







Beautiful Soup
官方文档:http://beautifulsoup.readthedocs.io/zh_CN/latest/
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
首先在python安装位置找到Scripts文件夹,输入cmd,使用pip install beautifulsoup4命令安装Beautiful Soup
解析html:
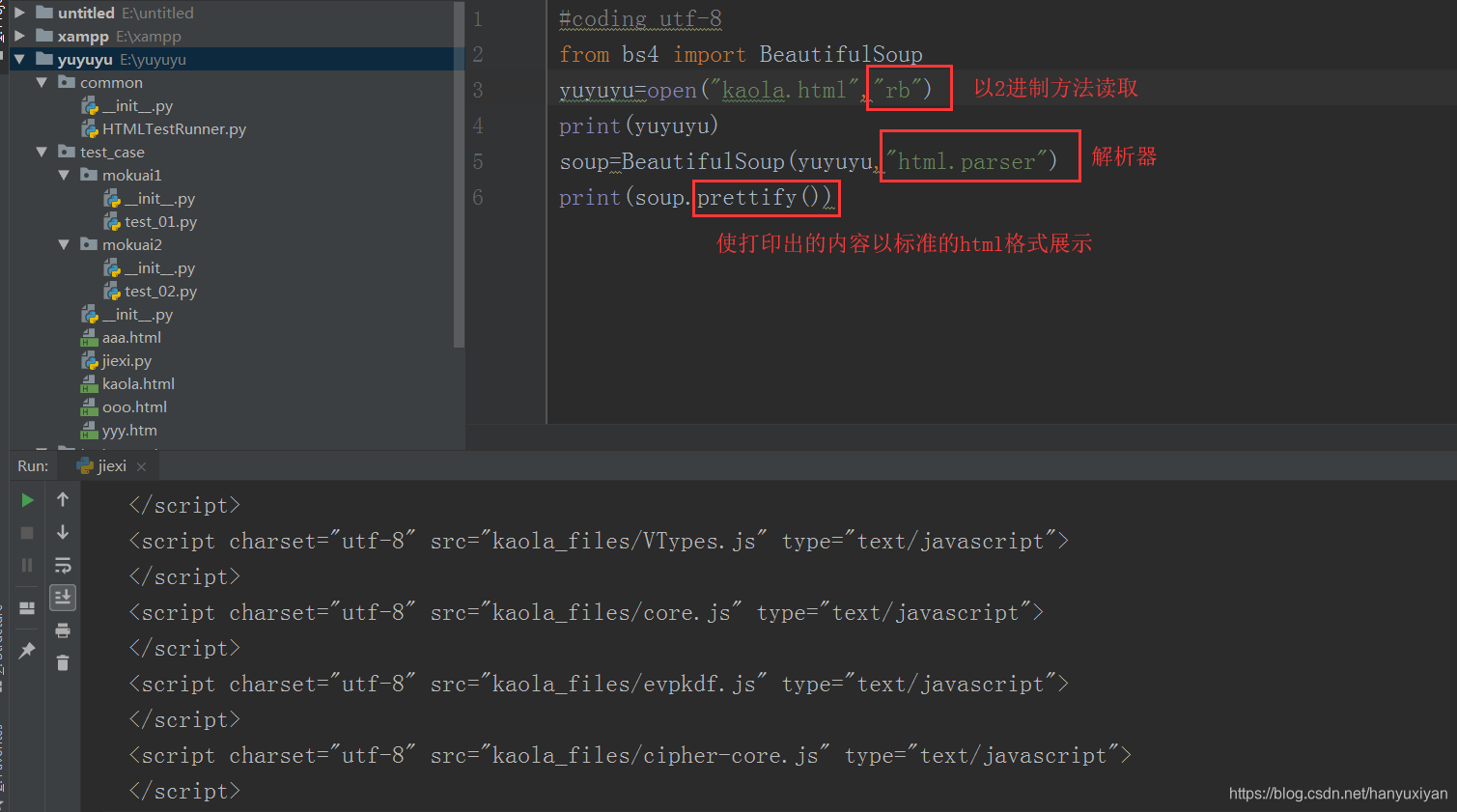
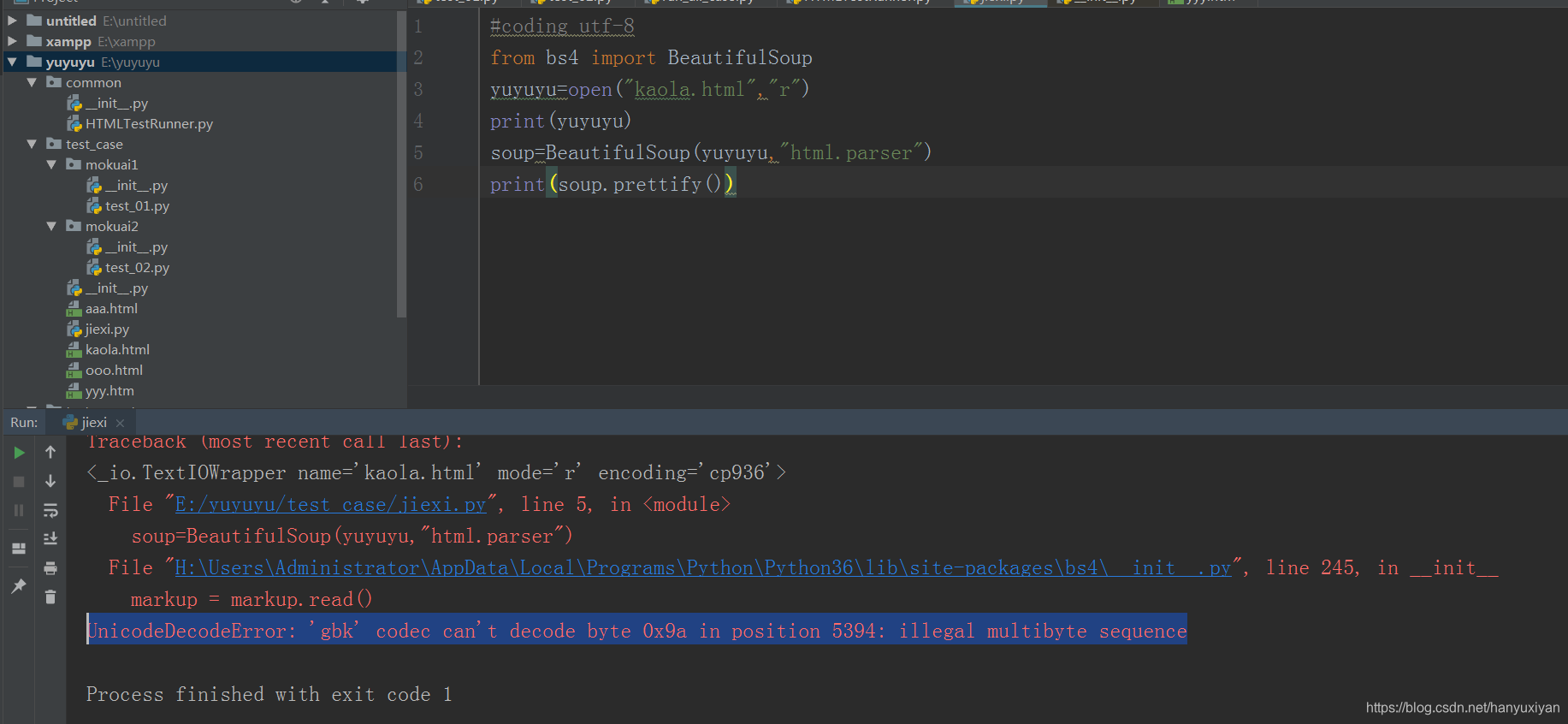
开始在没有以2进制方式读取html文件时,提示转码问题:
UnicodeDecodeError: 'gbk' codec can't decode byte 0x9a in position 5394: illegal multibyte sequence
html所有对象可以归纳为4种:
Tag : 标签对象,如:<title>百度_百度搜索</title>,这就是一个标签
NavigableString :字符对象,
BeautifulSoup :就是整个html对象
Comment :注释对象,如:!--for HTML5 --,它其实就是一个特殊NavigableString
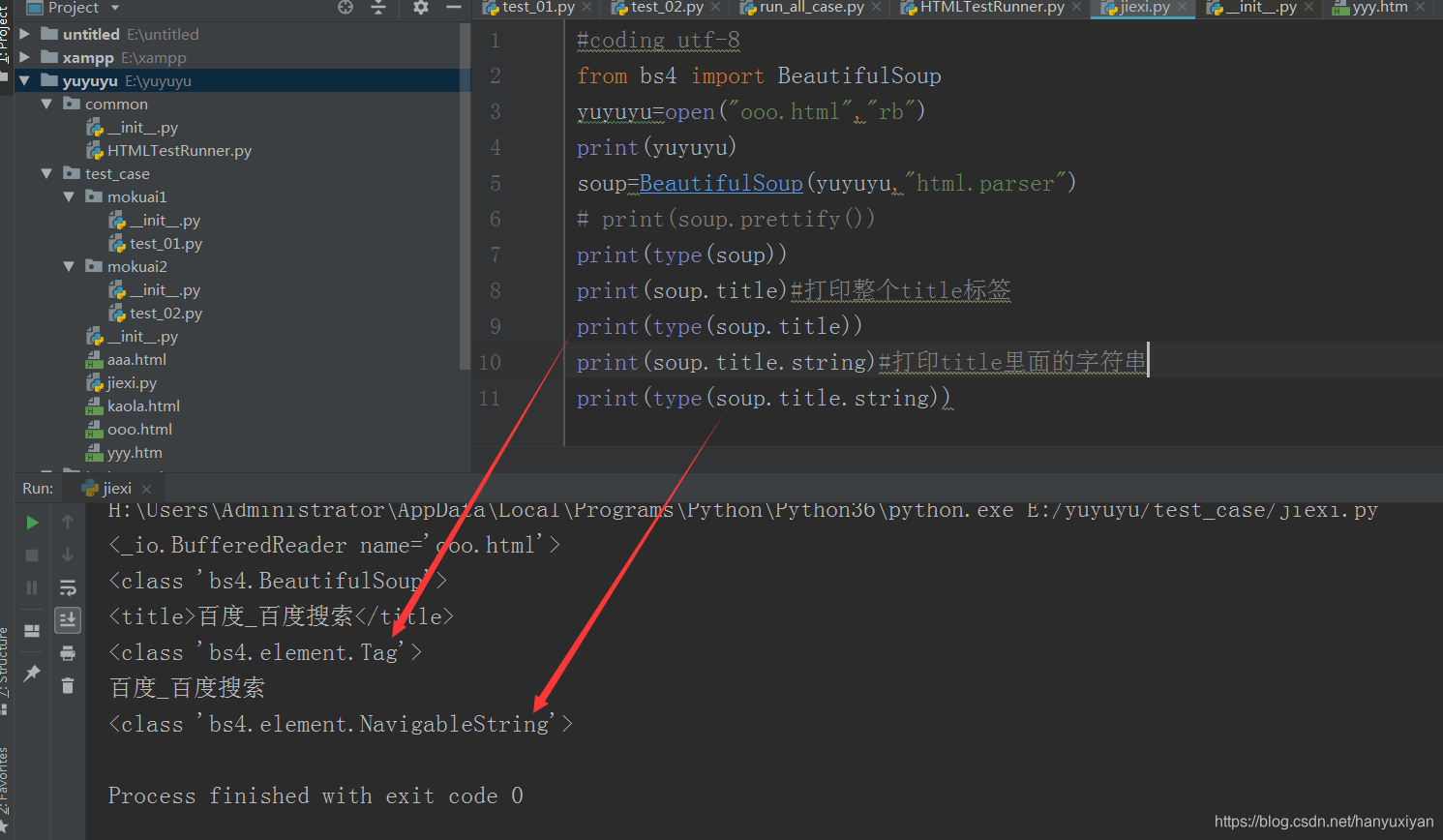
通过标签的名称,来获取tag对象,如果有多个相同的标签名称,返回的是第一个.
tag.attrs可以打印出所有的属性.
