列 | T1105 系列 | T1083 | T1083 | 那 |
| ATLAS_M1h2 | T1071 | T1083 | 那 | 那 | 那 |
| ATLAS_M2h1 | T1569 | T1059 | T1083 | 那 | 那 |
| ATLAS_M2h2 | T1569 | T1059 | T1083 | 那 | 那 |
| ATLAS_S1 | T1071 | T1041 | T1041 | T1105 系列 | T1083 |
| ATLAS_S2 | T1204 系列 | T1569 | T1083 | T1571 | 那 |
| CICAPT-IIoT 型 | T1546 | T1055 | T1083 | T1005 | T1041 |
- 跨攻击场景泛化:在 CADETS 和 THEIA 数据集上的实验表明,CLIProv 在跨场景攻击检测方面具有很强的泛化能力。该模型能够识别潜在的攻击,即使它们没有出现在训练数据中。例如,在 THEIA 数据集内的浏览器扩展攻击场景中,CLIProv 正确识别了 Drive-by Compromise (T1189) 技术。虽然无法精确识别相应的技术浏览器扩展 (T1176),但通过将攻击行为与“网站”、“浏览器”等关键词相关联,成功识别了异常行为。这表明 CLIProv 可以捕获特征空间中与攻击行为高度相关的模式,从而在未知场景下保持一定的检测能力。
- 未知漏洞泛化:在 ATLAS 数据集上的实验表明,CLIProv 在跨漏洞攻击检测方面具有很强的泛化能力。即使训练集不包含特定漏洞,例如 ATLAS M1h1 场景中的 CVE-2015-5122,CLIProv 也能够通过识别与漏洞利用相关的行为模式来成功检测攻击,包括恶意链接 (T1204)、有效负载下载 (T1105) 和文件发现 (T1083)。这一结果表明,CLIProv 不仅依赖于已知的漏洞特征,而且能够在行为序列中学习和泛化潜在的攻击模式,从而保持对未知漏洞的检测能力。
- 跨数据集泛化:CICAPT-IIoT 数据集上的实验结果表明,即使模型没有在目标数据集上进行预训练,CLIProv 也能够识别大多数攻击行为。通过使用对比学习将威胁情报与来源日志保持一致,CLIProv 学习了攻击模式与系统活动之间的相关性。同时,该模型在训练过程中也学习了大量的良性行为,使其在处理未知攻击时仍然具有很强的判别能力。但是,由于知识的限制,CLIProv 在面对与已知攻击模式存在较大差异的技术时,可能会出现误报。例如,Wi-Fi 发现 (T1016) 涉及网络配置信息收集行为,它通过调用 cmd.exe 来执行命令 ipconfig 来访问关键配置文件 /etc/resolu.conf 和 /etc/hosts。这些作在正常的网络运维场景中也很常见。由于缺乏类似的攻击样本,该模型无法区分它们与正常网络运维的区别,导致误报。然而,CLIProv 仍然实现了 86.21% 的召回率。虽然这些结果表明存在一些改进的空间,但该模型对看不见的攻击技术保持相对较高的召回率的能力凸显了其泛化能力。
