







1、final
final修饰类,不能被子类继承 String,Math;
final修饰的方法不能被重写;
final修饰的变量(成员和局部)表示常量,不能被二次赋值
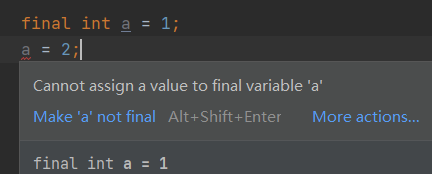
final修饰的成员变量,无论加不加static,都需要设置默认值
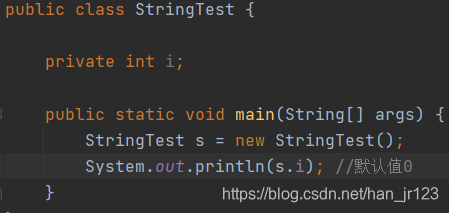

2、成员变量可以不加默认值,局部变量必须加默认值
3、成员变量、类变量、局部变量的区别
| 定义的位置 | 默认值 | 作用区域 | 重名 | 生命周期 | 在内存中的位置 | |
|---|---|---|---|---|---|---|
| 成员变量 | 在类体以内,方法体以外 | 有 | 每个对象独占 | 成员变量和类变量不可重名 | 随对象创建,随对象销毁 | 堆内存中 |
| 类变量 | 在类体以内,方法体以外,以static修饰 | 有 | 所有对象共享 | 成员变量和类变量不可重名 | 类加载时产生,类被jvm回收时销毁 | 方法区(静态区) |
| 局部变量 | 在方法体以内 | 没有 | 在方法内有效 | 优先局部变量 | 方法执行时产生,方法执行结束销毁 | 栈内存中 |
4、arraylist源码解析
ArrayList源码分析_JustinNeil的博客-优快云博客
动态数组,可以插入null;使用无参构造方法创建的是空数组;第一次add时数组容量扩容,变成10,后面每次新增时将新增1位后的长度和当前数组容量比较,大于就做扩容,增加原先的1/2的长度。
toArray()方法:底层Arrays.copyOf(elementData, size)
vector线程安全,方法加了synchronized修饰,性能比arraylist差,每次扩容增加一倍
在需要扩容的节点处,耗时会突增
5、自动装箱拆箱
装箱:把基本数据类型用对应的引用数据类型包装起来 valueOf()方法
拆箱:将包装类型转换为基本数据类型 initValue()方法 Long用的longvalue()方法 Short,Integer,Byte,Long的intvalue()方法返回的都是int
==:基本数据类型比较的是值,引用类型比较的是对象的内存地址
如果整型(Byte,Short,Integer,Long)和char字面量的值在-128~127之间,那么自动装箱时不会new新的integer对象,而是直接引用常量池中的inetegr对象。
8种基本数据类型都有自己的包装类,其中有6个包装类(Byte,Short,Integer,Long,Character,Boolean)实现了常量池技术
double和float两种是所有值都创建新对象,没有实现常量池技术。
当一个基本数据类型与分装类进行==+-*/时,会先进行拆箱。
equals()和==:Object中的equals方法中是使用==来实现的,即比较两者地址值,但object的子类可以重写equals方法,比如Date、String、Integer等类都是重写了equals()方法,比较的是值是否相等。
char a = 65:输出A,可以用ascii码表示char和character。 ASCII码表:ASCII码中文站 www.asciima.com
Integer a = 12;
Integer b = new Integer(12);
Integer c = 12;
Integer d = 128;
Integer e = 128;
System.out.println(a==b);//false
System.out.println(a==c);//true
System.out.println(d==e);//false Character a = 'A';
Character b = new Character('A');
Character c = 'A';
Character d = 128;
Character e = 128;
System.out.println(a==b);//false
System.out.println(a==c);//true
System.out.println(d==e);//false Boolean a = true;
Boolean b = new Boolean(true);
Boolean c = true;
System.out.println(a==b);//false
System.out.println(a==c);//true6、string、stringbuilder、stringbuffer
直接使用双引号申明出来的string对象会直接存储在常量池中。
通过new创建string对象时,jvm会先去字符串常量池中查找有没有"abc"对象,不存在就首先在常量池创建,然后在堆中创建,再将堆中创建的对象地址返回。
常量池的好处:避免频繁的创建和销毁对象而影响系统性能,其实现了对象的共享
字符串比较,用==比equal效率高
string a = "he"+"llo",编译期间,这种拼接会被优化,编译器直接帮你拼接好,所以=="hello"
