



程序执行到一半报错“malloc(): mismatching next->prev_size (unsorted)”死掉
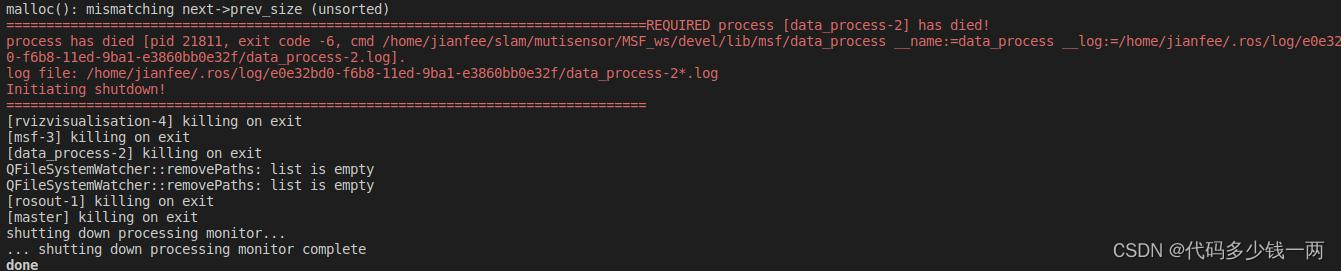
报错的原因是:当前栈空间不足
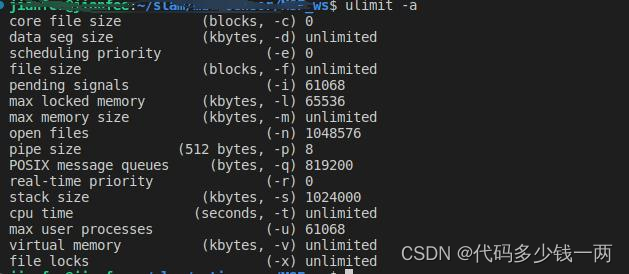
先检查当前栈空间大小
ulimit -a
如图:
增加空间:
ulimit -s 1024000
至此问题解决。
 当程序执行过程中出现malloc():mismatchingnext->prev_size(unsorted)错误时,这通常表示栈空间不足。为了解决这个问题,可以使用ulimit-a检查当前栈空间大小,然后通过ulimit-s1024000增大栈空间到1024000字节,从而避免程序因栈空间不足而崩溃。
当程序执行过程中出现malloc():mismatchingnext->prev_size(unsorted)错误时,这通常表示栈空间不足。为了解决这个问题,可以使用ulimit-a检查当前栈空间大小,然后通过ulimit-s1024000增大栈空间到1024000字节,从而避免程序因栈空间不足而崩溃。
程序执行到一半报错“malloc(): mismatching next->prev_size (unsorted)”死掉
报错的原因是:当前栈空间不足
先检查当前栈空间大小
ulimit -a
如图:
增加空间:
ulimit -s 1024000
至此问题解决。
 1219
6984
1219
6984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























