






GBDT
gbdt是一种以CART树(通常)为基分类器的boosting算法,大家可以仔细查一下boosting的介绍,这里不再赘述。
gbdt通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,并且是低方差和高偏差的。因为训练的过程是通过降低偏差来不断提高最终分类器的精度,(此处是可以证明的)。

在训练的过程中,希望大家养成习惯, 参考API文档来选择参数
常见参数介绍:
loss : {‘deviance’, ‘exponential’}, optional (default=’deviance’)
loss:损失函数度量,有对数似然损失deviance和指数损失函数exponential两种,默认是deviance,即对数似然损失,如果使用指数损失函数,则相当于Adaboost模型。
learning_rate : float, optional (default=0.1)
学习率将每棵树的贡献缩小学习率。学习率和估计值之间有一个权衡。表示,向梯度最低点每次移动的步长一般设置为0.01,0.001等 一般学习率更低基分类器个数更多训练效果更好。
n_estimators : int (default=100)
表示基分类器的个数,或者boosting的轮数,要执行的增压阶段数。梯度助推对于过拟合是相当稳健的,因此大量的梯度助推通常会产生更好的性能。
subsample : float, optional (default=1.0)
采样比例,这里的采样和bagging的采样不是一个概念,这里的采样是指选取多少比例的数据集利用决策树基模型去boosting,默认是1.0,即在全量数据集上利用决策树去boosting。
criterion : string, optional (default=”friedman_mse”)
样本集的切分策略,决策树中也有这个参数,但是两个参数值不一样,这里的参数值主要有friedman_mse、mse和mae3个,分别对应friedman最小平方误差、最小平方误差和平均绝对值误差,friedman最小平方误差是最小平方误差的近似。“friedman_mse”的默认值通常是最好的,因为它可以在某些情况下提供更好的近似值
New in version 0.18.
min_samples_split : int, float, optional (default=2)
这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。 默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。我之前的一个项目例子,有大概10万样本,建立决策树时,我选择了min_samples_split=10。可以作为参考。
min_samples_leaf : int, float, optional (default=1)
这个参数是减枝策略,这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。 默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。我之前的一个项目例子,有大概10万样本,建立决策树时,我选择了min_samples_split=10。可以作为参考。
min_weight_fraction_leaf : float, optional (default=0.)
这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝。 默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。
max_depth : integer, optional (default=3)
决策树的最大深度,默认可以不输入,如果不输入的话,决策树在建立子树的时候不会限制子树的深度。一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。
max_features : int, float, string or None, optional (default=None)
节点分裂时参与判断的最大特征数
max_leaf_nodes : int or None, optional (default=None)
通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。
warm_start : bool, default: False
“暖启动”,默认值是False,即关闭状态,如果打开则表示,使用先前调试好的模型,在该模型的基础上继续boosting,如果关闭,则表示在样本集上从新训练一个新的基模型,且在该模型的基础上进行boosting。
min_impurity_decrease:节点划分最小不纯度:float, optional (default=0.)
这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值,则该节点不再生成子节点。
实际代码如下,可供参考
def train(X_train, y_train,X_test,y_test,params = {'n_estimators': 600, 'max_depth': 6, 'min_samples_split': 3,'learning_rate': 0.01, 'loss': 'ls','random_state':0}):
deno = np.sum(y_test)
print "training",X_train.shape,"testing gt num",deno
n_estimators = params['n_estimators']
clf = ensemble.GradientBoostingRegressor(**params)
#clf = ensemble.GradientBoostingClassifier(**params)
clf.fit(X_train, y_train)
mse = mean_squared_error(y_test, clf.predict(X_test))
test_result = enumerate(clf.staged_predict(X_test))
pred_test = np.zeros((n_estimators,X_test.shape[0]), dtype=np.float64)
test_score = np.zeros((n_estimators,), dtype=np.float64)
rec = [(0,0)]*n_estimators
for i, y_pred in test_result:
test_score[i] = clf.loss_(y_test, y_pred)
true,score = count(y_test,y_pred,orderid2)
try:
p,r,th = precision_recall_curve(true,score)
wh=np.searchsorted(p,0.90)
if i == 132:
print y_pred[ 346:352]
print i,sum(true),"precision",p[wh], "recall",r[wh],"threshold",th[wh]
rec[i] = (r[wh],sum(true))
pred_test [i] = y_pred
except:
continue集成学习中,我们也可以看到各个属性的重要性
from collections import OrderedDict
d = {}
for i in range(len(clf.feature_importances_)):
if clf.feature_importances_[i] > 0.01:
d[i] = clf.feature_importances_[i]
sorted_feature_importances = OrderedDict(sorted(d.items(), key=lambda x:x[1], reverse=True))
D = sorted_feature_importances
rects = plt.bar(range(len(D)), D.values(), align='center')
plt.xticks(range(len(D)), D.keys(),rotation=90)
plt.show() 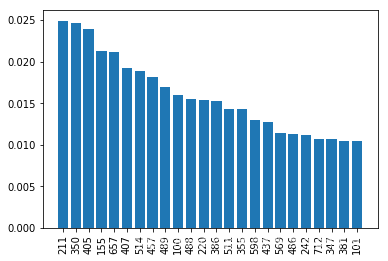


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