对于final字段,编译期间就会进行常量替换,而非final字段在运行期进行赋值处理
native string intern()方法:如果常量池中已经包含了等于此string对象的字符串(equals()方法确定),则返回池中的字符串。否则将此string对象添加到池中,并返回此string对象的引用。
String a = new String("abc");
String b = new String("abc");
String c = "abc";
String d = "abc";
String e = "ab" + "c";
System.out.println(a == b);//false
System.out.println(a == c);//false
System.out.println(d == c);//true
System.out.println(e == c);//true
System.out.println(a.intern() == c);//true
String f = "a";
String g = "bc";
String h = "abc";
String i = f + g;
final String j = "a";
final String k = "bc";
String l = j + k;
System.out.println(h == i);//false
System.out.println(h == l);//true只有使用引号包含文本的方式创建的string对象之间使用+连接产生的新对象才会被加入字符串池。
String a = "hello";
String b = "world";
String c = a + b + "!";
System.out.println(c == "helloworld!");//false解析:这里有编译器的优化处理:自动引入了stringBuilder类,appen()方法,toString()方法生成结果,从而避免中间对象的性能损耗。
String s = A+B;
String t = "ab";
System.out.println(s==t);//true解析:A和B都是常量,值是固定的,类编译期键就确定值了,因此s的值也是固定的
参考博文:字符串常量池、class常量池和运行时常量池_lzf的博客-优快云博客_常量池和运行时常量池
7、java数据类型
基本数据类型:数值型(整数类型(byte,short,int,long),浮点类型(float,double)),字符型(char),布尔型(boolean)
引用数据类型:类(class),接口(interface),数组([])

8、finalize是object的方法,一般有垃圾回收器调用
9、访问修饰符
private : 在同一类内可见。使用对象:变量、方法。 注意:不能修饰类(外部类)
default (即缺省,什么也不写,不使用任何关键字): 在同一包内可见,不使用任何修饰符。使用对象:类、接口、变量、方法。
protected : 对同一包内的类和所有子类可见。使用对象:变量、方法。 注意:不能修饰类(外部类)。
public : 对所有类可见。使用对象:类、接口、变量、方法
10、static
static的主要意义是在于创建独立于具体对象的域变量或者方法。以致于即使没有创建对象,也能使用属性和调用方法!
static关键字还有一个比较关键的作用就是 用来形成静态代码块以优化程序性能。static块可以置于类中的任何地方,类中可以有多个static块。在类初次被加载的时候,会按照static块的顺序来执行每个static块,并且只会执行一次。
为什么说static块可以用来优化程序性能,是因为它的特性:只会在类加载的时候执行一次。因此,很多时候会将一些只需要进行一次的初始化操作都放在static代码块中进行。
注意:静态只能访问静态,非静态可访问非静态,也可访问静态
11、通过反射可以修改所谓的不可变对象
String a = "abc";
Field field = String.class.getDeclaredField("value");
field.setAccessible(true);
char[] value = (char[])field.get(a);
value[2] = 'd';
System.out.println(a);//abd12、在使用hashmap时,用string作key有什么好处
HashMap 内部实现是通过 key 的 hashcode 来确定 value 的存储位置,因为字符串是不可变的,所以当创建字符串时,它的 hashcode 被缓存下来,不需要再次计算,所以相比于其他对象更快。
String类中使用字符数组保存字符串,private final char value[],所以string对象是不可变的
stringbuffer线程安全:public synchronized StringBuffer append
13、java单继承和多实现
java不支持多继承:会产生调用的不确定性 super.xxx()是调的哪个父类的?
