




 本文介绍了一个使用Nodejs实现新闻爬虫的项目,包括爬取多个新闻网站的新闻信息,如标题、作者、时间等,并将数据存储在数据库中。此外,还讲述了如何使用前端技术如HTML、CSS和JavaScript搭建查询网站,对网站进行美化和功能扩充,实现新闻的搜索和展示。整个项目涵盖了网络爬虫、数据库操作和前端开发的综合应用。
本文介绍了一个使用Nodejs实现新闻爬虫的项目,包括爬取多个新闻网站的新闻信息,如标题、作者、时间等,并将数据存储在数据库中。此外,还讲述了如何使用前端技术如HTML、CSS和JavaScript搭建查询网站,对网站进行美化和功能扩充,实现新闻的搜索和展示。整个项目涵盖了网络爬虫、数据库操作和前端开发的综合应用。
文章目录
Nodejs, 可以简单理解它是一个内置有
chrome V8引擎的
JavaScript运行环境,他可以使原本在浏览器中运行的
JavaScript有能力跑后端,从而操作我们数据库,进行文件读写等。同时, 由于其包管理工具
npm丰富的生态, 我们可以用
Node.js及其包罗万象的开源库实现各种各样的需求. 本文即用
Node.js实现新闻爬虫及其展示网站.
- 核心需求
(1)、选取3-5个代表性的新闻网站(比如新浪新闻、网易新闻等,或者某个垂直领域权威性的网站比如经济领域的雪球财经、东方财富等,或者体育领域的腾讯体育、虎扑体育等等)建立爬虫,针对不同网站的新闻页面进行分析,爬取出编码、标题、作者、时间、关键词、摘要、内容、来源等结构化信息,存储在数据库中。
(2)、建立网站提供对爬取内容的分项全文搜索,给出所查关键词的时间热度分析。
- 技术要求
(1)、必须采用Node.JS实现网络爬虫
(2)、必须采用Node.JS实现查询网站后端,HTML+JS实现前端(尽量不要使用任何前后端框架)
项目基本步骤:
Node.js爬新闻网站, 爬取新闻页面的url, 关键词, 内容, 作者, 发布时间等信息.- 将爬取的信息存储于
mysql数据库中. - 利用
Nodejs框架Express搭建基础的查询网站. - 利用
css,html,js等前端技术对网站进行功能扩充和美化.
1. Node.js爬取新闻网站
这里以网易新闻(https://news.163.com/)为例, 帮助理解Nodejs爬虫的原理, 从而触类旁通的运用到其他网站.
网易新闻的主页包含许多新闻页面的链接, 我们知道网页的html页面中的href属性就包含这个链接, 我们先提取出网易新闻主页的所有链接, 再用JavaScript正则表达式对链接进行判断, 提取出所有新闻页面. 新闻页面中的html代码包含所有我们想要的信息, 找到这些信息所在的位置(所在标签, 类, 属性), 提取出来即可.
该步骤需要用到request, iconv-lite, cheerio等库, 利用npm install 库名即可安装. 具体可以看代码和下面的注释.
代码整体结构: request请求访问主页->提取出主页html代码的的所有链接->对链接进行判断, 筛选出新闻页面->提取出新闻页面中的html代码并解析->将解析出的信息存储在json文件并输出
使用工具包(具体用处见代码注释):
fsrequestcheeriohttpsiconv-litesuperagentdate-utils
// 新闻来源
let source_name = "网易新闻";
// 编码格式
let myEncoding = "utf-8";
// 主页URL
let seedURL = 'https://www.163.com/';
let myURL = "";
// Jquery全局对象
let seedURL_format = "$('*')";
// 正则表达式
let url_reg = /article/;
// 导入所需模块
let fs = require('fs'); // 文件库, 最后的新闻对象存入JSON文件中
let myRequest = require('request'); // 对网站发出请求
let myCheerio = require('cheerio'); // 对请求得到的html代码进行解析为Jquery对象
let https = require('https'); // 对网站发出https请求
let myIconv = require('iconv-lite');// 对网站进行uft8编码
let superagent = require('superagent'); // 根据url得到网站的html代码
require('date-utils'); // 日期操作
// 防止网站屏蔽我们的爬虫, 详细见下方headers
let headers = {
'user-agent': "user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36"
};
// request模块异步fetch url
function request(url, callback) {
let options = {
url: url,
encoding: null,
headers: headers,
// 响应时间
timeout: 10000
}
myRequest(options, callback);
}
request(seedURL, function(err, res, body) {
// 回调函数 err为错误信息, 无错误则为null, res为回调函数得到的结果
// 用iconv转换编码, 存入html中
let html = myIconv.decode(body, myEncoding);
// 对得到的html代码进行解析
let $ = myCheerio.load(html, {
decodeEntities: true});
let seedurl_news;
try {
seedurl_news = eval(seedURL_format);
} catch(e) {
console.log('url列表所处的html模块识别出错' + e)};
seedurl_news.each(function(i, e) {
try {
// 提取出网站的所有href链接并做判断, 无则跳过到下一次循环
let href = "";
href = $(e).attr("href");
if (typeof href == "undefined") {
return;
}
myURL = href;
// 对得到的链接进行规整
if (myURL == "https://jubao.163.com/") return;
if (href.toLowerCase().indexOf('https://') >= 0 || href.toLowerCase().indexOf('https://') >= 0) myURL = href;
else if (href.startsWith('//')) myURL = 'https:' + href;
else myURL = seedURL.substr(0, seedURL.lastIndexOf('/') + 1) + href;
} catch (e) {
console.log('识别种子页面中的新闻链接出错:' + e)}
// 用正则表达式对链接进行筛选, 符合条件的, 即新闻页面, 则进行处理.