由于class属性一般可以为多个,中间空格隔开,所以class属性获取的是一个list类型
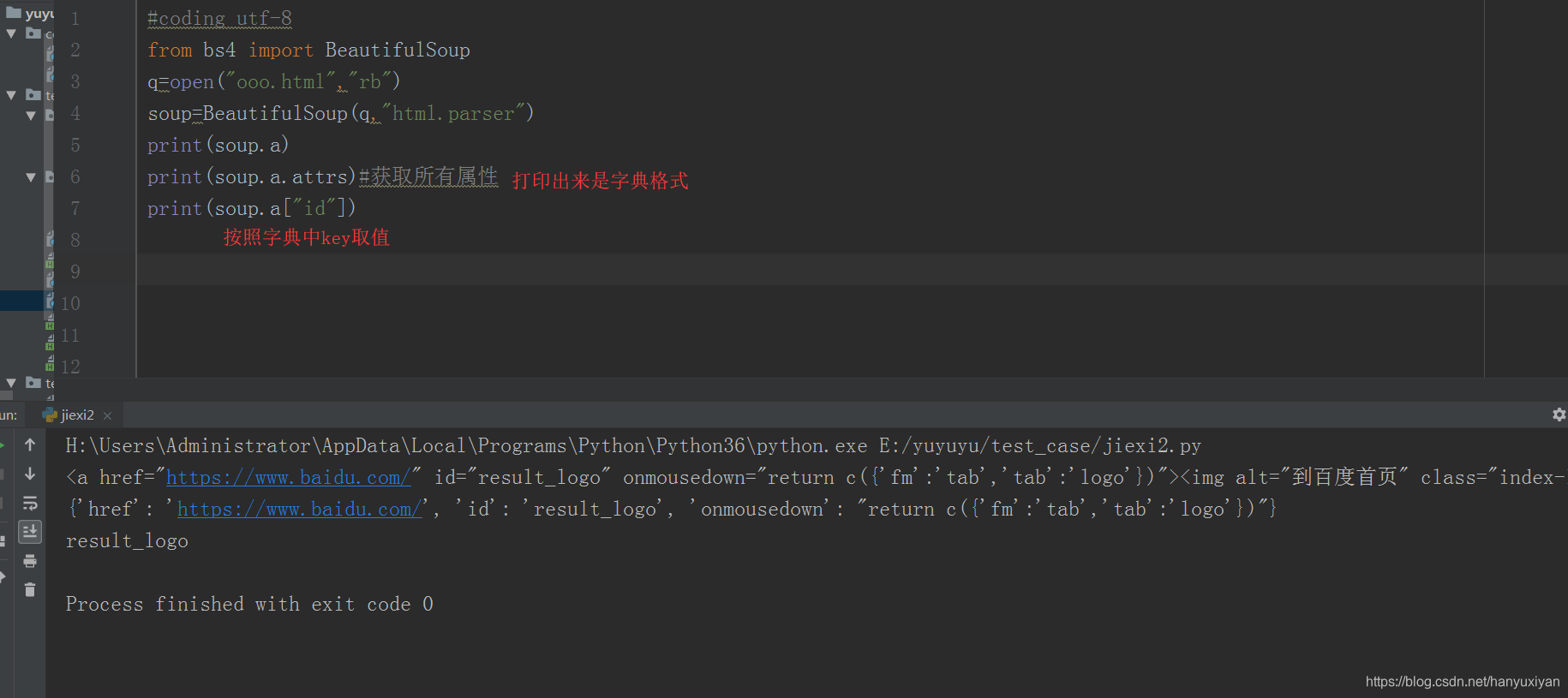
find_all查找的是一个list对象。find只查找第一个,有多个时返回第一个
get_text() 获取tag标签下所有的文本
replace替换字符串里面的特殊字符
contents返回所有子Tag(list)

下载图片
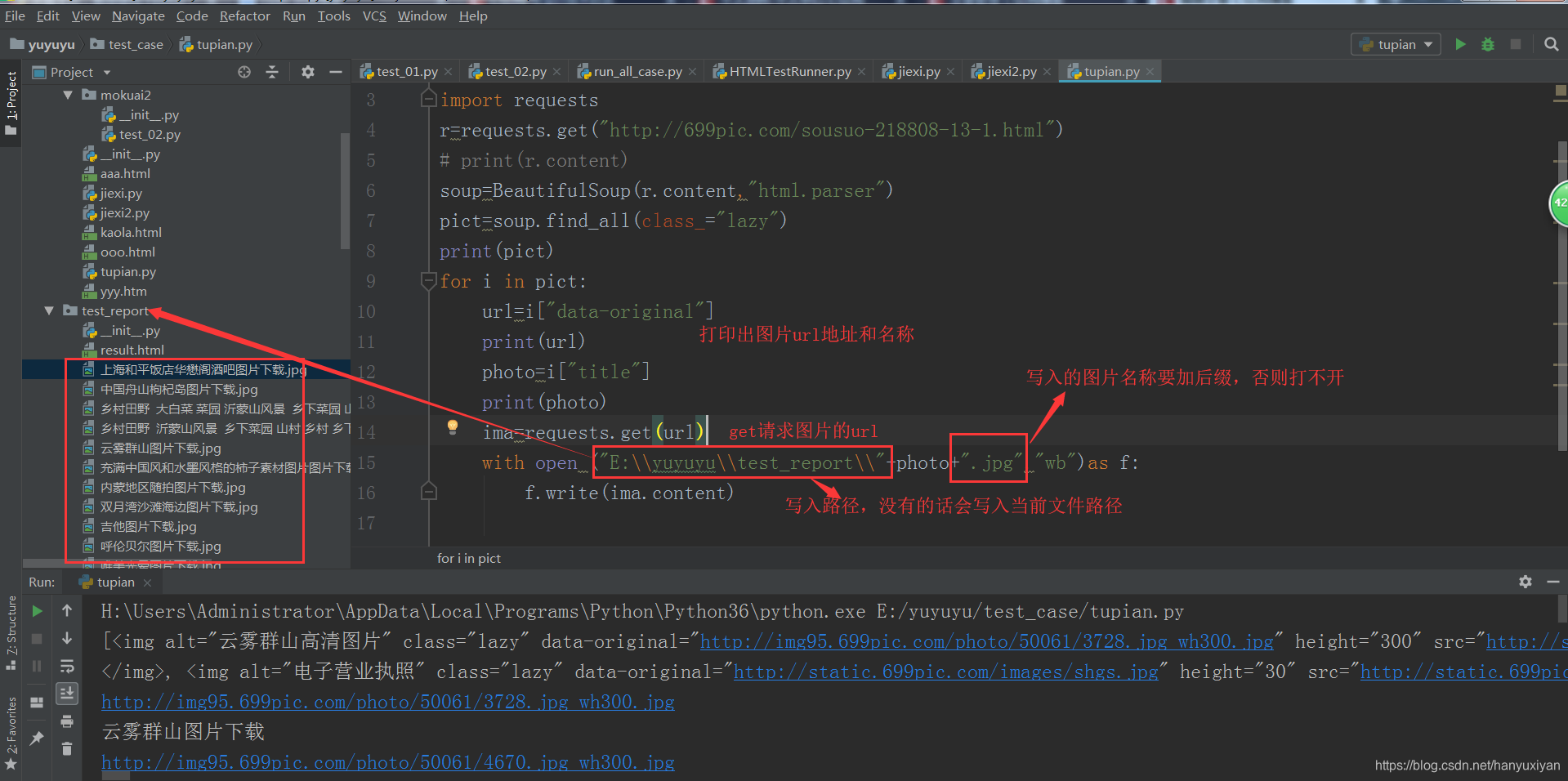