14、枚举
枚举是java5新增特性的一部分,它是一种特殊的数据类型,既是类,却多了特殊的约束,也造就了枚举类型的简洁性、安全性以及便捷性。
15、switch
在jdk1.5之前,switch只能用byte,short,int,char。jdk5引入枚举后,也可以使用enum。jdk7也可以使用字符串string
15、最有效率的方法计算2乘以8
2<<3 (左移3位相当于乘以2的3次方,右移3位相当于除以2的3次方)
对于大数据的2进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而已,不去计算,这样提高了效率,节省了资源
16、常用api
java.lang.math的方法min(a,b):返回两个值较小的;max(a,b):返回两个值较大的;round(1.6f):在参数上+0.5进行向下取整
java.lang.system的方法arraycopy(Object src,int srcpos,object dest,int destpos,int length):从指定源数组复制一个数组,srcpos源数组中的起始位置,destpos目标数组的起始位置,src:源数组length:要复制的数组元素的数量
17、遍历 自己实现增强型for循环
1)、实现iterable接口,重写iterator方法
2)、提供内部类,实现iterator接口,重写hasnext和next方法
public class MyList<T> implements Iterable<T> {
public T[] eles;
public int n;
@Override
public Iterator<T> iterator() {
return new MyIterator();
}
private class MyIterator implements Iterator<T> {
private int cursor;
public MyIterator() {
cursor = 0;
}
@Override
public boolean hasNext() {
return cursor < n;
}
@Override
public T next() {
return eles[cursor++];
}
}
public static void main(String[] args) {
//1增强型for循环
MyList<String> list = new MyList<>();
String[] a = {"a", "b", "c"};
list.eles = a;
list.n = 3;
for (String s : list) {
System.out.println(s);
}
//2迭代器遍历
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String next = iterator.next();
System.out.println(next);
}
//3基于计数器的for循环遍历
}
}18、java集合的快速失败机制fail-fast
是java集合的一种错误检测机制,当多个线程对集合进行结构上的改变的操作时,有可能会产生 fail-fast 机制。
线程1通过Iterator在遍历集合A中的元素,在某个时候线程2修改了集合A的结构(是结构上面的修改,而不是简单的修改集合元素的内容),那么这个时候程序就会抛出 ConcurrentModificationException 异常,从而产生fail-fast机制。
原因:集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。
19、ArrayList 和 LinkedList 的区别是什么?
数据结构实现:ArrayList 是动态数组的数据结构实现,而 LinkedList 是双向链表的数据结构实现。
随机访问效率:ArrayList 比 LinkedList 在随机访问的时候效率要高,因为 LinkedList 是线性的数据存储方式,所以需要移动指针从前往后依次查找。
增加和删除效率:在非首尾的增加和删除操作,LinkedList 要比 ArrayList 效率要高,因为 ArrayList 增删操作要影响数组内的其他数据的下标。
内存空间占用:LinkedList 比 ArrayList 更占内存,因为 LinkedList 的节点除了存储数据,还存储了两个引用,一个指向前一个元素,一个指向后一个元素。
线程安全:ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
综合来说,在需要频繁读取集合中的元素时,更推荐使用 ArrayList,而在插入和删除操作较多时,更推荐使用 LinkedList。
补充:数据结构基础之双向链表
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。
20、为什么 ArrayList 的 elementData 加上 transient 修饰
ArrayList 实现了 Serializable 接口,这意味着 ArrayList 支持序列化。transient 的作用是说不希望 elementData 数组被序列化,重写了 writeObject 实现
21、java向上转型、向下转型
父子对象之间的转换分为:
向上转型:通过子类对象实例化父类对象,属于自动转型;向上转型时,父类只能调用父类方法或子类覆盖后的方法,二子类单独的方法无法调用。意义:当我们需要多个同父的对象调用某个方法时,通过向上转换后,则可以确定参数的统一.方便程序设计。
class A {
public void print() {
System.out.println("A:print");
}
}
class B extends A {
public void print() {
System.out.println("B:print");
}
}
class C extends B {
public void print() {
System.out.println("C:print");
}
}
public class Test{
public static void func(A a)
{
a.print();
}
public static void main(String args[])
{
func(new B()); //等价于 A a =new B();
func(new C()); //等价于 C c =new C();
}
}向下转型:通过父类对象实例化子类对象,属于强制转型;向下转型则是为了,通过父类强制转换为子类,从而来调用子类独有的方法
if(a instanceof B)
{
B b = (B)a; //向下转型,通过父类实例化子类
b.funcB(); //调用B类独有的方法
}
else if(a instanceof C)
{
C c = (C)a; //向下转型,通过父类实例化子类
c.funcC(); //调用C类独有的方法
}22、float a = 3.4是否正确?