if (!url_reg.test(myURL) || myURL == "https://jubao.163.com/") return;
newsGet(myURL);
})
});
});
function newsGet(myURL) {
// 读取新闻页面
// superagent.get方法会根据url得到网站的所有html代码, 存储在end时间的res参数中.
superagent.get(myURL).end((err, res) => {
// err中存储错误, res中为html代码
if (err) {
console.log("热点新闻抓取失败-${err}");
} else {
console.log("爬取新闻成功!");
if (myURL == "https://jubao.163.com/") return;
getHotNews(res, myURL);
}
})
}
// 提取html代码中所需信息存入fetch对象中并输出为json文件
function getHotNews(res, myURL) {
let $ = myCheerio.load(res.text, {
decodeEntities: true });
// fetch为单条新闻对象. 详细见fetches解释
let fetch = {
};
fetch.title = "";
fetch.content = "";
fetch.keywords = "";
fetch.publish_date = "";
fetch.author = "";
fetch.desc = "";
fetch.source_name = source_name;
fetch.source_encoding = myEncoding;
fetch.crawltime = new Date;
fetch.url = myURL;
fetch.title = $('title').eq(0).text();
if (fetch.title == "") fetch.title = source_name;
fetch.content = $(".post_body").eq(0).text().replace(/\s*/g,"");
