






目录
Redis中提供的集群方案一共有三种方式
主从复制
哨兵模式
分片集群
一 主从复制
想要提升Redis的并发能力,就要搭建主从集群,实现读写分离,毕竟单节点的Redis的并发能力是有上限的。如图,主节点可以进行写操作,从节点只能进行读操作。
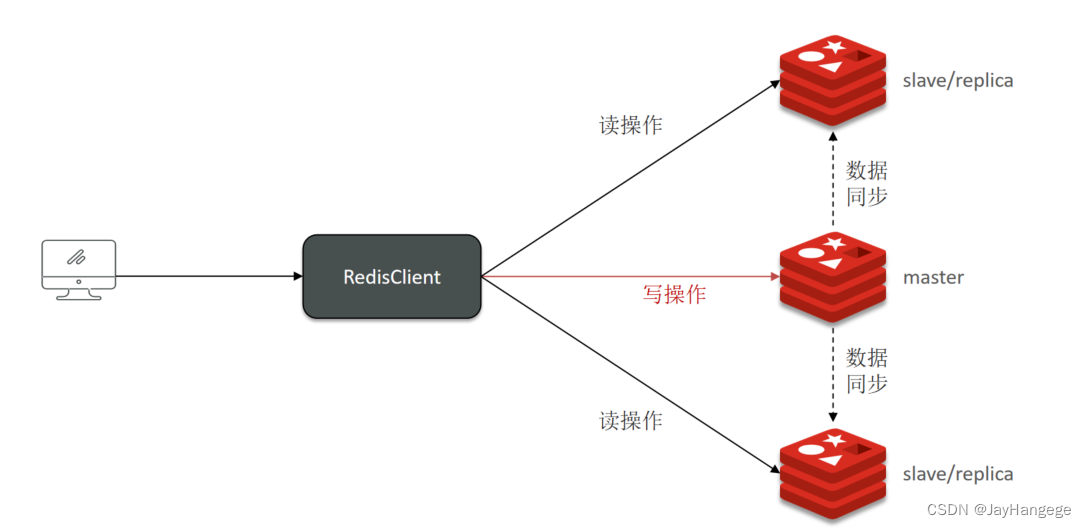
但是这又引出了另外一个问题,那就是如何保证主节点和从节点之间的数据一致呢?主从数据是如何进行同步的呢?
主从同步
1 全量同步

1.从节点第一次请求主节点进行数据同步时,会执行replicaof命令。
2.发送自己的id和偏移量给主节点。
3.主机此时会判断是否是第一次进行同步。
4.如果是第一次,那么就会返回主节点之中的版本数据。
5.从节点则会保存版本信息。
6.主节点会执行bgsave命令,然后生成一个RDB文件,RDB(Redis Database Backup file)数据备份文件,也是Redis数据快照。简单来说就是把内存中所有数据记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照,恢复数据。
7,然后会将这个RDB文件发送给从节点。
8.从节点则会清空本地数据,执行该RDB文件。