6.3比较研究
在本节中,我们将 CLIProv 与 CADETS 和 THEIA 数据集上的其他威胁检测方法进行比较和评估。
6.3.1查询基于图的威胁搜寻方法
作为一种基于外部情报的威胁搜寻方法,我们特别关注基于查询图的方法,这些方法利用威胁情报作为威胁查询的模板。我们选择 POIROT[12]和 ProvG-Searcher[9]进行比较评估。POIROT 是第一种方法提出查询图。通过在来源图中执行图匹配,POIROT 可以识别与查询图同构的攻击子图,这是基于查询图的检测方法的代表。ProvG-Searcher 是目前最先进的基于查询图的方法。与 POIROT 相比,ProvG-Searcher 引入了 GNN 来学习来源图的表示,并使用子图分区和语义匹配来识别攻击子图。值得注意的是,ProvG-Searcher 与 CLIProv 共享类似的架构。我们在 CADETS 和 THEIA 数据集上评估了所有三种方法,因为这些方法中使用的查询图来自 DARPA 的地面实况。表 5 显示了这三种方法在图级检测中的准确性和运行效率。
表 5:与基于查询图的方法的比较实验
| 方法 | 数据 | 图形级 FPR | 对齐分数 | 预处理时间 | 训练时间 | 威胁搜索时间 | 总时间 |
| 波洛 | 学员 | 0 | 0.89 | 那 | 那 | 5.45 小时 | 24.88 小时 |
| 忒伊亚 | 0 | 0.71 | 那 | 那 | 19.43 小时 | ||
| ProvG 搜索器 | 学员 | 0.43 | 0.79 | 11 分钟 | 10.83 小时 | 29 秒 | 11.20 小时 |
| 忒伊亚 | 0.25 | 0.79 | 11 分钟 | 18 秒 | |||
| CLIProv | 学员 | 0 | 0.77 | 11 分钟 | 8.72 小时 | 23 秒 | 9.15 小时 |
| 忒伊亚 | 0 | 0.84 | 15 分钟 | 8 秒 |
- 准确性。在图级检测中,Poirot 和 CLIProv 没有误报,证明了它们的检测准确性很高。相比之下,ProvG-Searcher 通过简化查询图中的实体类型来增强匹配能力,但丢失了进程名称、文件名和 IP 地址等高度区分特征。虽然这种简化可以提高算法的匹配效率,但很容易导致误匹配。ProvG-Searcher 在 CADETS 数据集中产生了 3 个错误匹配,在 THEIA 数据集中产生了 1 个错误匹配。为了评估生成的攻击场景的质量,我们使用 POIROT 的对齐评分方法来计算来自所有三种方法的攻击场景与真实图之间的对齐分数。如表 5 所示,即使不使用精确的查询模板,CLIProv 的比对分数也与其他两种方法的比对分数相当。