fetch.keywords = $('meta[name=\"keywords\"]').eq(0).attr("content");
fetch.publish_date = $('.post_info').eq(0).text().replace(/\s*/g,"").substr(0, 10);
fetch.author = $('.post_author').eq(0).text().replace(/\s*/g,"");
fetch.desc = $('meta[name=\"description\"]').eq(0).attr("content");
let filename = source_name + "_" + (new Date()).toFormat("YYYY-MM-DD") +
"_" + myURL.slice(myURL.lastIndexOf('/') + 1, myURL.lastIndexOf('.')) +".json";
// 输出为json文件
fs.writeFileSync(filename, JSON.stringify(fetch));
};
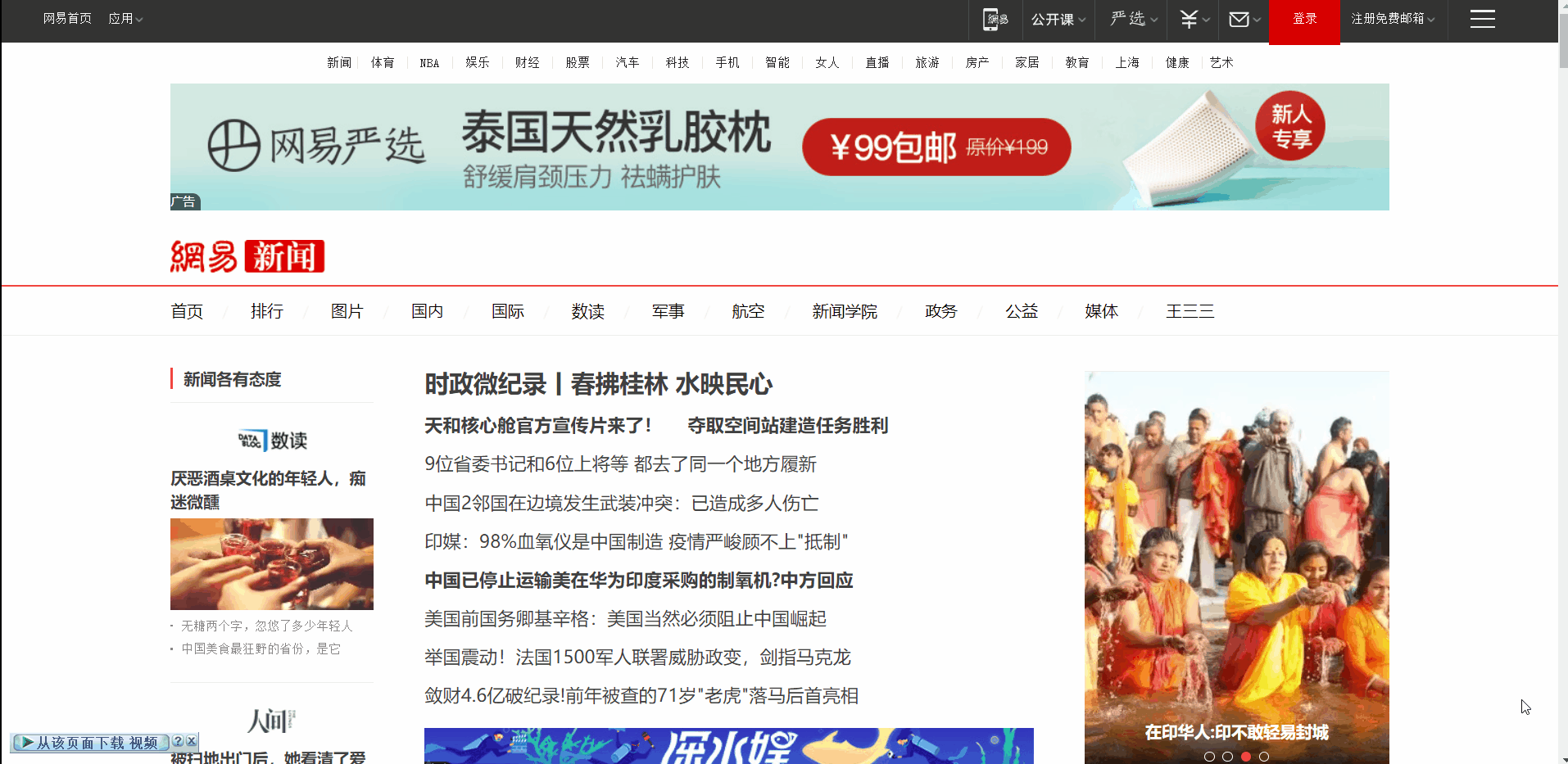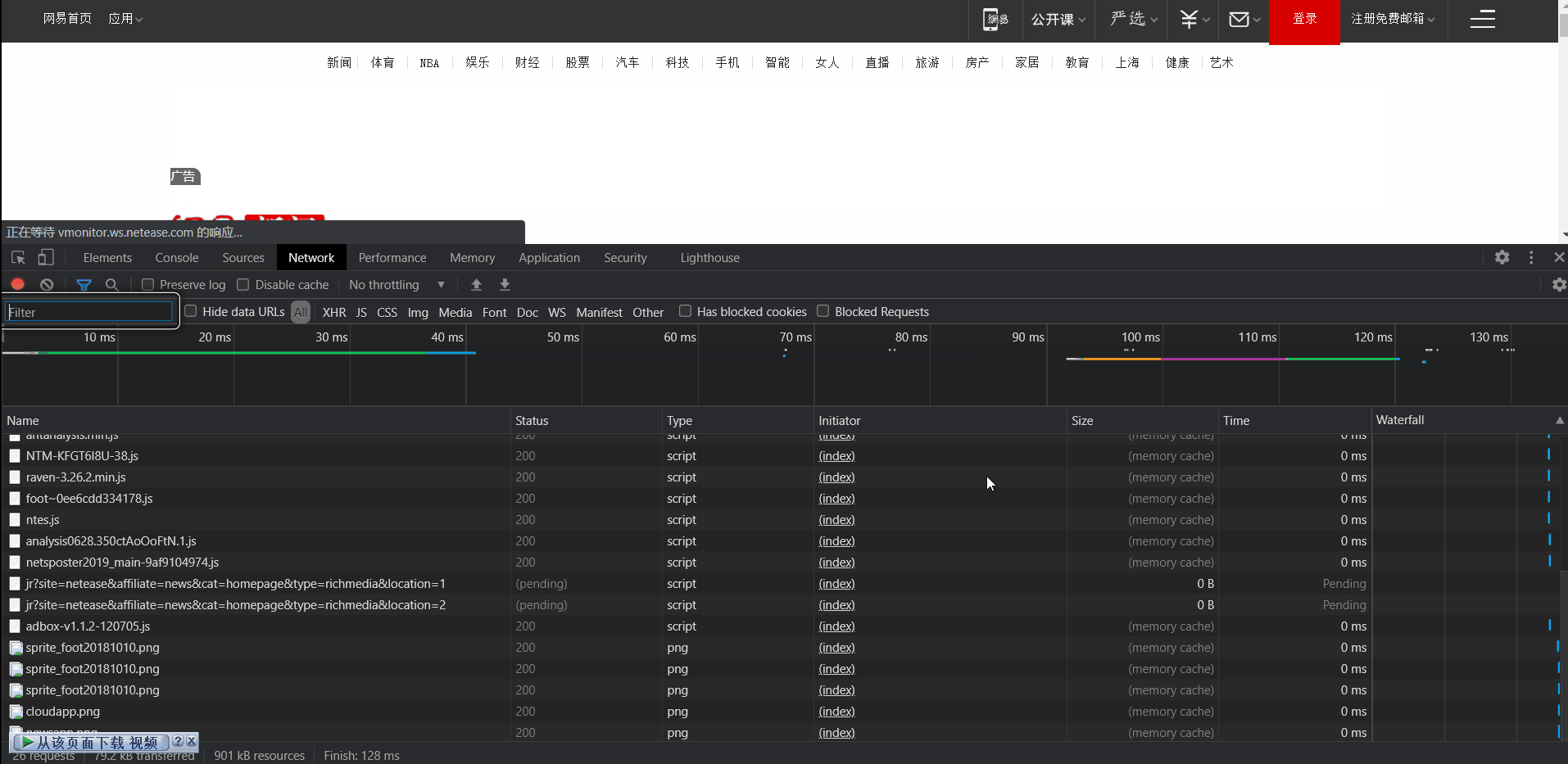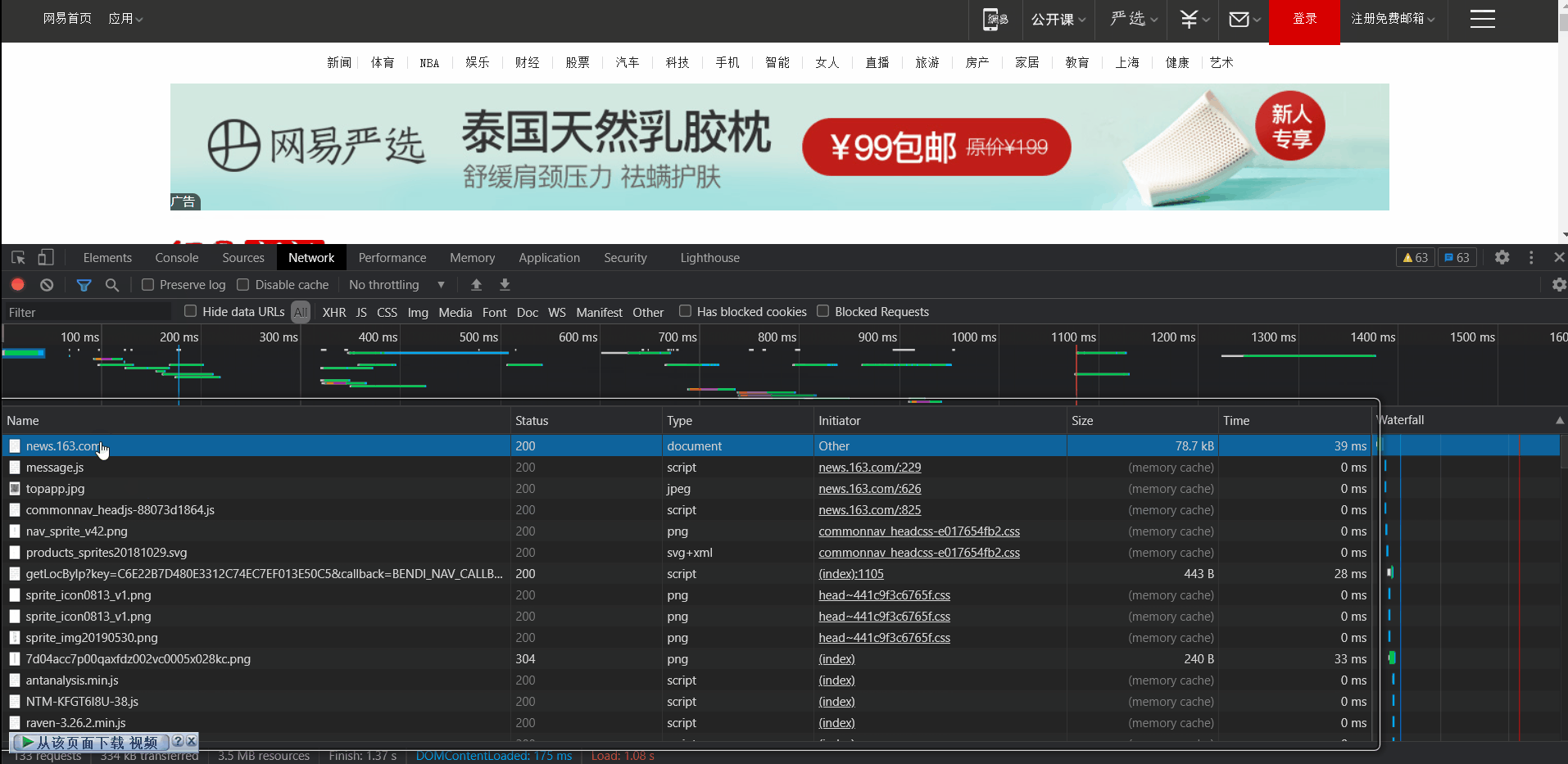