9.在生成RDB文件的同时,主节点还会记录RDB期间所有发送过来的命令,保存到一个repl_baklog文件当中。然后发送给从节点。
10.从节点执行log文件,此时就达到了真正的主从数据同步。
2. 增量同步
假如从节点重启以后恢复,此时主节点和从节点之间数据已经有了差异,从节点会发送同步请求,那么此时,主节点还是会判断是否是第一次连接,如果不是,那么就发送log文件,此时从节点就可以进行增量同步。
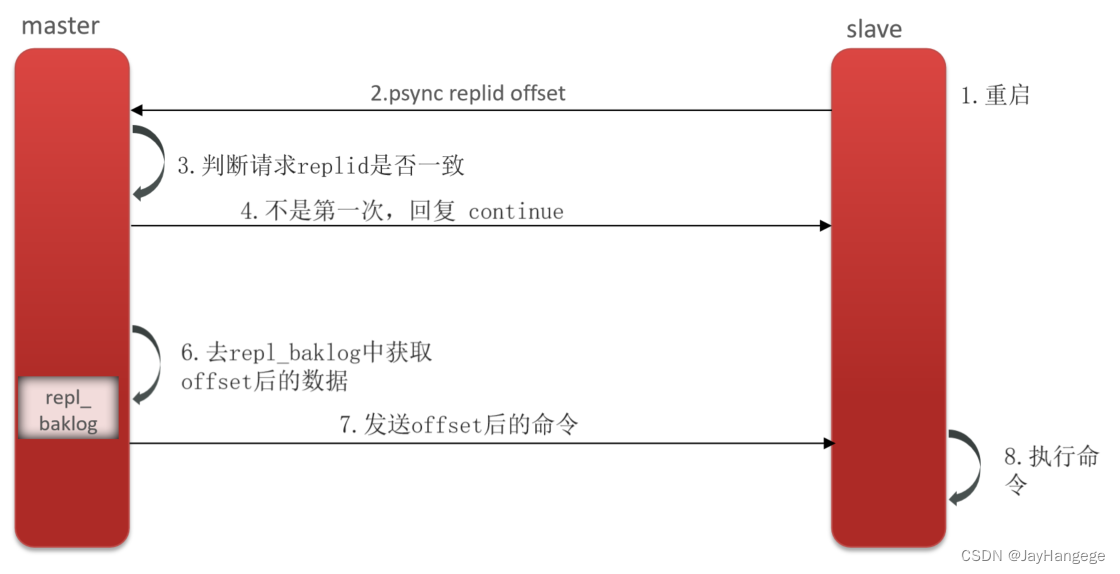
值得注意的是,主节点的数据是存储在一个环形数组中的,如果这个数据的偏移量已经超过了数组的长度,那么增量同步也是会丢失数据的,此时就只能再进行全量同步了。
二 哨兵机制
Redis提供了哨兵机制来实现主从集群的自动故障恢复。
哨兵提供了三个功能:
监控:哨兵会不断地检查主节点和从节点是否按照预期工作
自动故障恢复:如果主节点故障,那么哨兵会选择一个从节点来担当主节点
通知:哨兵充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新的信息推送给Redis的客户端。
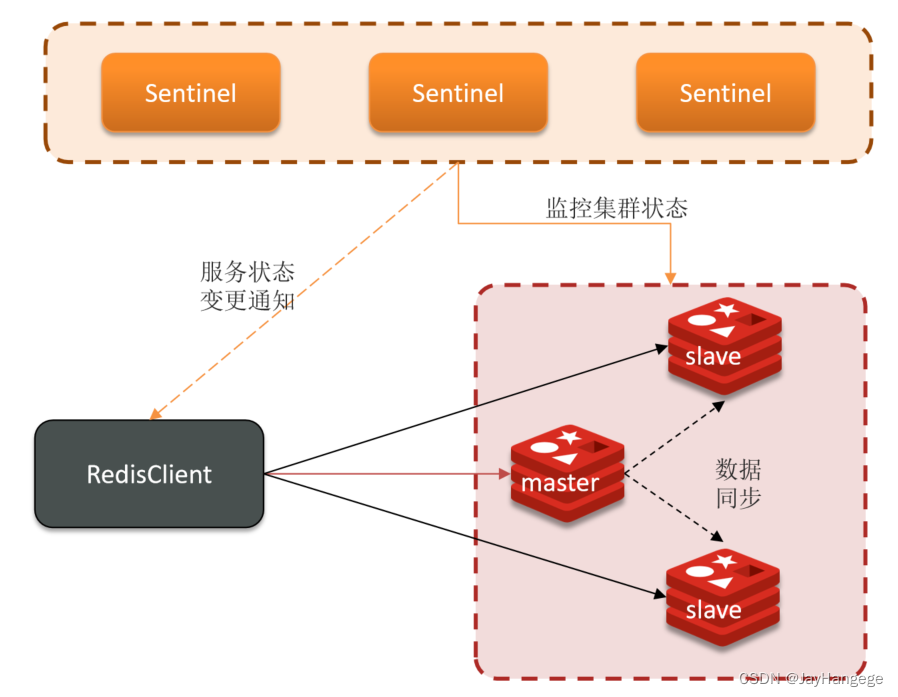
服务状态检测