- 效率。POIROT 采用精确的图形匹配算法,确保高准确率和低误报率。但是,它在整个 Prosourceance 图上进行搜索和匹配,子图匹配的时间复杂度随着节点和边数量的增加呈指数增长。例如,THEIA 数据集包含 426.80K 个节点,边长为 1.60M,这使得 Poirot 的查询时间达到 19.43 小时。ProvG-Searcher 通过将子图嵌入到向量空间中来减少对穷举计算的需求,将匹配过程简化为查询和预计算的嵌入子图之间的比较。然而,由于来源图的复杂性,基于 GNN 的图表示学习比基于序列的模型更耗时,需要 10.83 小时来训练图表示模型。相比之下,CLIProv 只需 8.72 小时即可进行预训练,检测时间平均比 ProvG-Searcher 快 8 秒。此外,POIROT 和 ProvG-Searcher 都使用 7 个特定的查询图进行威胁搜索。当系统中有多个查询图时,查询时间会进一步增加。
- 可解释性。如图 1 的上部所示。2,POIROT 和 ProvG-Searcher 都从威胁情报中手动提取查询图,并在来源日志中执行匹配。这些方法生成的攻击场景仅代表攻击执行过程,缺乏固有的可解释性,需要安全专家进一步分析。相比之下,CLIProv 可以识别潜在的攻击技术,并为威胁搜寻提供有价值的参考。
6.3.2基于异常的检测方法
为了突出知识驱动方法的优势,我们将我们的方法与两种基于异常的威胁检测方法(Threatrace)进行了比较[18]和凯罗斯[10].Threatrace 和 KAIROS 对来源图中的法线节点进行建模以检测异常。Threatrace 认为攻击节点周围的邻居节点也有助于攻击过程,因此将攻击节点的 2 跳邻居节点也标记为异常。为了公平地进行比较,我们在 2 跳标记和原始标记的数据集上评估了上述三种方法,并在节点水平评估了它们的精度、召回率和准确性。比较结果如表 6 所示。
表 6:使用基于异常的方法的比较实验
| 数据 | 方法 | 训练数据(天) | 精度 (%) | 召回率 (%) | 累积碳 (%) |
| 学员 | 威胁 | 11 | 0.28 | 90.91 | 98.03 |
| 凯罗 | 3 | 61.11 | 100 | 99.99 | |
| CLIProv | 3 | 76.67 | 100 | 99.99 | |
| 学员 (2 跳) | 威胁 | 11 | 90.42 | 99.97 | 99.96 |
| 凯罗 | 3 | 100 | 100 | 100 | |
| CLIProv | 3 | 100 | 100 | 100 | |
