



Triton全方位指南---从安装到上线(一)安装部署
简介:
NVIDIA开源的商用级别的后端算法服务框架
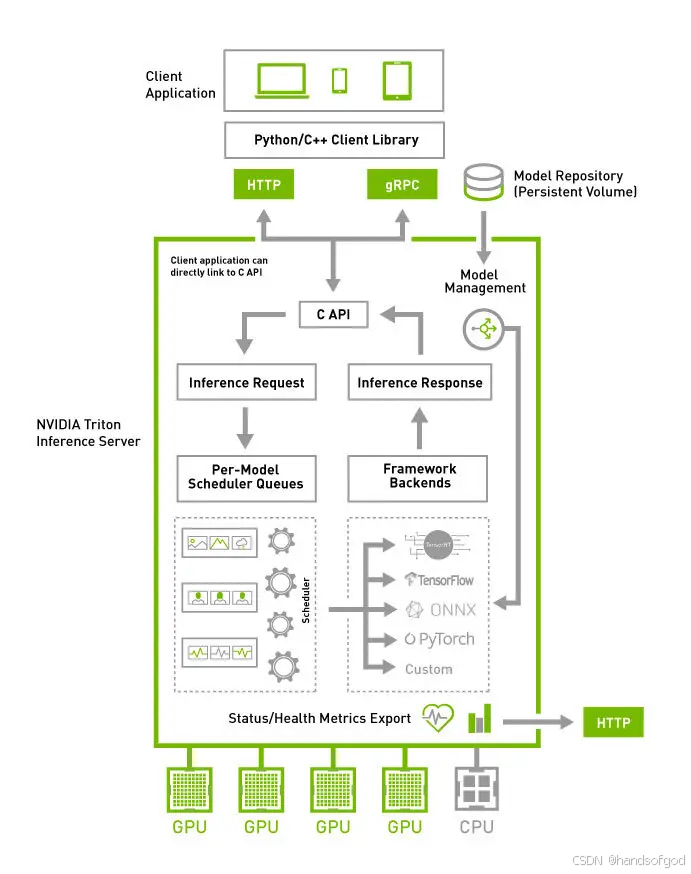
Triton Inference Server是一款开源的推理服务框架,它的核心库基于C++编写的,旨在在生产环境中提供快速且可扩展的AI推理能力,具有以下优势
- 支持多种深度学习框架:包括PyTorch,Tensorflow,TensorRT,ONNX,OpenVINO等产出的模型文件
- 至此多种机器学习框架:支持对树模型的部署,包括XGBoost,LightGBM等
- 支持多种协议:支持HTTP,GRPC协议
- 服务端支持模型前后处理:提供后端API,支持将数据的前处理和模型推理的后处理在服务端实现
- 支持模型并发推理:支持多个模型或者同一模型的多个实例在同一系统上并行执行
- 支持动态批处理(Dynamic batching):支持将一个或多个推理请求合并成一个批次,以最大化吞吐量
- 支持多模型的集成流水线:支持将多个模型进行连接组合,将其视作一个整体进行调度管理
- 支持模型热加载:可以通过API查看所有运行中模型的状态,还可以通过API不影响其他模型的情况下卸载和装载模型。
环境部署流程
1、检查版本对应,驱动要求
在安装一切环境之前,一定要先清楚所需的环境的版本要求,包括显卡和CUDA的对应,系统的版本,python的版本等等。triton各版本驱动要求信息和包含库信息
![[图片]](https://i-blog.csdnimg.cn/direct/170eb87d479b47498cc26d2190be5f04.png)
2、安装docker拉取镜像:
直接从官方拉取Triton省去了很多麻烦,轻松便捷,因此本文基于这种方式。如果之后需要自定义后端或者开发新的功能,可以深入了解下手动编译的方式。
下面是Ubuntu的安装示例,其他示例可见docker官方安装教程 。
更新apt-get
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
apt下载安装docker-ce 和插件
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
验证docker 是否安装
sudo docker run hello-world
2、安装NGC
NGC全称NVIDIA GPU Cloud,包含一系列用于深度学习、机器学习、可视化和高性能计算 (HPC) 应用的 GPU 优化容器,这些容器均已经过了性能、安全性和可扩展性测试。
需要根据NGC官方安装指导 安装NGC。下面是AMD64架构安装示例,其他示例请参照官方教程。
下载并解压ngccli
wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/ngc-apps/ngc_cli/versions/3.55.0/files/ngccli_linux.zip -O ngccli_linux.zip && unzip ngccli_linux.zip
检查md5和sha256 文件hash是否正确
find ngc-cli/ -type f -exec md5sum {} + | LC_ALL=C sort | md5sum -c ngc-cli.md5
sha256sum ngccli_linux.zip
输出应该和官方提供的hash一致,这里的例子为73a53f829b106f7886d555e7fd1200306370f3afcc77f349e11fea13460b748a。
配置环境变量
chmod u+x ngc-cli/ngc
echo "export PATH=\"\$PATH:$(pwd)/ngc-cli\"" >> ~/.bash_profile && source ~/.bash_profile
设置API key
输入
ngc config set
当出现Enter API Key字样的时候切换回NGC页面,点击右上角个人头像的下拉菜单(如果没有NGC账号可以注册一个),然后点击Set up按钮,应该看到如下的界面
![[图片]](https://i-blog.csdnimg.cn/direct/df323e59a8954e9087ff0b8fd574c7f8.png)
再点击Get API Key按钮来生成临时NGC API Key。