主观下线:当某哨兵节点发现某个redis实例未在规定时间内响应的话,则认为该节点下线。
客观下线:当哨兵群有一半以上认为某个redis实例主观下线,则其也会客观下线,因此哨兵数量一般都为奇数。
哨兵选主规则
首先判断主从节点断开时间长短,如超过指定值就排除该从节点。
然后判断从节点的slave-priority值,越小优先级越高。
如果优先级一样,那么判断offset值,越大优先级越高。
最后判断slave节点的运行id大小,越小优先级越高。
脑裂(不同的网络分区)
如果当前主节点突然出现暂时性 “失联”,而并不是真的发生了故障,此时监听的哨兵会自动启动主从切换机制。当这个原始的主库从假故障中恢复后,又开始处理请求,但是哨兵已经选出了新的主库,这样一来,旧的主库和新主库就会同时存在,这就是脑裂现象。
脑裂最严重的问题就是客户端不知道往哪个节点写数据了。结果就是不同的客户端会给不同的服务器写数据,从而造成数据丢失的现象。
简单来说就是,主节点让从节点执行它的RDB文件,此时从节点会删除自己的数据,从而噪声数据丢失。
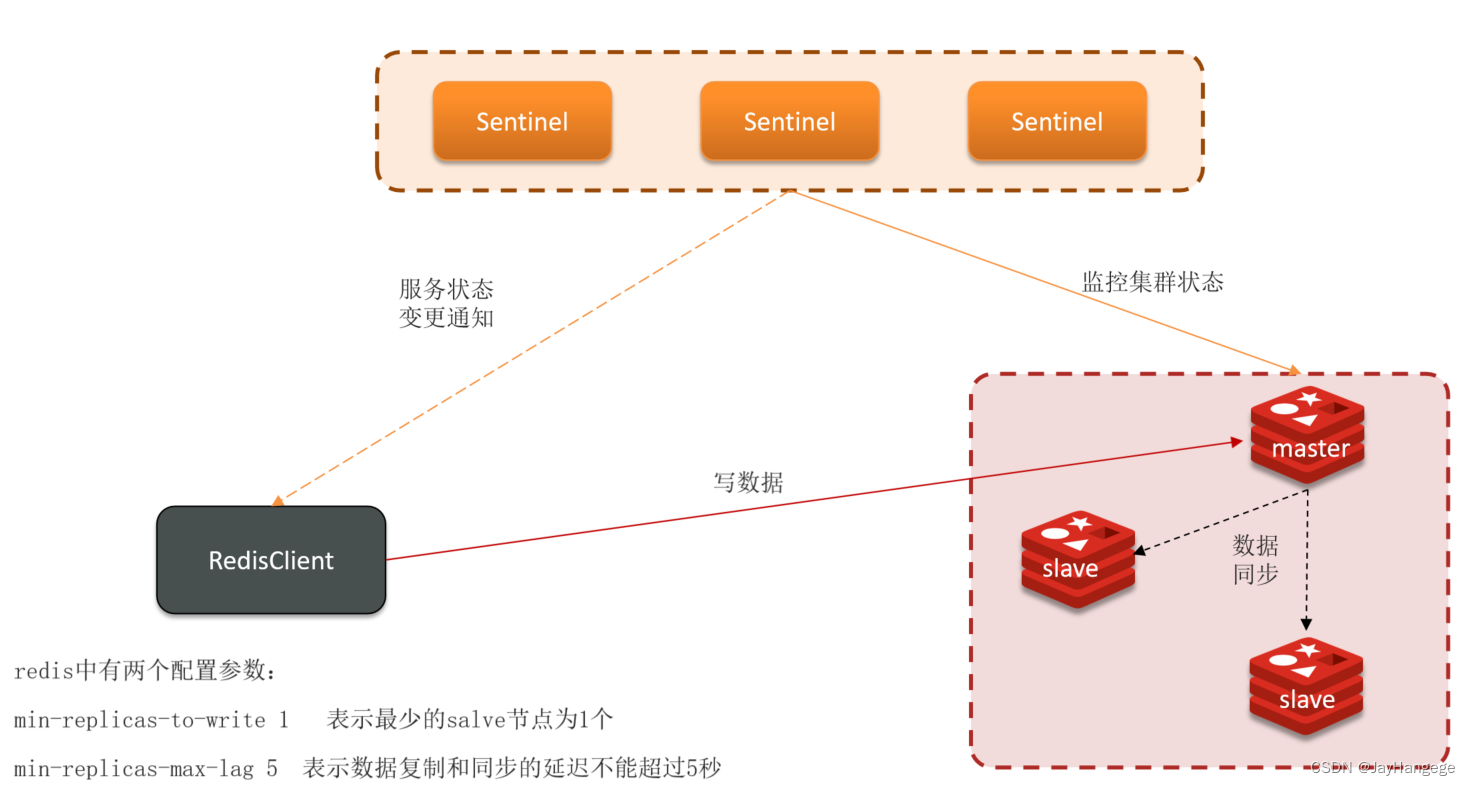
redis中存在两个配置参数
min_replicas_to_write N
min_replicas_max_lag 10
