




文章首发于微信公众号《与有三学AI》
这是深度学习模型解读第5篇,本篇我们将介绍深度学习模型中的pooling。
作者&编辑 | 言有三
01 概述
相信大家都记得,LeNet5,AlexNet,Vgg系列的核心思想,是convolution+pooling的核心结构。

但是,不知道从何时开始,pooling没了,对,就是没了。这是mobilenet【1】可视化后的部分结构图,懒得去画block图了。

如今大部分情况下,pooling就出现在网络的最后,或者一些需要concat/add不同通道的block里面,为何?本文从3个方面来说说。
02 pooling是什么
pooling,小名池化。
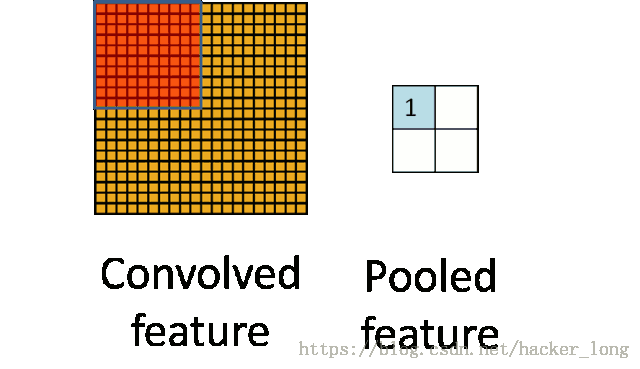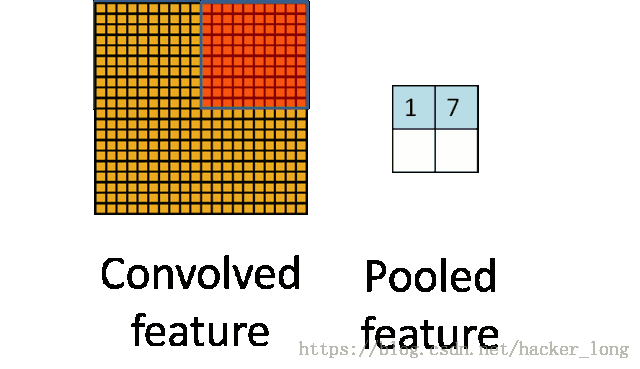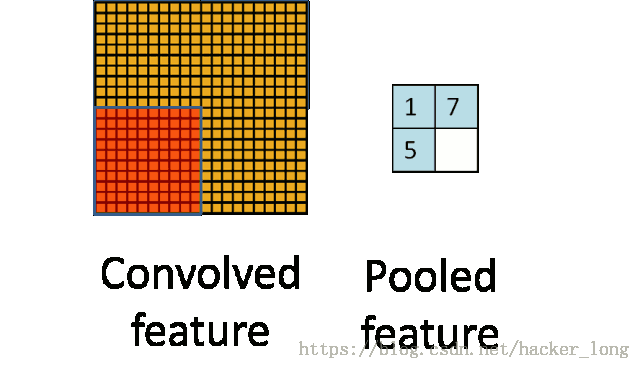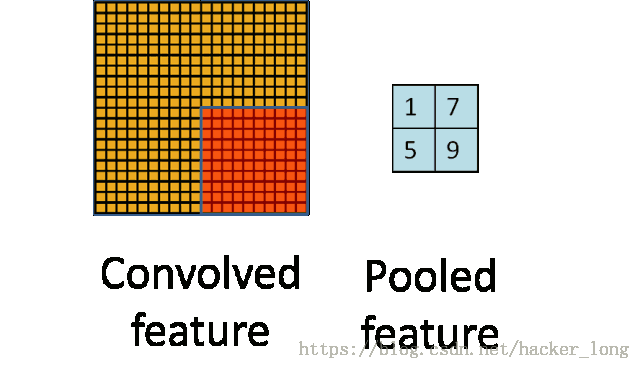
上图就是一个池化的示意图,用了一个10*10的卷积核,对20*20的图像分块不重叠的进行了池化,池化之后featuremap为2*2的大小。
pooling有什么用呢?或者说为什么需要pooling呢?
原因有几个:
(1) 增大感受野
所谓感受野,即一个像素对应回原图的区域大小,假如没有pooling,一个3*3,步长为1的卷积,那么输出的一个像素的感受野就是3*3的区域,再加一个stride=1的3*3卷积,则感受野为5*5,我们看左上角像素的传播就明白了。
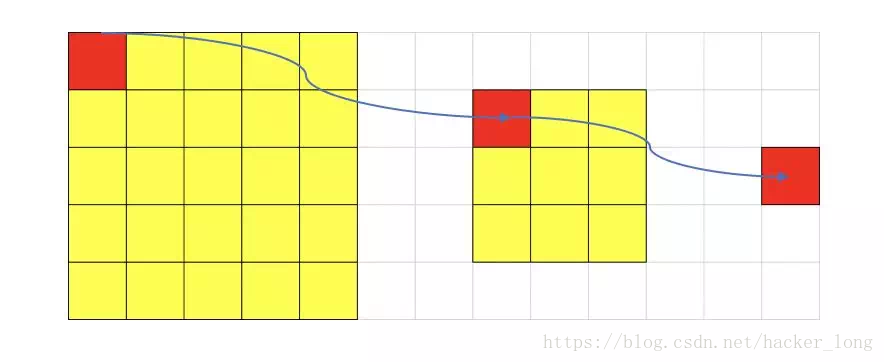
依次,再多一个卷积,则为7*7,如果想看到224*224的全图,大家可以算算需要多少卷积层。
假如我们在每一个卷积中间加上3*3的pooling呢?很明显感受野迅速增大,这就是pooling的一大用处。感受野的增加对于模型的能力的提升是必要的,正所谓“一叶障目则不见泰山也”。
(2) 平移不变性
我们希望目标的些许位置的移动,能得到相同的结果。因为pooling不断地抽象了区域的特征而不关心位置,所以pooling一定程度上增加了平移不变性。
(3) 容易优化,pooling是每个featuremap单独做降采样,与基于卷积的降采样相比,不需要参数,更容易优化。
03 如何去除pooling
那pooling是必要的吗?答案已经很明了了,不需要。文【2】做了详细的实验,在cifar,imagenet等多个数据集上实验结果表明,完全没有必要。因为我们可以用步长大于1的卷积来替代。
当步长不为1时,降采样的速度将变快。