| 忒伊亚 | 威胁 | 9 | 0.08 | 95.65 | 99.18 |
| 凯罗 | 3 | 75.00 | 100 | 99.99 | |
| CLIProv | 2 | 82.14 | 100 | 99.99 | |
| THEIA(2 跳) | 威胁 | 11 | 90.42 | 99.97 | 99.96 |
| 凯罗 | 3 | 100 | 100 | 100 | |
| CLIProv | 2 | 100 | 100 | 100 |
实验结果表明,Threatrace 的邻域聚合机制将大量邻节点标记为异常。具体来说,ThreaTrace 在 CADETS 数据集中识别了 12848 个攻击节点,在 THEIA 数据集中识别了 25297 个攻击节点。然而,根据 DARPA 攻击报告,CADETS 数据集仅包含 69 个攻击节点,THEIA 数据集仅包含 71 个攻击节点。Threatrace 将大量与攻击无关的邻居节点(如系统功能实体)误识别为攻击节点,增加了安全分析的工作量和误报成本。相比之下,KAIROS 和 CLIProv 生成的攻击场景更侧重于实际的攻击路径。在 THEIA 数据集浏览器扩展攻击场景中,CLIProv 识别了 24 个攻击节点和 29 个边缘,KAIROS 识别了 25 个攻击节点和 31 个边缘,有效地突出了实际攻击的关键步骤,帮助安全分析师快速发现攻击链。通过共同学习攻击行为和良性行为的行为模式,CLIProv 缓解了模型对良性行为分布的依赖性,可以用少量的训练数据实现最佳的检测性能,表现出更强的泛化能力和实际应用价值。
6.3.3消融研究
为了评估 CLIProv 不同成分的影响,我们进行了两组用于图级检测的消融实验。对于多模态特征表示方法,我们采用单个编码器架构,并将攻击序列识别建模为二元分类任务,仅使用来源日志进行训练和预测。通过微调日志编码器,我们评估了单模态数据上的攻击识别性能。对于攻击检测任务,我们使用双编码器架构来同时学习威胁情报和来源日志的向量表示。该模型通过对比损失和分类损失的联合训练,在保持语义对齐的同时加强了类判别能力,最终通过二元分类任务识别攻击行为。表 7 列出了不同模型的实验结果。
表 7:不同模型的比较实验
| 数据 | 方法 | 精度 (%) | 召回率 (%) | 累积碳 (%) |
| 学员 | 单模态 | 44.44 | 100 | 99.92 |
| Cont+分类器 | 33.33 | 100 | 99.87 | |
| CLIProv | 100 | 100 | 100 | |
| 忒伊亚 | 单模态 | 50.00 | 100 | 99.89 |
| Cont+分类器 | 36.36 | 100 | 99.77 | |
| CLIProv | 100 | 100 | 100 |