生成一个文件,保存图片地址:
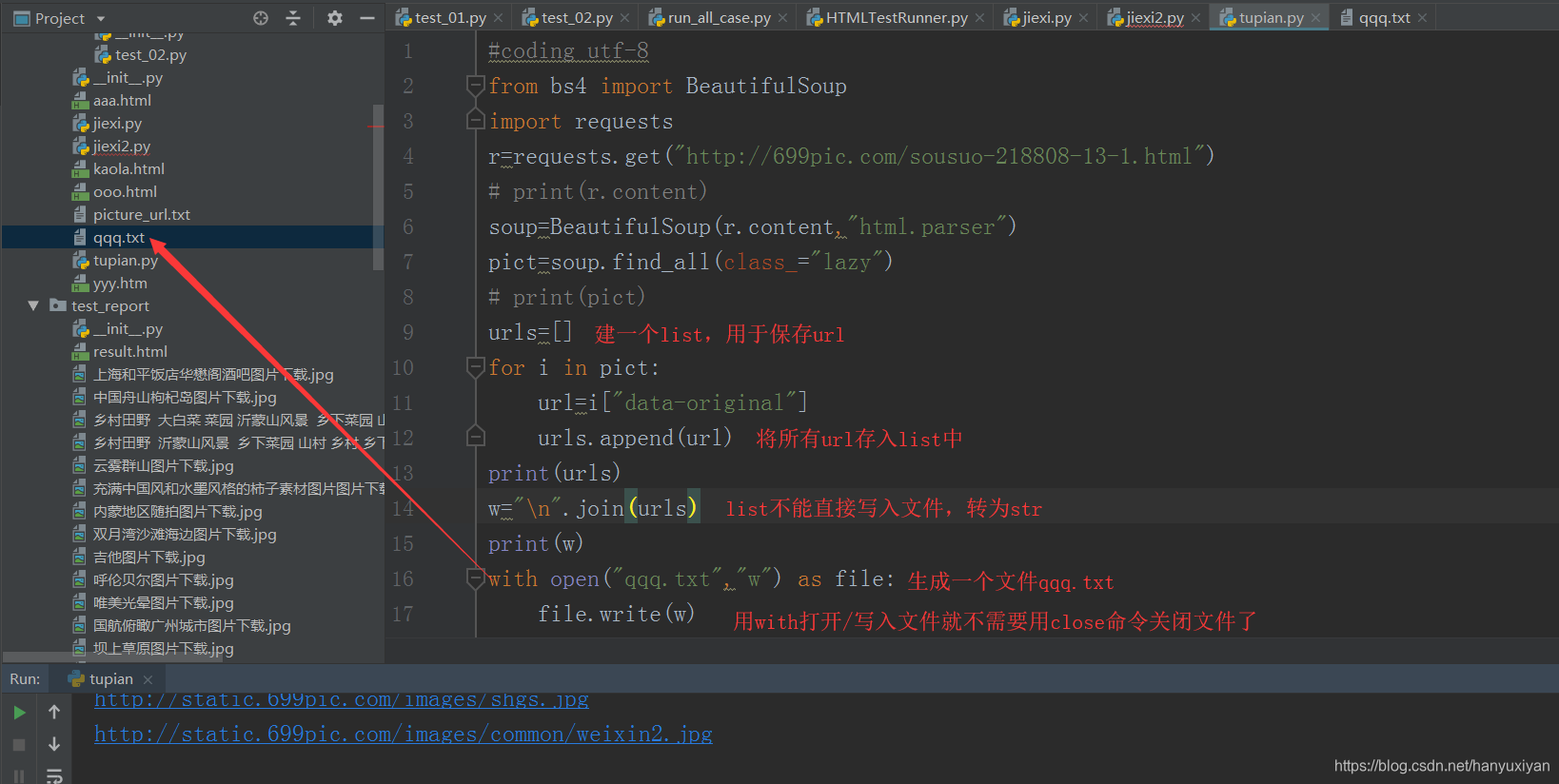 文件名或其他有空时异常报错,只需加以下代码跳过异常
文件名或其他有空时异常报错,只需加以下代码跳过异常
打印异常信息:
try:
..
except Exception as msg: #Exception是捕获所有异常
print(msg)
直接跳过异常
try:
..
except Exception as msg:
pass
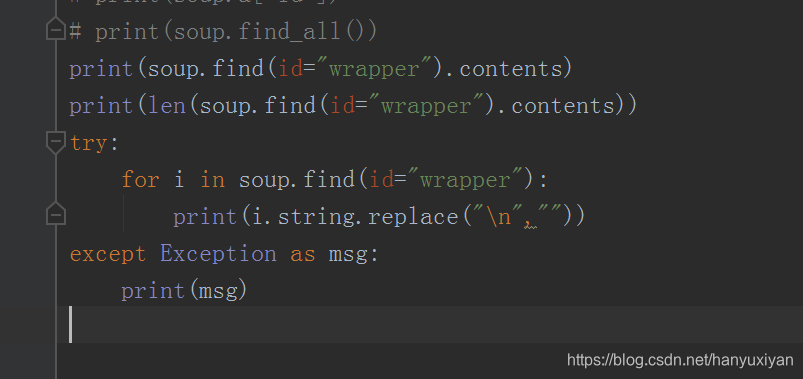
如果无法一次性找到一个Tag,那就先找他父节点

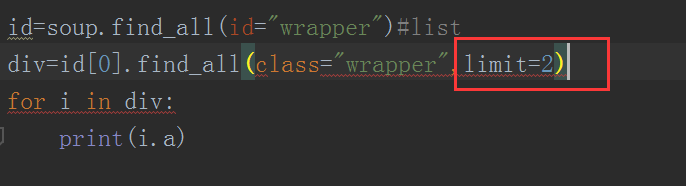
find_all方法返回全部的搜索结构,可能会搜索很慢。如果不需要全部搜索时,可以使用limit参数限制返回结果的数量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









