



CPU Threading and TorchScript Inference
本文翻译自CPU Threading and TorchScript Inference,仅作个人学习之用,不涉及任何商用用途,若涉及侵权请联系删除。
基本介绍
PyTorch允许在TorchScript模型推理过程中使用多个CPU线程来保证推理过程执行,以下图片展示了并行过程的不同层级关系:
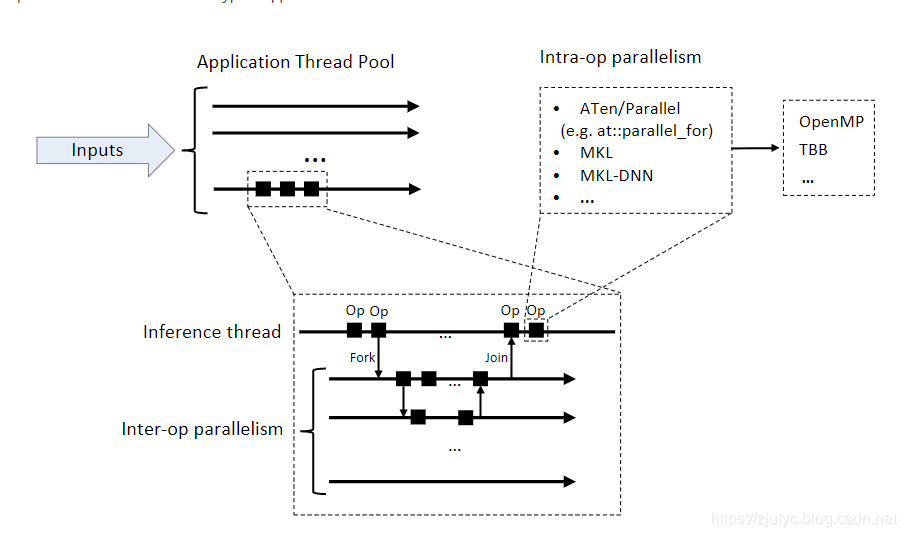
如上图所示,对于应用程序,首先其有一个线程池用来处理输入该应用程序的输入数据。对于神经网络中,该线程池中的线程可以是一个是包装了推理模型的线程。如图从线程池中引申出来的单个线程(推理线程),该线程会调用JIT解释器来一个接一个地执行该与推理模型线程中的操作。该模型线程可以调用fork(fork是分叉的意思,如上可以理解为从原线程中开一个分支单独去做某些操作)函数来运行一个异步任务。一次分叉多个操作会导致一个并行执行的任务的创建。fork操作会返回一个future对象,该future对象后面可以用来进行同步操作,示例如下:
@torch.jit.script
def compute_z(x):
return torch.mm(x,self.w_z)
@torch.jit.script
def forward(x):
fut=torch.jit._fork(compute_z,x) # 对compute_z函数启用异步计算过程
y=torch.mm(x,self.w_y) # 对compute_z进行并行执行下一个操作:矩阵乘法
z=torch.jit._wait(fut) # 等待compute_z的计算结果
return y+z
PyTorch使用单个线程池来进行程序操作序列间的并行化,线程池被程序进程中的多个推理任务(推理线程)共享,并分出分支以便进行并行化。