实验结果表明,单模态预训练模型的精度相对较低,主要是由于出处日志中数据严重不平衡。这种不平衡使模型的决策阈值向多数类倾斜,从而增加了将负样本错误分类为正样本的可能性。使用多模态学习,包括对比损失和分类损失,导致更多的假阳性。发生这种情况是因为攻击行为多种多样,而对比性预训练会导致攻击行为表示在语义空间中变得更加分散。这种离散模糊了分类边界,导致假阳性增加。CLIProv 利用威胁情报存储库生成查询文本,并测量这些文本与日志序列之间的距离,以便进行攻击检索。这种方法可以有效地适应不同的攻击模式,从而显著缓解数据不平衡的问题。它不仅提高了攻击检测的精度,还提高了模型处理复杂攻击行为的灵活性和可靠性。
6.4关键参数的影响
在上一节中,我们使用一组固定的超参数评估了 CLIProv。我们独立地对它们进行各种调整,并报告它们对检测和运行时性能的影响。
6.4.1文本增幅的数量 (n一个ug)
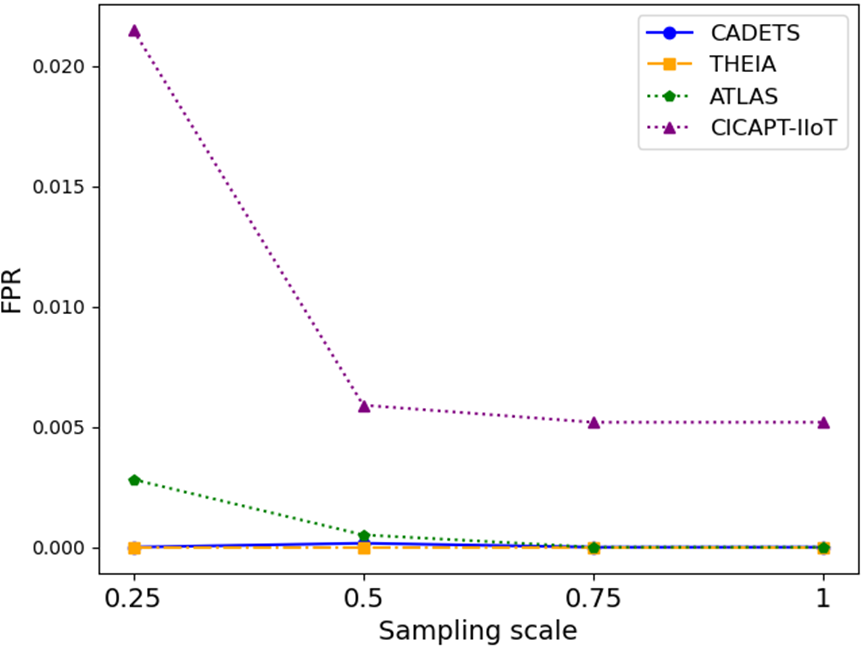
由于溯源日志中的攻击样本数量有限,训练数据存在严重的不平衡问题,不仅限制了模型的泛化能力,而且容易导致误报和假负。基于 GPT-3 的数据增强方法通过生成多样化的攻击描述来丰富攻击行为的语义表示,这有助于模型在语义空间中学习更细粒度的攻击行为表示,从而更好地区分攻击与正常行为。如图 1 所示。5、随着增强样本数量的增加,CICAPT-IIoT 数据集的真阳性率 (TPR) 显著上升,表明模型识别攻击的能力增强,泛化性能得到提高。此外,所有数据集的假阳性率 (FPR) 都有所下降,这反映出增强的样本有助于模型更准确地模拟攻击和正常行为之间的边界。
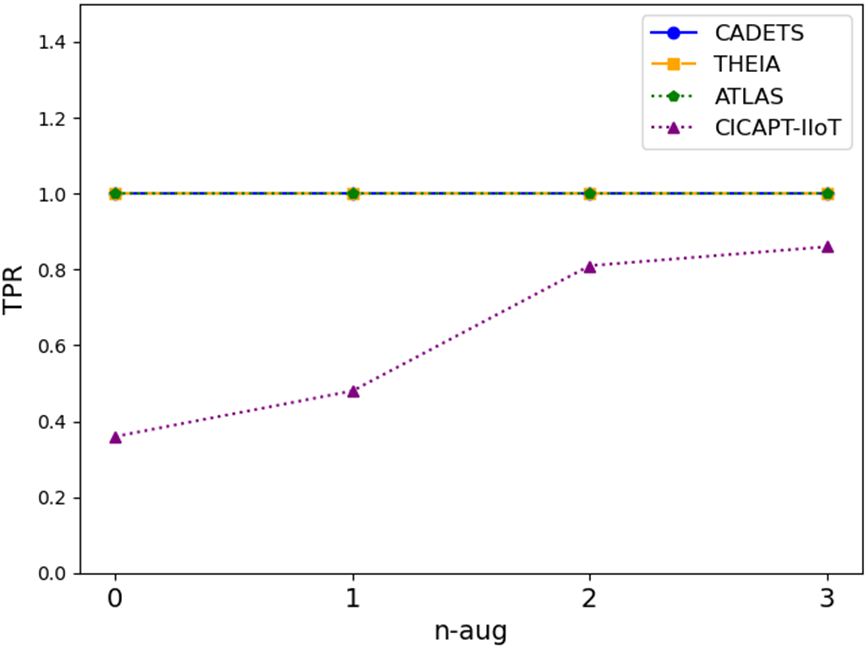
(一)
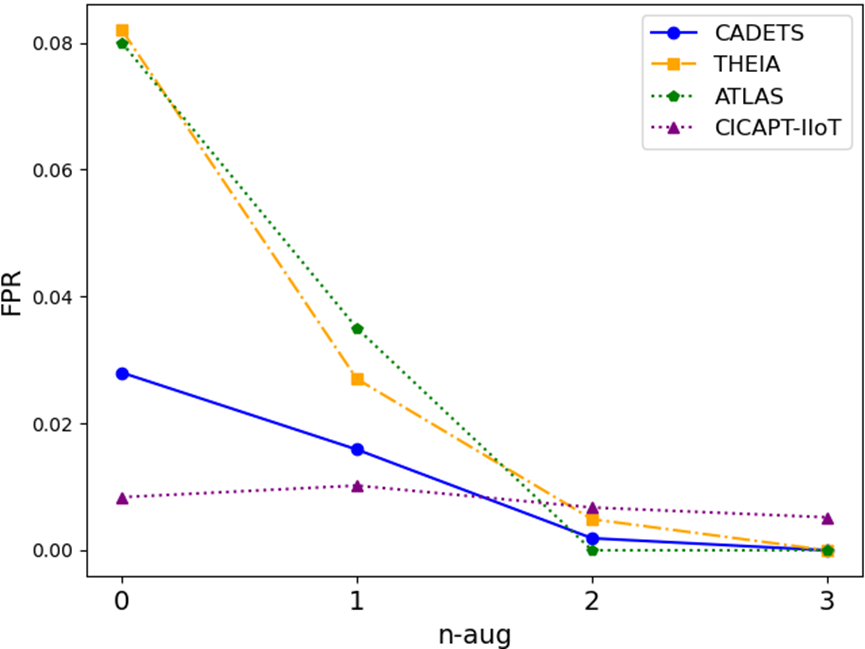
(二)
图 5:不同级别数据增强下的 TPR 和 FPR。
6.4.2训练数据中良性序列的采样百分比
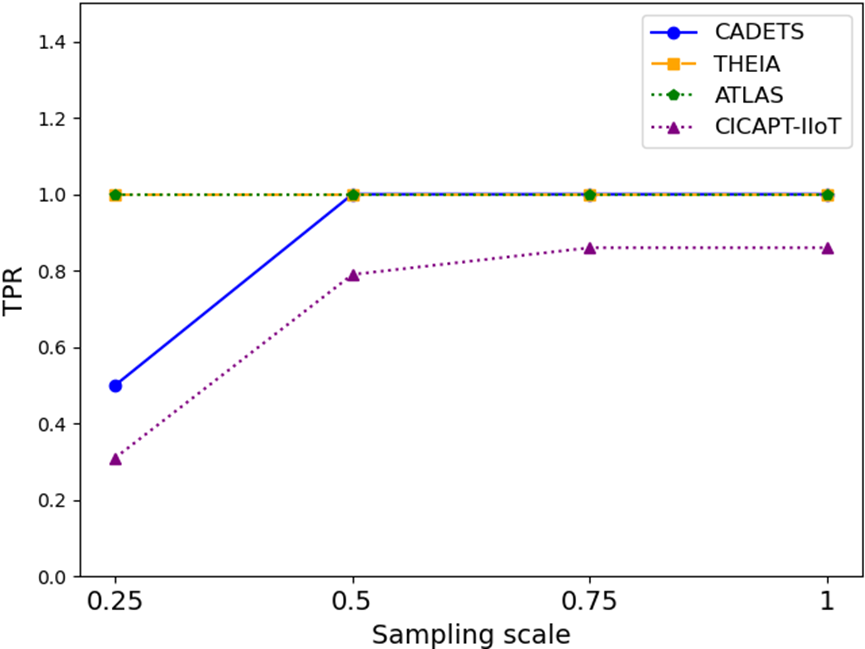
CLIProv 模型同时从攻击序列和良性序列中学习特征,将日志序列与威胁情报相匹配,而无需从所有良性序列中学习。我们对良性对数序列进行随机采样,并取 5 个实验结果的平均值,如图 1 所示。6. 结果表明,在 25% 的采样率下,CADETS 和 CICAPT-IIoT 数据集的 TPR 降低,表明对良性行为的学习不足,这导致模型将攻击序列错误分类为良性。此外,由于良性序列的采样率较低,ATLAS 和 CICAPT-IIoT 数据集都表现出更高的 FPR。但是,在 50% 的采样率下,所有数据集的性能都会提高。在 75% 的采样率下,实现了与使用所有良性序列进行训练相当的性能,与使用所有良性序列相比,训练时间缩短了 159 分钟。