第一个参数标识,一个节点最少要有N个从节点,才可以进行写操作。
第二个参数标识,用于配置 master 多长时间(秒)无法得到从节点的响应,就认为这个节点失联。我们这里配置的是 10 秒,也就是说 master 10 秒都得不到一个从节点的响应,就会认为这个从节点失联,停止接受新的写入命令请求。
三 分片集群
当有海量数据和高并发问题时,就应该采用分片集群的结构。
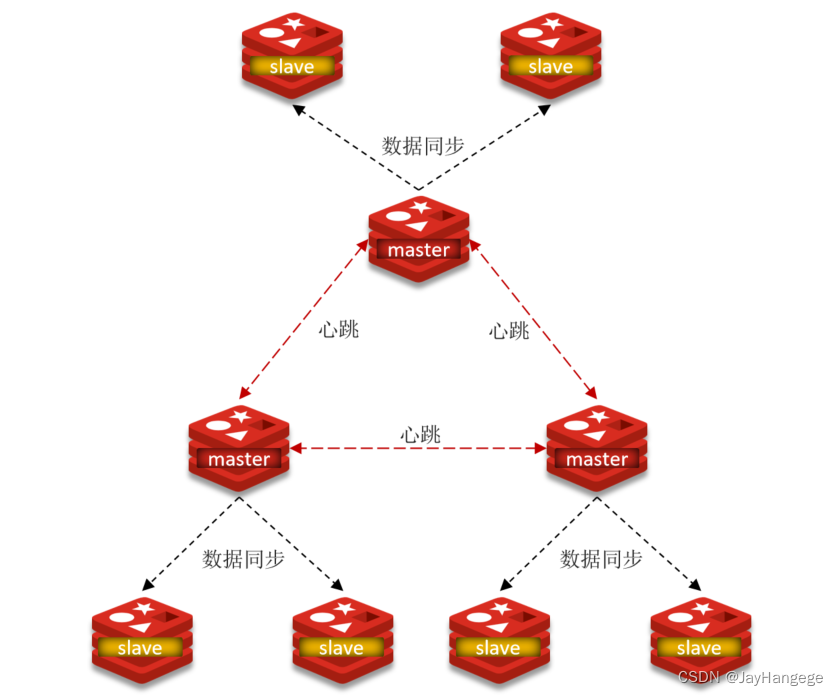
集群中有多个主节点,且每个主节点保存不同数据
每个主节点有多个从节点
主节点之间通过心跳进行检测,充当哨兵
客户端可以访问任意节点,最终都会被转发到正确的节点
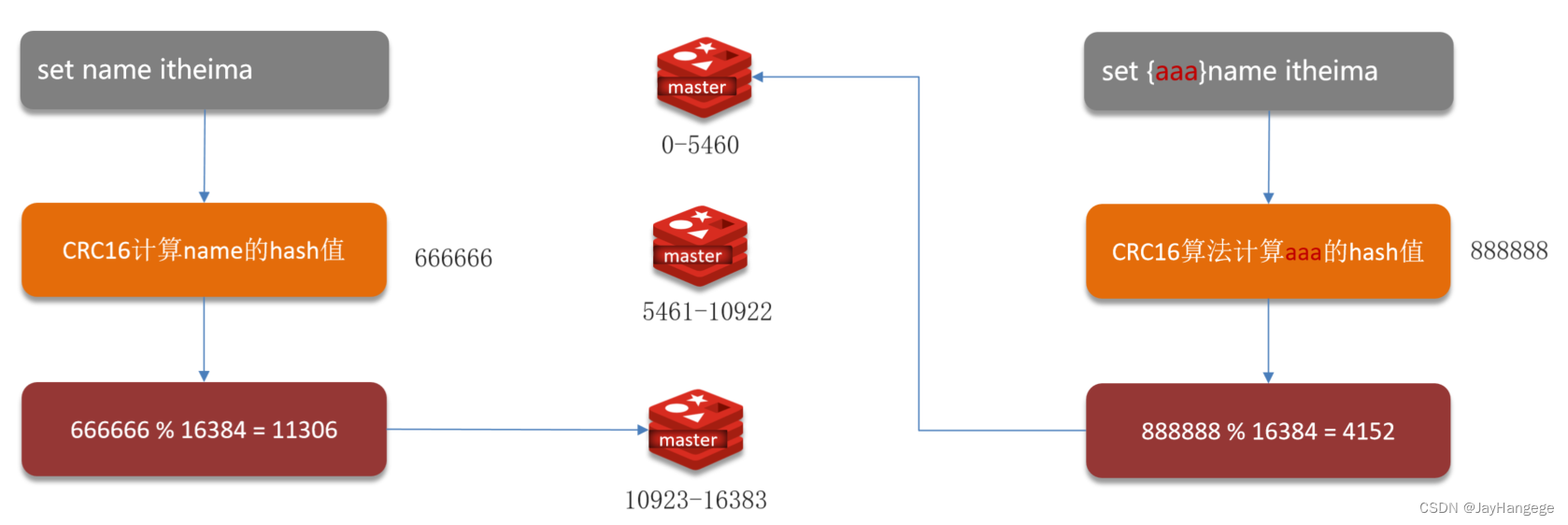
数据读写
分片集群中引入了哈希槽的概念,比如说Redis有16384个哈希槽,每个key通过CRC16检验之后会算出一个值模16384,得到的值就在16383之间,然后根据最后的结果快速得到数据在哪一个主节点之上。同一类数据还可以用{ }扩起来计算其有效果值,可以使得查找更为方便。

















 958
958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









