









 文章讲述了在项目中使用InfluxDB处理交易流水时,遇到并发增加导致数据丢失的问题。问题出在时间戳生成方式上,解决方案是调整为纳秒级并加入递增序列以降低重复。作者提供了优化时间戳生成的代码示例。
文章讲述了在项目中使用InfluxDB处理交易流水时,遇到并发增加导致数据丢失的问题。问题出在时间戳生成方式上,解决方案是调整为纳秒级并加入递增序列以降低重复。作者提供了优化时间戳生成的代码示例。
项目场景:
项目中需要将交易流水插入到时序数据库influxdb中,数据库字段有请求流水号(每笔交易唯一值),请求方信息,请求地址,请求耗时等,每分钟汇总一次,然后通过监控页面展示实时交易量。
问题描述
一个请求时,可以正常插入到数据库;当请求并发提高时,则有部分数据会丢失,而且并发越大,丢失越多。
发送请求总数:
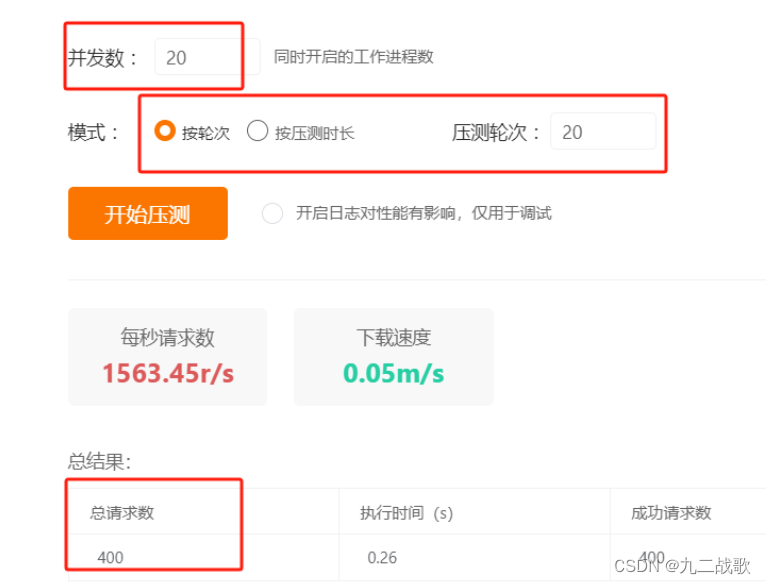
数据库数据总数:

原因分析:
本来我以为每条数据中流水号不一样,也就是Tag不一样,那么就不算重复数据,可是经过多次测试,Tag并不是决定性因素,而是由time决定,也就是构建Point时候设置的time,设置方式如下:
long time = System.currentTimeMillis() * 1000000L;
point.time(time, TimeUnit.NANOSECONDS)
以下是time在并发下的执行结果:
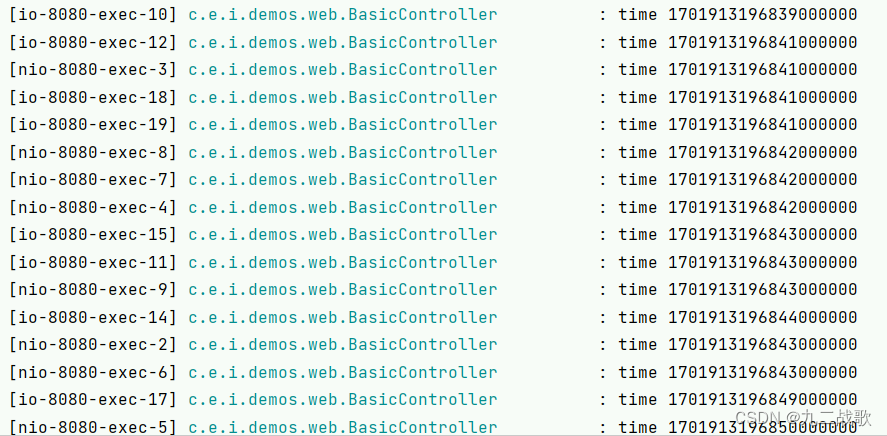
从结果可以看出,是有很多重复值,然后在工程中打印这个time,与数据库记录对比,结果丢失的数据与time重复的数量一致。
解决方案:
调整time的生成方式,精确到纳秒值,再加上一个递增序列,因为使用纳秒值多次测试也存在一定概率重复,所以加上一个递增序列,可以根据并发场景进行调整。代码如下:
/**
* @author 九二战歌
* @version 1.0
* @date 2023/12/4 18:11
* @description 获取纳秒值的工具类
*/
public class TimeStampUtils {
/**
* 递增数初始值
*/
private static long randomNum = 1L;
/**
* 递增数最大值,可根据并发情况适当调整
*/
private static final long RANDOM_NUM_MAX = 999L;
public static long getTimeStamp() {
long curRandomNum;
synchronized (TimeStampUtils.class) {
if (randomNum > RANDOM_NUM_MAX) {
randomNum = 1;
}
curRandomNum = randomNum++;
}
return System.currentTimeMillis() * 1000000L + System.nanoTime() % 1000000L + curRandomNum;
}
}



















 240
240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