(一)
(二)
图 6:良性序列采样量表对 TPR 和 FPR 的影响。
6.5可解释的攻击场景
在本节中,我们提供了一个示例,显示了 CLIProv 生成的可解释攻击图,如图 2 所示。7. 由于原始攻击图的尺寸较大,我们手动简化了它们,以仅突出显示关键攻击步骤。
THEIA 数据集的浏览器扩展攻击场景由三个系统行为子图组成,每个子图对应不同的威胁情报:(a) 路过式入侵 (T1189):“Mustard Tempest 使用路过式下载进行初始感染,经常使用虚假的浏览器更新作为诱饵。(b) 事件触发执行 (T1546): “Green Lambert 可以通过修改与 bash、csh 和 tcsh shell 关联的配置文件、登录和运行命令文件,在受感染的主机上建立持久性。”(c) 网络服务发现 (T1046):“APT32 执行网络扫描以搜索开放端口、服务、作系统指纹识别和其他漏洞。可以发现,在攻击行为子图中,威胁情报与攻击行为模式存在相似之处。第一阶段,攻击者利用 Firefox 漏洞,连接到外部 shellcode 服务器 141.43.176.203,使用 Firefox 的 Native Messaging 机制在浏览器扩展和原生应用程序之间建立通信。在第二阶段,pass_mgr 克隆并执行 dash shell,并启动恶意进程 gtcache 篡改系统日志文件 var/log/wdev,以控制配置文件的持久化。在第三阶段,profile 将恶意代码注入邮件进程,并使用邮件扫描外部 IP 的多个端口,以探索潜在的漏洞或攻击点。
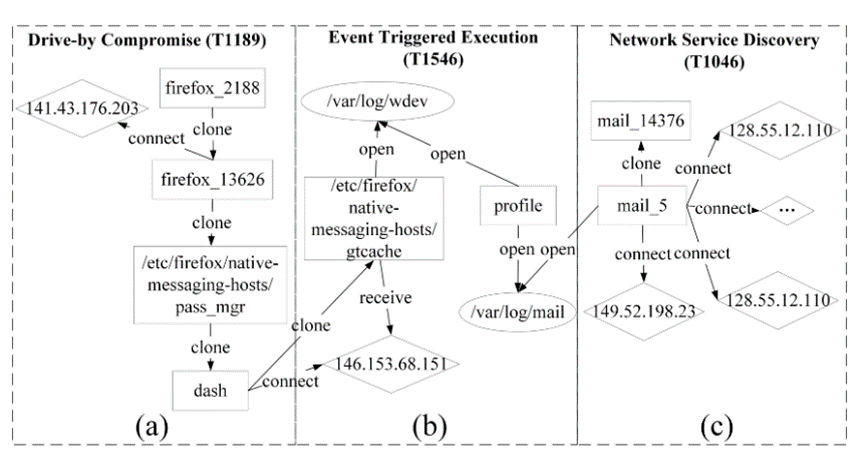
图 7:由 CLIProv 生成的可解释攻击图示例。
6.6运行时性能
在本小节中,我们评估了每个组件的运行时开销,并在表 8 中展示了结果。结果是在不同数据集的多个攻击场景中的平均值。随后,我们讨论了 CLIProv 生成的攻击场景中的攻击节点密度。
表 8:每个组件的开销
| 元件 | 平均持续时间 |
| 预处理 | 13.9 分钟 |
| 表示学习 | 8.72 小时 |
| 威胁搜索和调查 | 19.15 秒 |
| 每个系统行为子图 | 8.27 毫秒 |
平均而言,CLIProv 需要 13.9 分钟来处理来自给定数据集的单个攻击场景的日志。使用来自 3 个数据集的 14 个攻击场景的数据训练多模态模型需要 8.72 小时,持续 100 个周期。对于威胁搜索和调查,每个场景的查询时间平均为 19.15 秒,每个系统行为子图的相应日志序列处理时间为 8.27 毫秒。请务必注意,训练是在单个 GPU 服务器上执行的。如果实施分布式训练,则利用并行处理可能会显著降低总体开销。
7讨论和限制
7.1知识的局限性