不正确。浮点数的默认类型是double类型,3.4 是双精度数,将双精度型(double)赋值给浮点型(float)属于下转型(down-casting,也称为窄化)会造成精度损失,因此需要强制类型转换float f =(float)3.4; 或者写成 float f =3.4F。
整形变量默认为int类型
23、基本数据类型之间的运算规则
23.1、隐式类型转换:从小类型到大类型,不需要强制类型转换:byte b = 1;double d = b;
long l1 = 1;//1默认int,但是超过int范围会报错:long l1 = 111111111111111111;解决方法,加上后缀l或者L:long l1 = 111111111111111111L;
大类型赋值给小类型就会报错:double a = Math.random() + 1;int e = a;
23.2、强制类型转换:从大类型到小类型,需要强制类型转换符:double a = Math.random() + 1;int e = (int) a;
23.3、当byte、char、short三种类型的变量不参与运算时,整数可以直接赋值给它们,前提是不超过最大值范围。
特别的: 当byte、char、short三种类型的变量做运算时,结果为int型。所以:byte b = 1; byte b2 = 2; byte b3 = (byte) (b + b2);
int i1 = 1;byte b1 = 1;b1 = i1;
结论:当容量小的数据类型的变量与容量大的数据类型的变量做运算时,结果自动提升为容量大的数据类型
例:short s = 1;s = s + 1;编译报错。因为1 是 int 类型,因此 s1+1 运算结果也是 int型,需要强制转换类型才能赋值给 short 型。
而 short s1 = 1; s1 += 1;可以正确编译,因为 s1+= 1;相当于 s1 = (short(s1 + 1);其中有隐含的强制类型转换。
24、java都是值传递
所有的参数传递都是值传递
public static void main(String[] var0) {
Integer var1 = Integer.valueOf(10);
Integer var2 = Integer.valueOf(20);
System.out.println(var1 + " " + var2);
change(var1, var2);
System.out.println(var1 + " " + var2);
}
public static void change(Integer var0, Integer var1) {
var0 = Integer.valueOf(100);
var1 = Integer.valueOf(200);
}如果参数类型是原始类型,那么传过来的就是这个参数的一个副本,也就是这个原始参数的值,这个跟之前所谈的传值是一样的。如果在函数中改变了副本的 值不会改变原始的值.
如果参数类型是引用类型,那么传过来的就是这个引用参数的副本,这个副本存放的是参数的地址。如果在函数中没有改变这个副本的地址,而是改变了地址中的 值,那么在函数内的改变会影响到传入的参数。
如果在函数中改变了副本的地址,如new一个,那么副本就指向了一个新的地址,此时传入的参数还是指向原来的 地址,所以不会改变参数的值。
25、匿名内部类
就是没有名字的内部类,
必须继承一个抽象类或实现一个接口,
不能定义静态成员和静态方法,
当所在方法法的形参需要被匿名内部类使用时,需定义为final,
不能是抽象的,必须实现 继承的抽象类或实现的接口的所有方法。
26、内部类
创建静态内部类对象的一般形式为: 外部类类名.内部类类名 xxx = new 外部类类名.内部类类名()
创建成员内部类对象的一般形式为: 外部类类名.内部类类名 xxx = 外部类对象名.new 内部类类名()
27、接口的成员变量,必须是public static final。如果没写,则默认是。
28、String对象的不可变性
String类被final关键字修饰,代表类不可继承;变量char数组被final修饰,代表string对象不可被更改(被final修饰的变量不可二次赋值)。所以string对象一旦创建,就不能再对他进行改变
好处:
第一 保证string对象的安全性。 同一个string对象可以被多个线程共享 线程安全
第二 保证hash属性值不会频繁变更,确保唯一性,(因为字符串是不变的,hashcode被缓存?,不需要重新计算,使得string很适合做map中的key。往往hashmap中的键都使用字符串)
第三
29、在做字符串连续拼接的时候,需要显示使用stringbuider,已提高字符串的拼接性能
使用+号做字符串的拼接,被编译器优化成stringbuilder的方式。但是每次拼接都会生成一个新的stringbuilder实例,同样也会降低系统的性能!
