






 文章介绍了使用Python从grib文件中按需读取特定气候变量,包括定位、序列号操作和数据导出方法。
文章介绍了使用Python从grib文件中按需读取特定气候变量,包括定位、序列号操作和数据导出方法。
grib的数据集主要分为696种,因此对数据的读取首先需要对每一类进行获取。获取具体数据分类的代码如下:
import pygrib as pg
grbs = pg.open('fnl_20220720_12_00.grib2') # 所有变量
for grb in grbs:
print(grb) #每一个变量的头文件
输出结果如下:
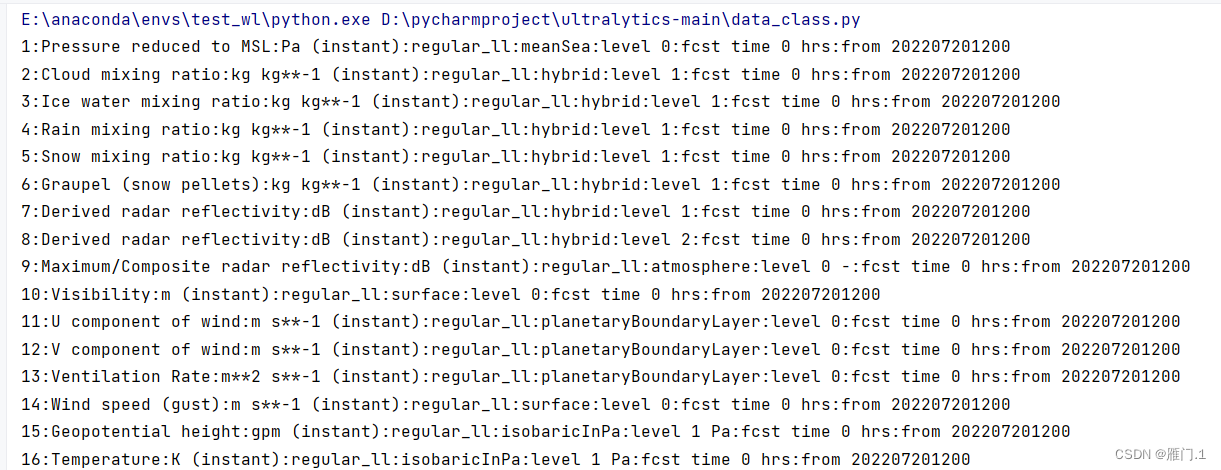
其实根据结果能看到,每一种类别对应的序列号和相关气候数据,这里的level是海拔。后面的202207201200是日期。而每一种类别比如温度temperature会在696种类别中出现很多次,每一次对应海拔高度,大气压强等气候参数都不同。因此需要那种情况下的数据需要根据具体情况提前确定好。
确定好之后可以根据序列号直接读取数据:
import pygrib as pg
import pandas as pd
import csv
grbs = pg.open('fnl_20220720_12_00.grib2') # 数据
grbs.seek(0)
variable_index = 176 # 序列号
for i, grb in enumerate(grbs):
if i == variable_index:
value = grb.values
data = pd.DataFrame(value)
data.to_csv('./要保存的数据文件名称.csv',index = False,header = False)
lats,lons = grb.latlons()
output_list = []
for i in range(lats.shape[0]):
zip1 = zip(lats[i],lons[i])
output_list.append(list(zip1))
output = pd.DataFrame(output_list)
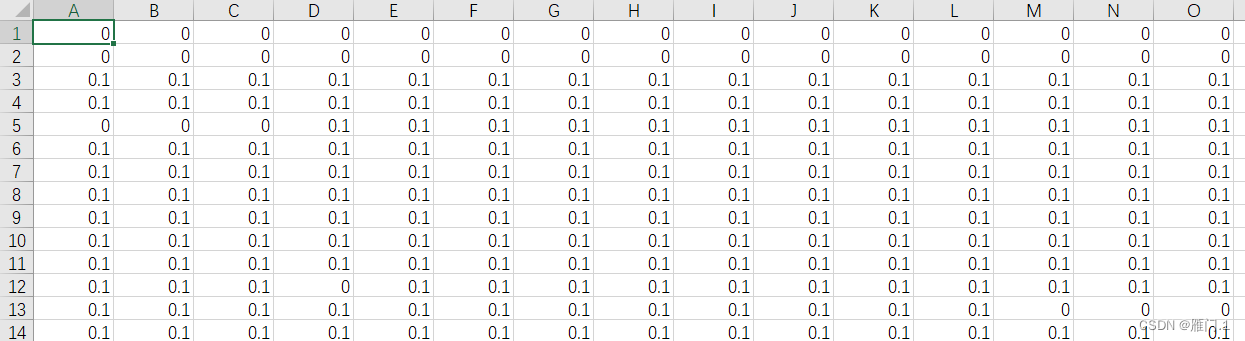
这里variable_index是序列号,只不过是从0开始,要读取177号数据,得输入variable_index = 176,读取后,保存为csv格式文件,文件名称在data.to_csv可以更改,下载后的文件可以直接打开,其中有180行(1~181,对应北纬90-南纬90),360列(1-361,东经180-西经180),根据经纬度即可读取相关数据。

















 1193
1193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