进入后点击右上角Genereate API Key按钮生成你的API Key,然后将最下方的API Key复制下来。
复制好后返回到Bash Shell粘贴API Key后回车。
之后NGC CLI会询问你将以哪种格式输出输出信息,NGC CLI提供了三种方式,个人喜欢json格式,以json格式进行输出,显示的信息也是最全的。
之后NGC CLI会提示输入组织、用户等信息,根据提示输入默认信息后回车即可。
配置好后,我们在Bash中输入如下指令
ngc user who
当看到statusCode为SUCCESS后,就证明我们的NGC配置成功了。
登录NGC
使用
docker login nvcr.io
命令登录,此时回车会提示你输入用户名和密码,这个还是之前生成API Key页面所生成的用户名和密码。
![[图片]](https://i-blog.csdnimg.cn/direct/19f30fe389f84d0c8b38c6dbbb7483eb.png)
这里用户名输入:$oauthtoken即可,密码则是刚才我们在NGC生成的API Key,点击回车,当docker cli显示Login Sucessed的字样后,我们便可以顺利访问NGC上的镜像列表了。
下载镜像
浏览器切回到NGC网页,点击左侧catlog下来菜单->containers按钮,进入到NGC镜像列表,在搜索框搜索Triton Inference Server,点击进入,再点击Tags标签选择对应版本的镜像下载。
![[图片]](https://i-blog.csdnimg.cn/direct/87f649d8a63c482c94f212662e07c6db.png)
![[图片]](https://i-blog.csdnimg.cn/direct/89d6813977c54d0eab9ec22f6cb206c3.png)
例如这里演示的是r23.10版本。版本-py3。其他的是不同环境或版本的镜像,详情可见Overview。
docker pull nvcr.io/nvidia/tritonserver:23.10-py3
3、安装nvidia container toolkit
安装完镜像后还必须安装nvidia container toolkit,用于连接docker容器和显卡。不然运行容器指定显卡时会报错,识别不到显卡。nvidia container toolkit官方安装指南
配置仓库
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
更新apt-get和安装
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
4、运行镜像和后端服务
运行容器
示例
docker run -ti --gpus=1 --net=host -v ${PWD}/model_repository:/models nvcr.io/nvidia/tritonserver:23.10-py3
运行容器的时候需要指定好gpu,--gpus=1表示使用1号显卡,如果使用所有显卡使用all。net网络模式我这里指定为host模式,容器共享宿主机的网络命名空间。-v ${PWD}/model_repository:/models表示映射宿主机的一个文件夹${PWD}/model_repository到容器内,在容器内的路径为/models。这样的话只需要在宿主机内上传新的模型,容器内同时就可以访问到。
配置环境
接下来需要为你的模型或者python backend安装所需的包。如果python backend中需要opencv、torchvision、torch等库,直接使用pip install ***进行安装。如果需要conda,或者不同版本的python可参考官方文档。
很棒,如果你能成功到这里说明你已经把前期工作准备充分了,接下来才是重头戏。
参考文献
入门教程
【高可用AI推理服务】使用WSL2部署Triton Inference Server推理服务器
AI模型部署:Triton Inference Server模型部署框架简介和快速实践
Triton模型部署流程(stey by stey)
Triton 概念指南(Part 1):如何部署模型推理服务


















 1121
1121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