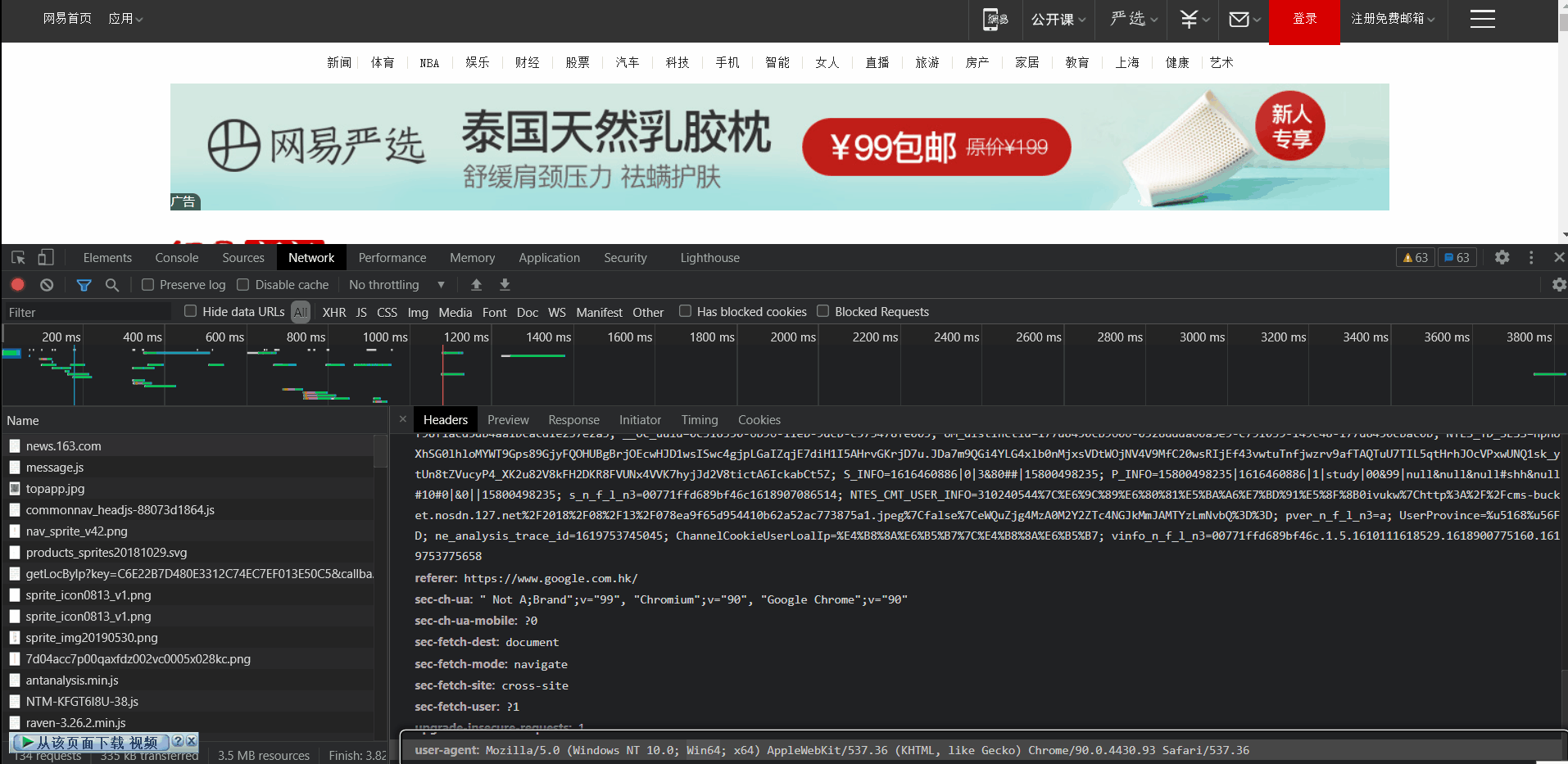
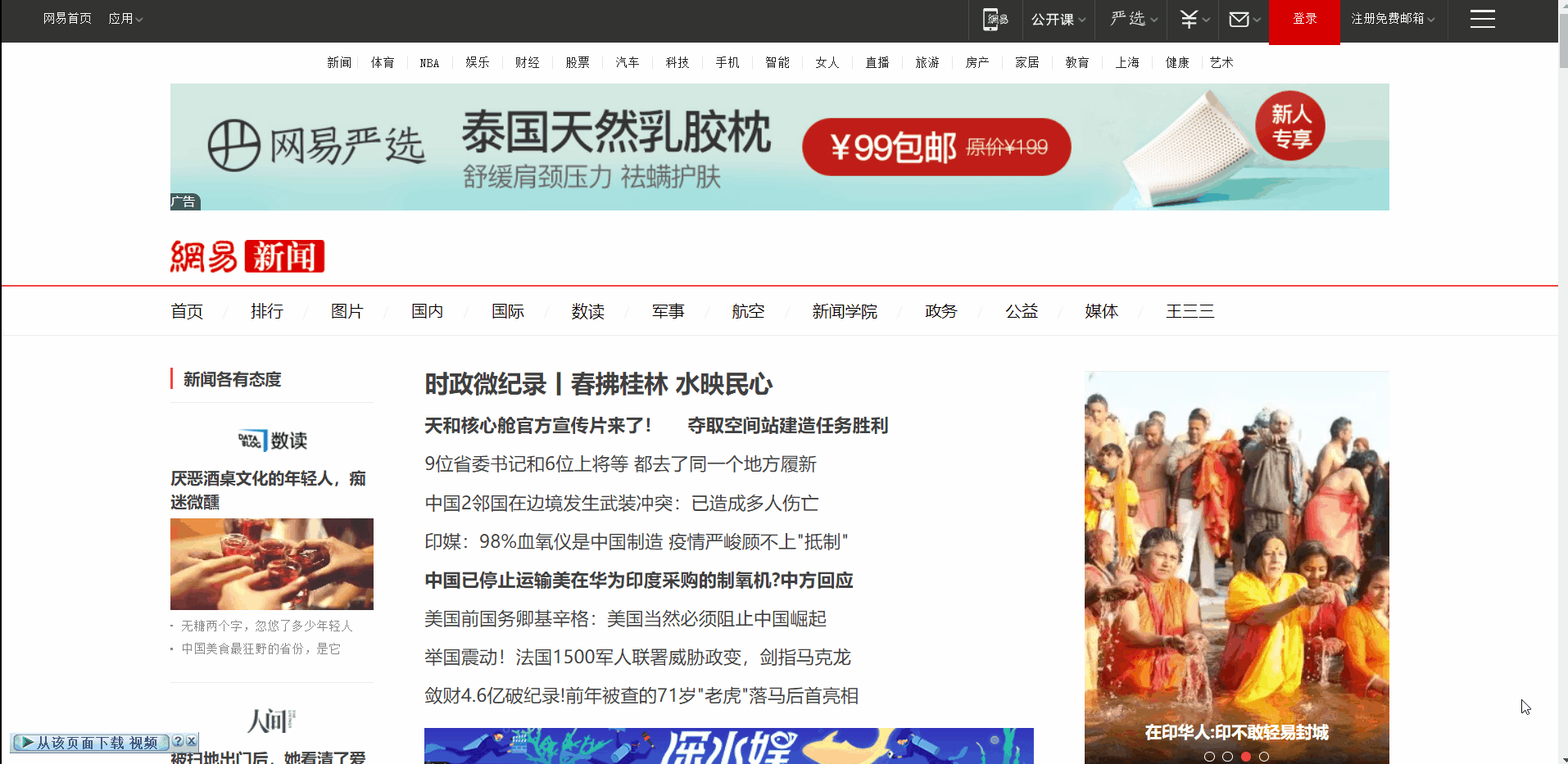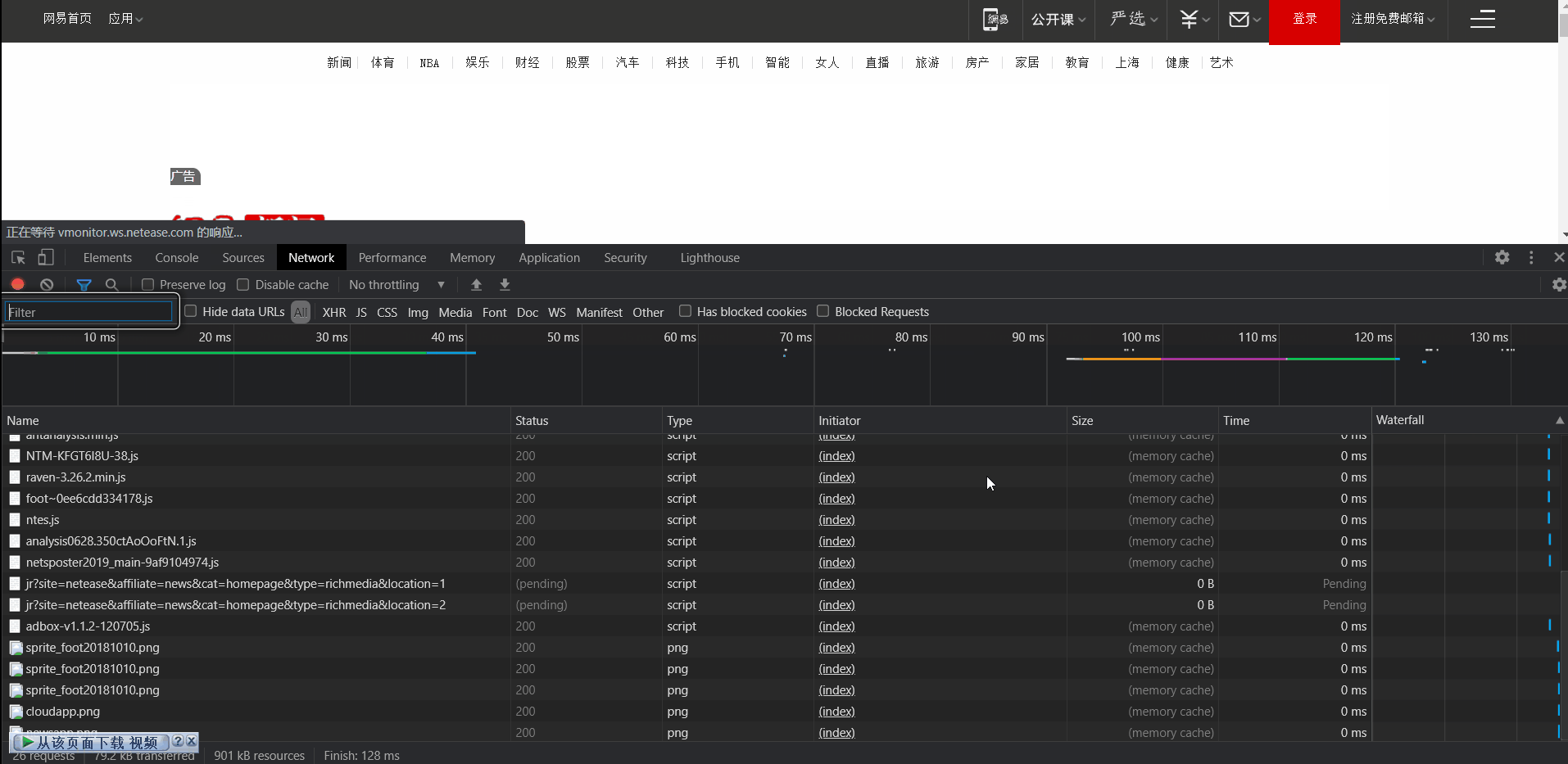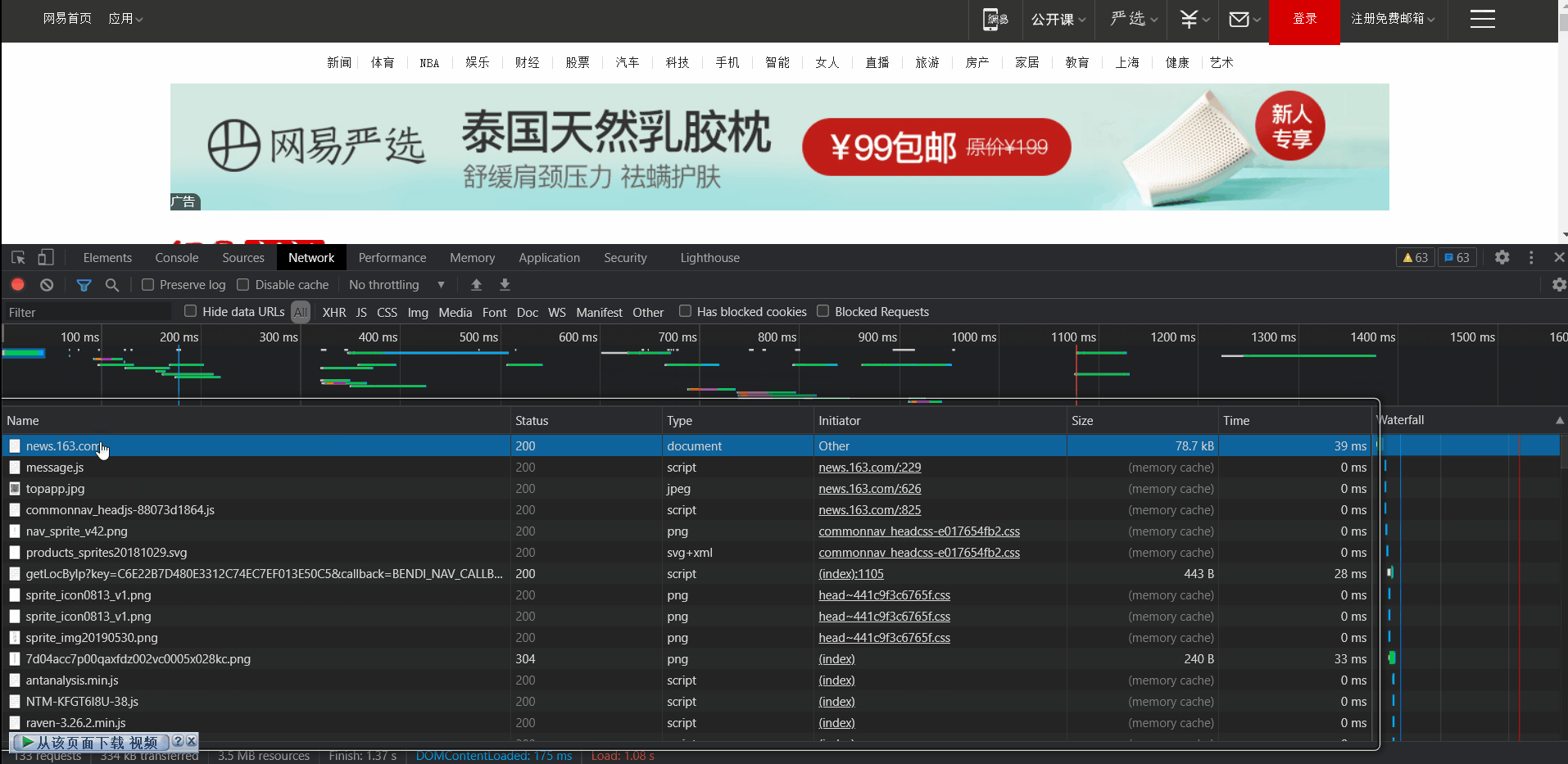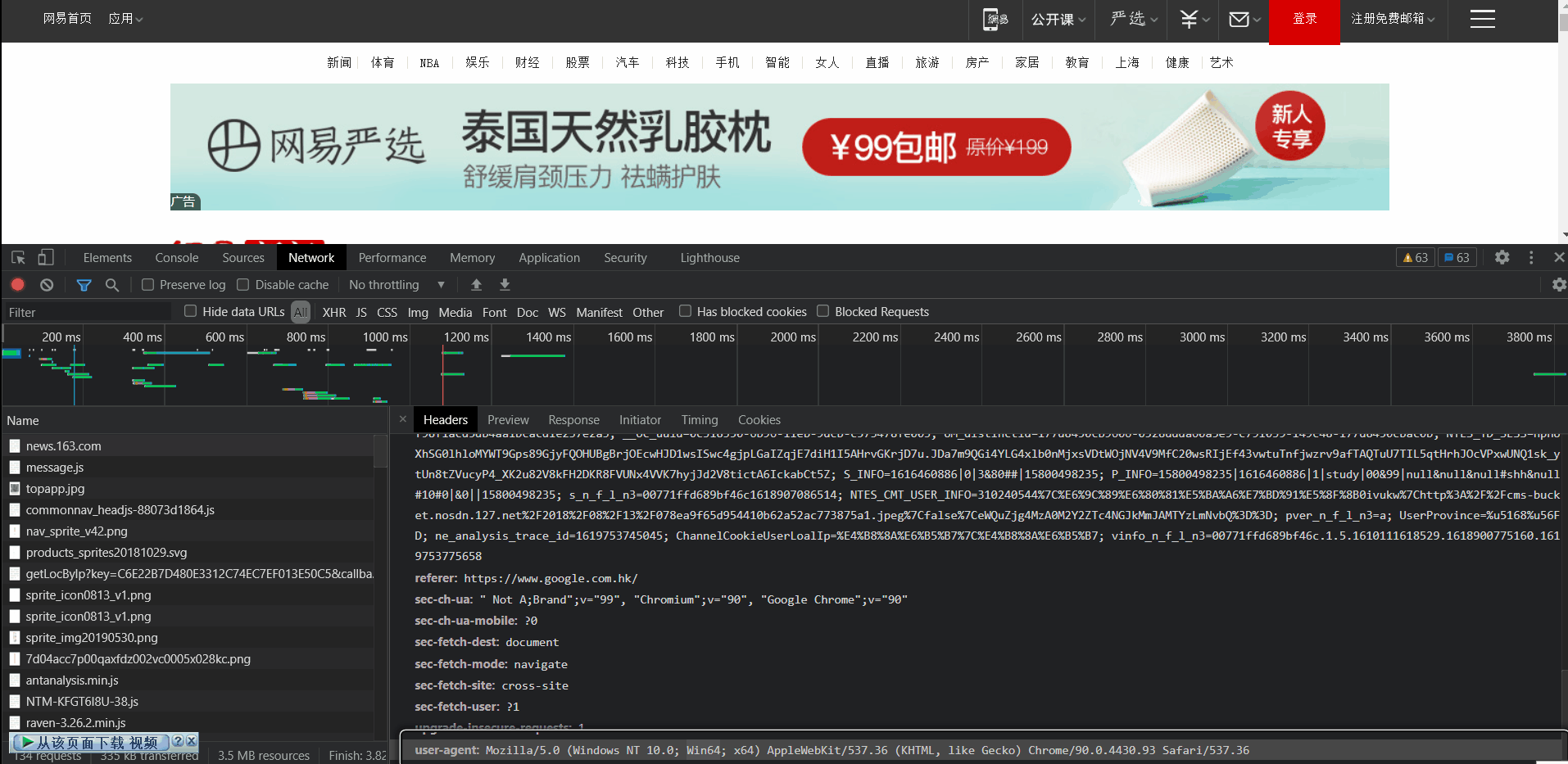
headers是一层伪装, 使我们的爬虫请求伪装成正常用户浏览的请求. 按下F12, 找到在Network页面Name为news.163.com的文件Header中的user-agent, 复制即可获取.
