







 这篇博客介绍了自然语言处理的基础知识,包括文本操作、语言模型、文本表示、文本分类、主题模型和seq2seq模型。重点讲解了Python中的NLTK库的安装和使用,包括如何解决下载数据集的问题,以及如何进行文本搜索、词汇计数等操作。
这篇博客介绍了自然语言处理的基础知识,包括文本操作、语言模型、文本表示、文本分类、主题模型和seq2seq模型。重点讲解了Python中的NLTK库的安装和使用,包括如何解决下载数据集的问题,以及如何进行文本搜索、词汇计数等操作。
自然语言处理学习路线
熟悉基本知识、基本操作
如文本操作、正则、掌握一些基本文本处理框架英文有NLTK、spaCy,中文有中科院计算所NLPIR、哈工大LTP、清华大学THULAC、Hanlp分词器、Python jieba工具库
知道什么是语言模型、利用语言模型来完成一些项目
文本表示:将文本中的字符串转化为计算机当中的向量
文本分类:分类模型传统的一个解决方法就是标带标注的语料,再特征提取,然后训分类器进行分类。这个分类器就会用比如说逻辑回归、贝叶斯、支持向量机、决策树等等。
主题模型:使用无监督学习的方式对文本中的隐含语义进行聚类的统计模型
seq2seq模型:通过深度神经网络将一个序列作为映射为另外一个输出的序列。
文本生成:GAN文本生成,也叫机器人写作。
下载相关语料库
1、NLTK包是Python中用于自然语言处理(Natural Language Processing,简称NLP)的第三方库。NLTK为澳洲学者Steven Bird, Ewan Klein, Edward Loper以Python为基础开发的模块,目前已发展超过十年,拥有超过十万行的代码。本文主要介绍NLTK安装及入门。
安装好nltk包之后,在配置数据源即使用nltk.download()报错:[WinError 10054]远程主机强迫关闭了一个现有连接
解决方法:首先手动下载nltk数据集(所有的)
链接:https://pan.baidu.com/s/1PVbGYhM2flwZbH1XR0Nv5A
提取码:qmiv
然后把下载好的压缩包解压至上图中的Download Directory目录下,即C:\DevelpoTools目录下,每个人的机子这个地方可能不一样。
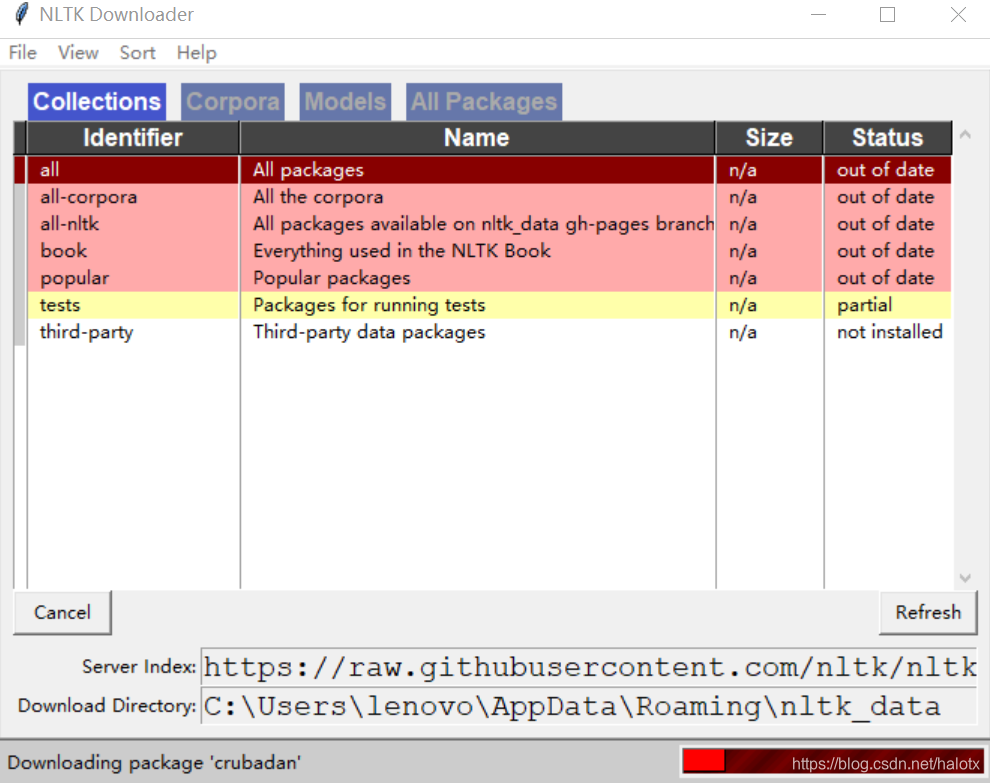
然后打开cmd,输入python,进入python命令行 ,输入from nltk.book import *,出现如下结果则说明安装成功
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