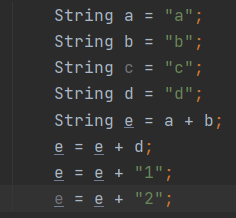
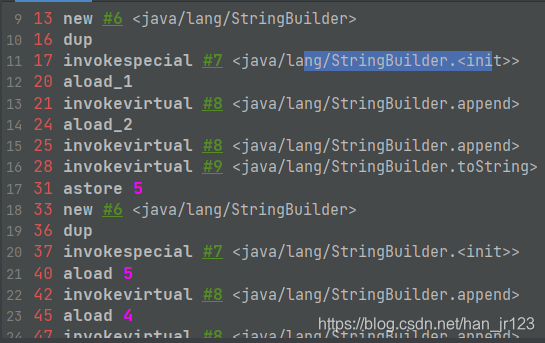
30、transient 关键字
只可以修饰成员变量,序列化的时候会忽略此变量,但是反序列化时,不能取得此成员变量的值
31、自定义序列化
继承Serializable接口,并重写三个方法 (三个方法可选,不强制,一般实现前面2个)
private void readObject(java.io.ObjectInputStream s) //序列化时调用
private void writeObject(java.io.ObjectOutputStream s) //反序列化调用
32、arraylist序列化
elementData数组被transient关键字修饰了,表示该字段不会被序列化,但是实现了序列化接口?
如果采用外部序列化,会序列化整个数组。由于arraylist的数组是基于动态扩增的,所以并不是所有被分配的内存空间都存储了数据。为避免这些没有被存储数据的内存空间被序列化,提供私有方法来完成序列化,从而节省了空间和时间!
33、空数组

34、ArrayList初始化
如果没有设置初始容量,默认是10。初始化空数组,第一次add的时候做扩容,到10。
当新增元素时,如果所存储的元素已超过其已有大小,会计算元素大小后进行动态扩容。数组的扩容会导致整个数组进行一次内存复制。
因此,初始化时,可以通过构造函数合理指定数组初始大小,这样有助于减少数组的扩容次数,从而提高系统性能。
按照原来数组的1.5倍进行扩容。 int newCapacity = oldCapacity + (oldCapacity >> 1);
35、LinkedList get(i)方法
由代码可知,查找中间的元素,是循环遍历操作最多的。如果查找的元素在前半段,就从前往后找;如果位置处于后半段,就从后往前找。所以将元素添加到中间,效率最低。
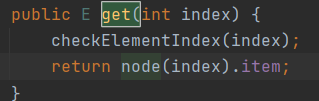
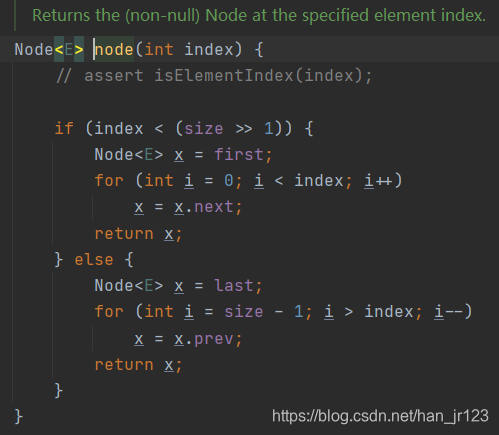
36、ArrayList和LinkedList遍历元素
for(;;;)循环:时间上ArrayList<LinkedList
2023/3/24
37、安装jdk后启动报错
The server selected protocol version TLS10 is not accepted by client preferences [TLS12]
在 jre\lib\security 文件夹下,编辑 java.security 文件,在文件中找到 jdk.tls.disabledAlgorithms 配置项,将 TLSv1, TLSv1.1 删除即可。
38、java的replaceAll使用了正则,对+铭感
java字符串使用replace、replaceall、split处理`’+‘、’|‘、 ’*‘、’.‘、’?‘、'$'等字符无效的解决办法(阐释原因和解决方案,实测有效) - 代码先锋网
39、Long比较 2024-09-19
new long(2)会生成新对象,所以 new long(2)!=new long(2) ---==比较的是内存地址
Long a = 1,会自动装箱,相当于Long.valueof(1),-128~127是使用创建好的对象,超过这个区间就会new一个新对象,==比较就是false
40、java调用https 2024-09-26
在Java项目中请求HTTPS时,可能会遇到 "unable to find valid certification path to requested target" 错误。这个错误通常是由于SSL证书问题引起的。要解决此问题,可以尝试以下方法:
static {
SSLContext sslContext = null;
try {
sslContext = SSLContext.getInstance("TLS");
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
TrustManager[] trustManagers = new TrustManager[]{new X509TrustManager() {
@Override
public void checkClientTrusted(java.security.cert.X509Certificate[] x509Certificates, String s) {}
@Override
public void checkServerTrusted(java.security.cert.X509Certificate[] x509Certificates, String s) {}
@Override
public java.security.cert.X509Certificate[] getAcceptedIssuers() {
return null;
}
}};
try {
sslContext.init(null, trustManagers, new java.security.SecureRandom());
} catch (KeyManagementException e) {
e.printStackTrace();
}
HttpsURLConnection.setDefaultSSLSocketFactory(sslContext.getSocketFactory());
}https请求报错unable to find valid certification path to requested target解决-优快云博客