1.1 用正则表达式判断新闻页面
正则表达式的基础知识见: https://www.runoob.com/regexp/regexp-tutorial.html
我用代码提取出了网易新闻主页所有的链接, 发现凡是新闻页面,url中必定带article字样. 所有判断新闻页面的正则表达式为
// 正则表达式
let url_reg = /article/;
1.2 网易新闻页面结构分析
利用chrome浏览器F12快捷键, 再选取对象, 既可查看所选对象在html代码中的位置.
以网易新闻页面https://www.163.com/news/article/G8JHO2QG00019B3E.html?clickfrom=w_yw为例子
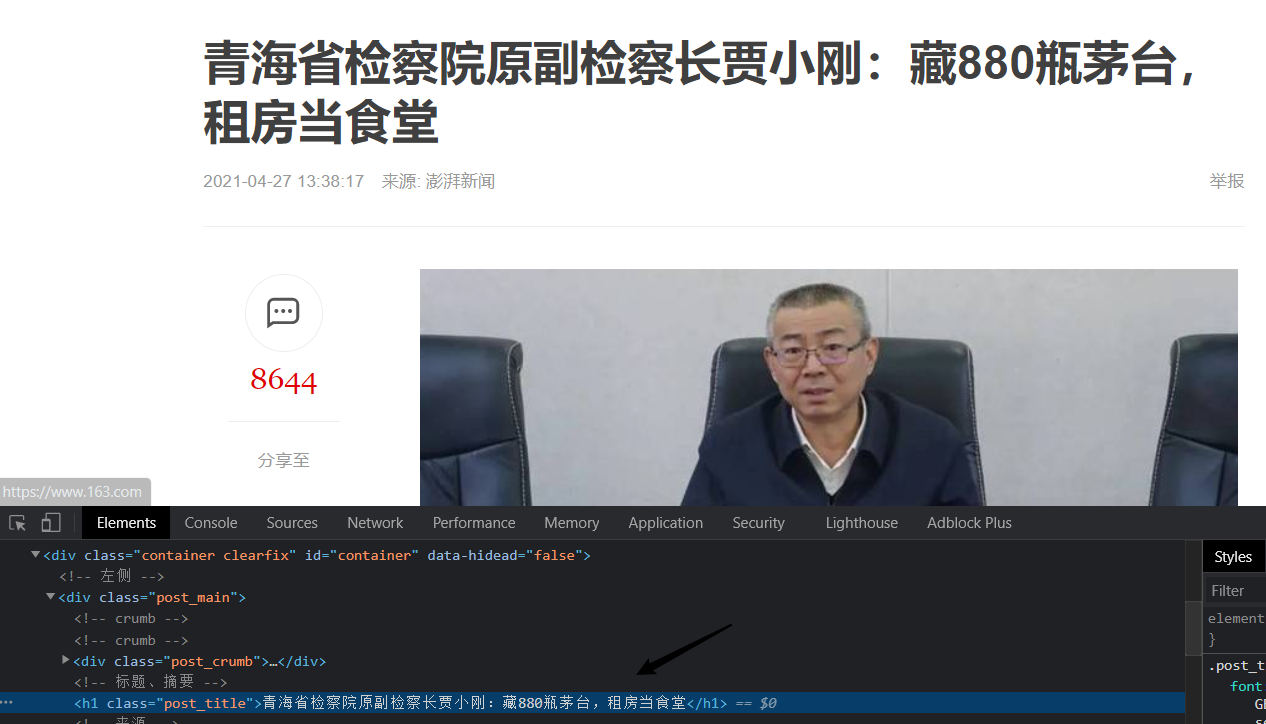
- 新闻
title为存储在post_title类中的文字, 用JQuery选择器即可选取.
fetch.title = $('.post_title').eq(0).text();
- 新闻内容为存储在
post_body类中的文字, 且提取出来的内容中包含了不必要的空格, 我们用replace函数和表达式去掉空格
fetch.content = $(".post_body").eq(0).text().replace(/\s*/g,"");
-
新闻关键词在
meta[name=keywords]的content参数中
fetch.keywords = $('meta[name=\"keywords\"]').eq(0).attr("content");
- 新闻发布日期为存储在
post_info类中文字, 包含空格, 前十位即日期.
fetch.publish_date = $('.post_info').eq(0).text().replace(/\s*/g,"").substr(0, 10);
- 新闻作者为存储在
post_author类中的文字, 包含空格, 用replace函数消除.
fetch.author  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 906
906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