除了inter-op parallelism(操作间并行),PyTorch也可以使用多个线程进行操作内并行(intra-op parallelism)。比如:在大尺寸的tensors上逐元素进行操作、卷积操作、GEMMs、嵌入式查找等等。
构建选项
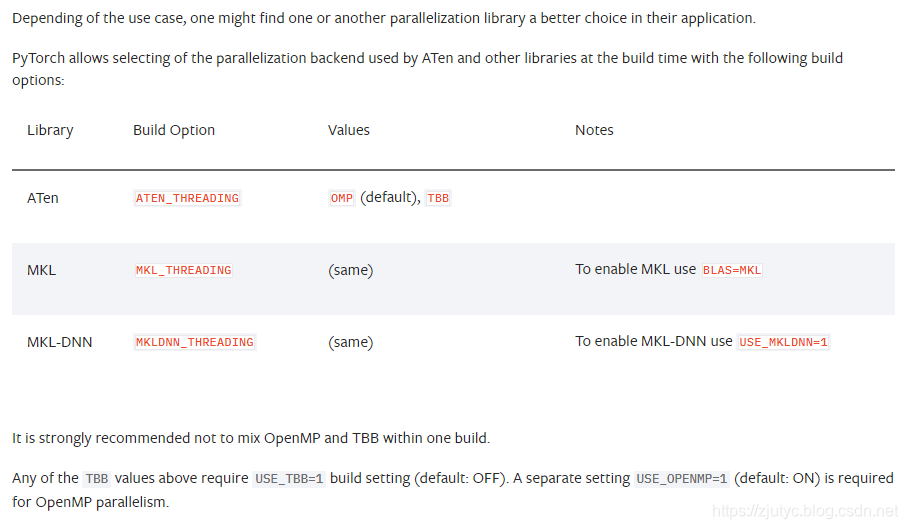
PyTorch使用内部的ATen库来实现相关操作,同时PyTorch也支持使用额外的库来构建应用程序,比如MKL或者MKL-DNN,通过这些库来加速CPU上的计算。
ATen、MKL、MKL-DNN支持操作序列内部的并行,并且依赖以下的并行库来实现操作序列内部并行化。
- OpenMP
- TBB:一个新的并行库,主要为了基于任务的并行和并发环境而优化的库
OpenMP历史上被许多库都进行过使用,相对来说对于基于循环的并行程序易于使用。与此同时,OpenMP在和其他进程库之间进行交互时却不是那么有名(可能是它支持的不太好:个人猜测)。特别是,OpenMP不保证在应用程序中每个进程都会使用intra-op线程池。相反,两个不同的inter-op线程会使用不同的OpenMP线程池来实现intra-op操作。这会导致应用程序使用了大量的线程。
在外部库中极少使用TBB库,但是该库会用在并发环境的优化情形下。PyTorch的TBB保证了应用程序中所有运行的操作都会使用一个分离的、单个的、每个进程拥有的intra-op线程池。
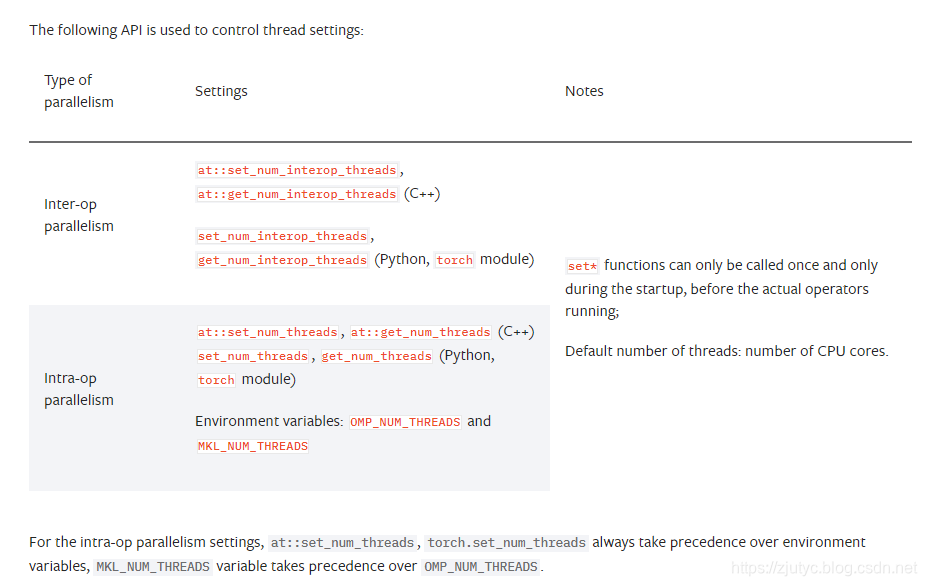
运行时API(Runtime API)
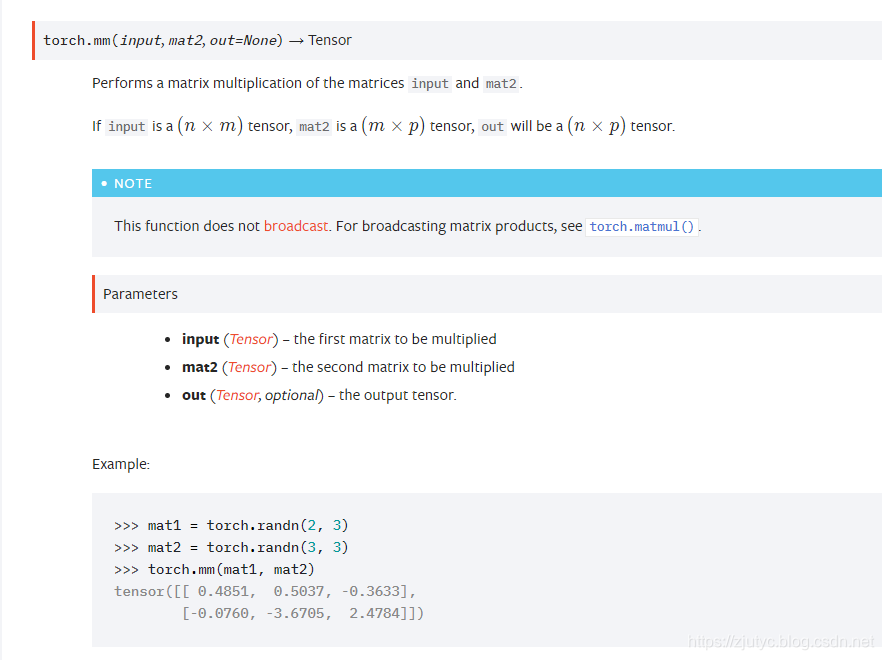
对于torch.mm的补充
这是一个求矩阵乘法的操作,具体情况见下图
总结:
- 以上文档翻译自cpu_threading_torchscript_inference,其中有些内容本人也不是很明白,待后续深刻理解后继续补充


















 367
367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