41、正则表达式 (可以将符合表达式的字符串替换掉)
* 匹配前面的子表达式任意次数 ,相当于{0,}
+ 匹配前面的子表达式1或多次 ,相当于{1,}
? 匹配前面的子表达式1或0 ,相当于{0,1}
{n} n非负整数,匹配n次
{n,} n非负整数,至少匹配n次
{n,m} n<=m,至少n,最多m
\d 匹配数字 ,等价于[0-9] \D 匹配非数字,等价于[^0-9]
版本号:1.0.0.1 REG=“^((0|[1-9]\\d*)\\.){3}(0|[1-9]\\d*)$”
java.util.regex是Java中用于处理正则表达式的类库_java.util.regex.pattern-优快云博客
public class Client {
public static void main(String[] args) {
//要处理的字符串
String datas = "111aaa222bbb333ccc";
System.out.println("待处理字符串:"+datas);
//表达式对象:1个数字和1个字母连续
Pattern pattern = Pattern.compile("\\d[a-z]");
//匹配器,指定要解析的字符串datas
Matcher matcher = pattern.matcher(datas);
//判断整个字符串是否符合表达式对象
System.out.println("整个字符串是否符合:"+matcher.matches());
//在字符串中寻找下一个符合要求的对象,有则返回true
while (matcher.find()){
//取出匹配到的字符串
System.out.println("符合的:"+matcher.group());//group(1)表示正则中的()()第二个捕获组的内容,以此类推。
}
//符合表达式的使用指定字符串替换替换
String end = matcher.replaceAll("A");
System.out.println("替换后:"+end);
//分割字符串,使用正则表达式
String me = "love0dlove0alove";
String[] mes = me.split("0[a-z]");
for (String s:mes){
System.out.print(s);
}
}
}Java中使用正则表达式 - 在博客做笔记的路人甲 - 博客园
42、String.format('','') 十进制转换成十六进制
String.format("%02x", 19),将10进制的19转换成16进制,不足的补0,2位。
// %s 字符串类型
str = String.format("Hi,%s", "Jack");
43、word/doc/docx转pdf
引入依赖
<!--word 2 pdf start-->
<dependency>
<groupId>com.documents4j</groupId>
<artifactId>documents4j-local</artifactId>
<version>1.0.3</version>
</dependency>
<dependency>
<groupId>com.documents4j</groupId>
<artifactId>documents4j-transformer-msoffice-word</artifactId>
<version>1.0.3</version>
</dependency>import java.io.*;
import com.documents4j.api.DocumentType;
import com.documents4j.api.IConverter;
import com.documents4j.job.LocalConverter;
public class wordToPdf {
/**
* Word转PDF
* @param filePath 源docx文件目录及名称 示例:C:\Users\93997\Desktop\watermark tools\watermarkTools\src\main\resources\2024-2-8计算机.docx
* @param outFilePath 输出文件目录及名称 示例:C:\Users\93997\Desktop\watermark tools\watermarkTools\src\main\resources\2024-2-8.pdf
*/
public static void wordToPdf(String filePath, String outFilePath) {
//源文件地址
File inputWord = new File(filePath);
//导出文件地址
File outputFile = new File(outFilePath);
InputStream doc = null;
OutputStream outputStream = null;
try {
doc = new FileInputStream(inputWord);
outputStream = new FileOutputStream(outputFile);
IConverter converter = LocalConverter.builder().build();
//转换docx=>pdf
boolean flag = converter.convert(doc).as(DocumentType.DOC).to(outputStream).as(DocumentType.PDF).execute();
if (flag) {