CLIProv 通过多模态学习实现来源日志和威胁情报之间的语义对齐。通过利用来自威胁情报的攻击模式信息,该模型可以识别和理解攻击场景中的分层特征,从单个系统事件到一系列系统行为背后的更广泛意图。与基于查询图的方法相比,CLIProv 不需要准确的查询图,可以通过威胁情报提供的语义信息来解读日志行为。但是,作为一种基于知识的威胁搜寻方法,CLIProv 本身会受到其训练所依据的攻击知识范围的限制。尽管 CLIProv 表现出一定程度的泛化,但当遇到未经过训练的攻击模式时,其性能可能会下降。例如,涉及 Wi-Fi 发现等技术的攻击可能无法有效检测,这些技术与训练集中的攻击明显不同。一种可能的解决方案是在系统事件级别训练更精细的日志编码器。这种方法可以学习日志事件的语义,以提高其对以前未见过的攻击技术的适应性。
7.2攻击场景中的噪音
CLIProv 利用 APT 攻击的时空特性对溯源图进行分区,可以有效地隔离系统行为的不同子图。但是,在攻击过程中,不可避免地会调用一些系统服务相关的文件,导致生成的攻击场景包含与攻击无关的节点。为了解决这个问题,我们可以考虑集成基于异常的调查方法。通过训练新模型来学习良性节点的行为模式,或者通过使用频率和统计技术对系统节点的良性进行评分,可以进一步从攻击场景中过滤掉不相关的节点。
7.3虚假威胁情报
基于外部情报的威胁搜寻方法的一个潜在风险是虚假情报,这可能导致对检测系统的数据中毒攻击。知情的攻击者可能会通过注入虚假威胁情报来纵系统[51,52],导致模型学习与攻击者的恶意意图一致的错误输入。为了降低这种风险,Mahlangu[53]通过验证情报来源来确保情报数据库的可信度,而 Mitra 等人。[54]建议从来源图谱生成网络安全知识图谱,计算实体和关系的质量分数以评估其可信度。在未来的训练中,将虚假情报样本作为对抗性训练的负面样本可以提高模型对虚假情报攻击的鲁棒性。
8结论
在本文中,我们介绍了 CLIProv,这是一个基于知识的系统,可从来源日志中识别 APT 攻击并生成完整的攻击场景。CLIProv 通过多模态学习创新性地将日志序列与威胁情报保持一致,从而支持对来源日志中的攻击行为进行语义搜索。我们在四个数据集中评估了 CLIProv,证明了它在威胁识别方面的高精度和最小的时间开销。该系统生成可解释的攻击场景,为分析师的调查提供有价值的见解。在未来的工作中,我们的目标是开发一个事件级日志预训练模型,该模型在事件级别结合了语义理解和上下文关系。该模型将增强系统准确捕获日志事件之间的关联和因果关系的能力,通过细粒度的语义学习提高其对新攻击方法和技术的适应性。



















 729
729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