当stride,也就是步长等于2,上面的5*5一次卷积后就为2*2了。这其实还减轻了重叠的卷积操作,通过卷积来学习了降采样,看起来好处还是不少的。
实验结果也佐证了这一点。
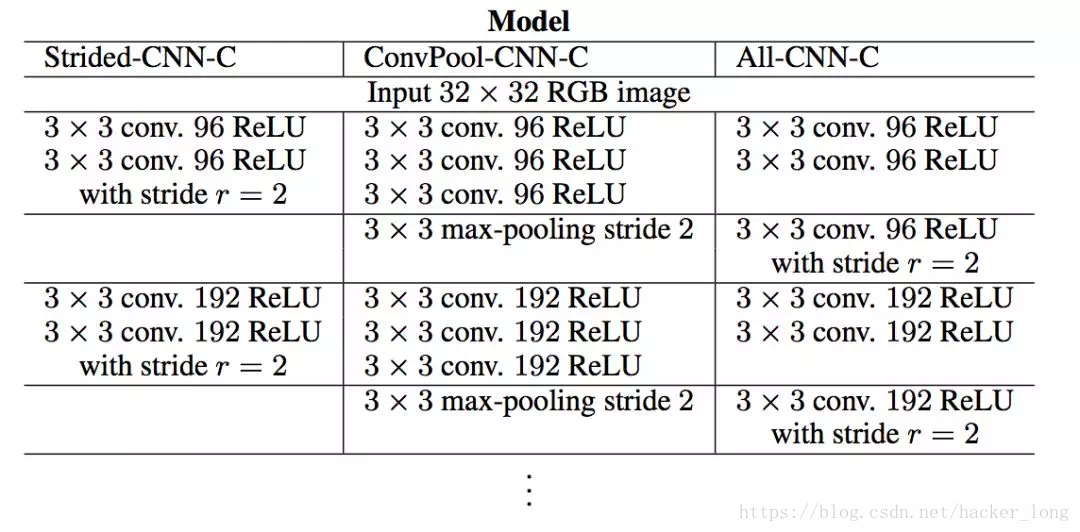
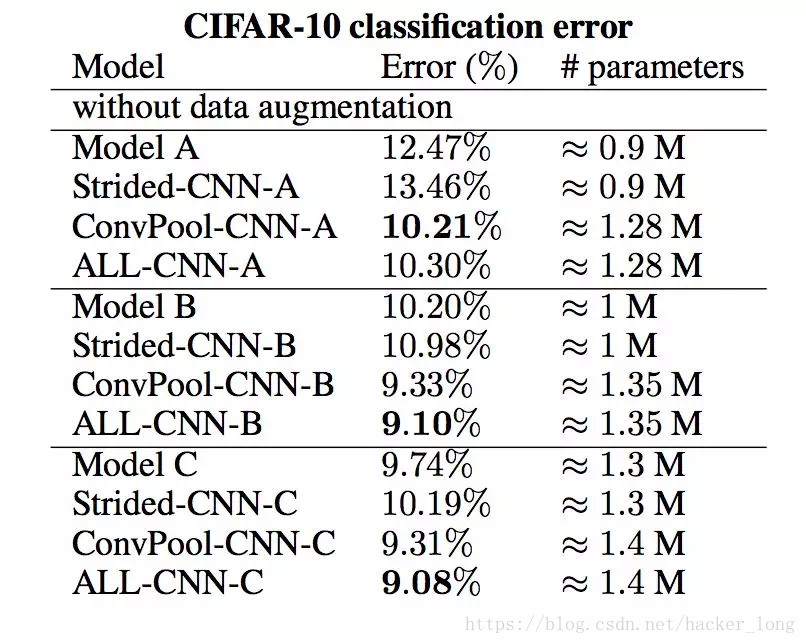
上面就是作者的实验结果,all-cnn-c相比convpool-cnn-c,就是在同等卷积层的基础上,去掉了pooling,结果B和C系列模型效果都是提升的,关于A,B,C系列具体细节大家可以参考文章。
总之,不管是文献的研究结果,以及大家的实际使用经验,都已经完全使用带步长的卷积替换掉了pooling这一降采用的操作。
04pooling没用了吗?
答案是有,因为pooling相对于带步长的卷积操作,毕竟减少了计算量,所以对于很多需要concat/add featuremap通道的小模型,pooling仍然可以以小搏大。比如下面的shufflenet的block。
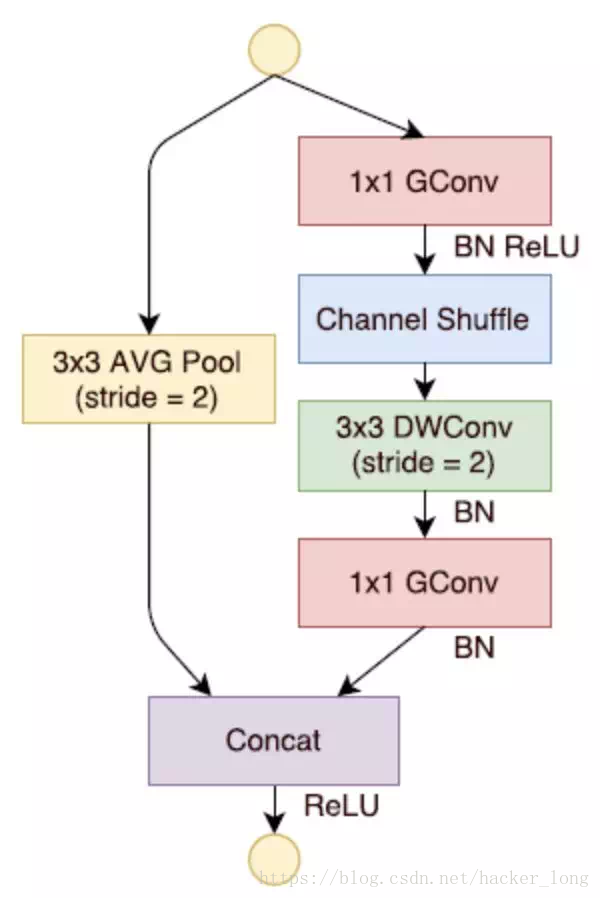
不过总的来说,pooling,走好。
参考文献
【1】Howard A G, Zhu M, Chen B, et al. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications[J]. 2017.
【2】Springenberg J T, Dosovitskiy A, Brox T, et al. Striving for Simplicity: The All Convolutional Net[J]. Eprint Arxiv, 2014.
【3】Zhang X, Zhou X, Lin M, et al. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices[J]. 2017.
同时,在我的知乎专栏也会开始同步更新这个模块,欢迎来交流
https://zhuanlan.zhihu.com/c_151876233
注:部分图片来自网络
—END—
转载请留言,侵权必究
本系列的完整目录:
【模型解读】从LeNet到VGG,看卷积+池化串联的网络结构
【模型解读】network in network中的1*1卷积,你懂了吗
【模型解读】GoogLeNet中的inception结构,你看懂了吗
感谢各位看官的耐心阅读,不足之处希望多多指教。后续内容将会不定期奉上,欢迎大家关注有三公众号 有三AI!



















 965
965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