converter.shutDown();
}
doc.close();
outputStream.close();
System.out.println("文件名:" + outFilePath + " 转换成功!");
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String filePath = "D:\\1.docx";
String outFilePath = "D:\\2.pdf";
//word转pdf
wordToPdf.wordToPdf(filePath, outFilePath);
}
}java实现word/doc/docx文档转PDF,超简单_java实现doc或者docx文档转化为pdf-优快云博客
44、 对时间的开始结束时间并集计算
1、先对开始时间排序
2、遍历时间区间,检查是否有重叠,将重叠的2个时间段合并,根据2个时间段的结束时间的大小,大的作为合并时间段的结束时间
3、循环2
// 按开始时间排序
Collections.sort(intervals, Comparator.comparing(interval -> interval.start));
List<TimeInterval> merged = new ArrayList<>();
TimeInterval current = intervals.get(0);
for (int i = 1; i < intervals.size(); i++) {
TimeInterval next = intervals.get(i);
if (current.end.isBefore(next.start)) {
// 没有重叠,添加当前区间
merged.add(current);
current = next;
} else {
// 有重叠,合并
current.end = current.end.isAfter(next.end) ? current.end : next.end;
}
}
// 添加最后一个区间
merged.add(current);45、计算时间区间的交集
1、使用两层循环遍历所有区间
2、计算每个区间的交集,如果最大开始时间在最小结束时间之前,就是有交集
List<TimeInterval> intersections = new ArrayList<>();
for (int i = 0; i < intervals.size(); i++) {
for (int j = i + 1; j < intervals.size(); j++) {
TimeInterval first = intervals.get(i);
TimeInterval second = intervals.get(j);
// 计算交集
LocalDateTime startMax = first.start.isAfter(second.start) ? first.start : second.start;
LocalDateTime endMin = first.end.isBefore(second.end) ? first.end : second.end;
if (startMax.isBefore(endMin)) {
intersections.add(new TimeInterval(startMax, endMin));
}
}
}46、根据秒计算时分秒
- 计算小时:将总秒数除以 3600(1小时=3600秒)。
- 计算分钟:用总秒数对 3600 取余,然后再将结果除以 60(1分钟=60秒)。
- 计算剩余的秒数:用总秒数对 60 取余。
public static void convertSeconds(int totalSeconds) {
int hours = totalSeconds / 3600; // 计算小时
int minutes = (totalSeconds % 3600) / 60; // 计算分钟
int seconds = totalSeconds % 60; // 计算剩余秒数
System.out.printf("%d seconds is equal to %d hours, %d minutes, and %d seconds.%n",
totalSeconds, hours, minutes, seconds);
}47、版本1.0.0.1这种格式的比较大小
UploadFtpSoft maxUploadFtpSoft = null;
for (UploadFtpSoft uploadFtpSoft : uploadFtpSoftList) {
if (maxUploadFtpSoft==null) {
maxUploadFtpSoft = uploadFtpSoft;
} else {
String[] maxVersions = maxUploadFtpSoft.getSoftVersion().split("\\.");
String[] curVersions = uploadFtpSoft.getSoftVersion().split("\\.");
for (int i=0;i<4;i++) {
int compareTo = maxVersions[i].compareTo(curVersions[i]);
if (compareTo!=0) {
if (compareTo <0) {
maxUploadFtpSoft = uploadFtpSoft;
}
break;
}
}
}
}

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









