



 本文介绍了有三AI的计算机视觉课程体系,特别是深度学习视觉Transformer课程,涵盖理论原理、实现方法、各类Transformer模型及其应用,由经验丰富的讲师言有三主讲,旨在帮助学员掌握Transformer和VisionTransformer技术。
本文介绍了有三AI的计算机视觉课程体系,特别是深度学习视觉Transformer课程,涵盖理论原理、实现方法、各类Transformer模型及其应用,由经验丰富的讲师言有三主讲,旨在帮助学员掌握Transformer和VisionTransformer技术。
前言
欢迎大家关注有三AI的视频课程系列,我们的视频课程系列共分为5层境界,内容和学习路线图如下:
第1层:掌握学习算法必要的预备知识,包括Python编程,深度学习基础,数据使用,框架使用。
第2层:掌握CV算法最底层的能力,包括CNN模型,Transformer模型,图像分类,模型分析。
第3层:掌握CV算法最核心的方向,包括图像分割,目标检测,图像生成,目标跟踪。
第4层:掌握CV算法最核心的应用,包括人脸图像,图像质量,视频分析,图像编辑。
第5层:掌握算法落地的关键技术,包括模型优化,模型部署。
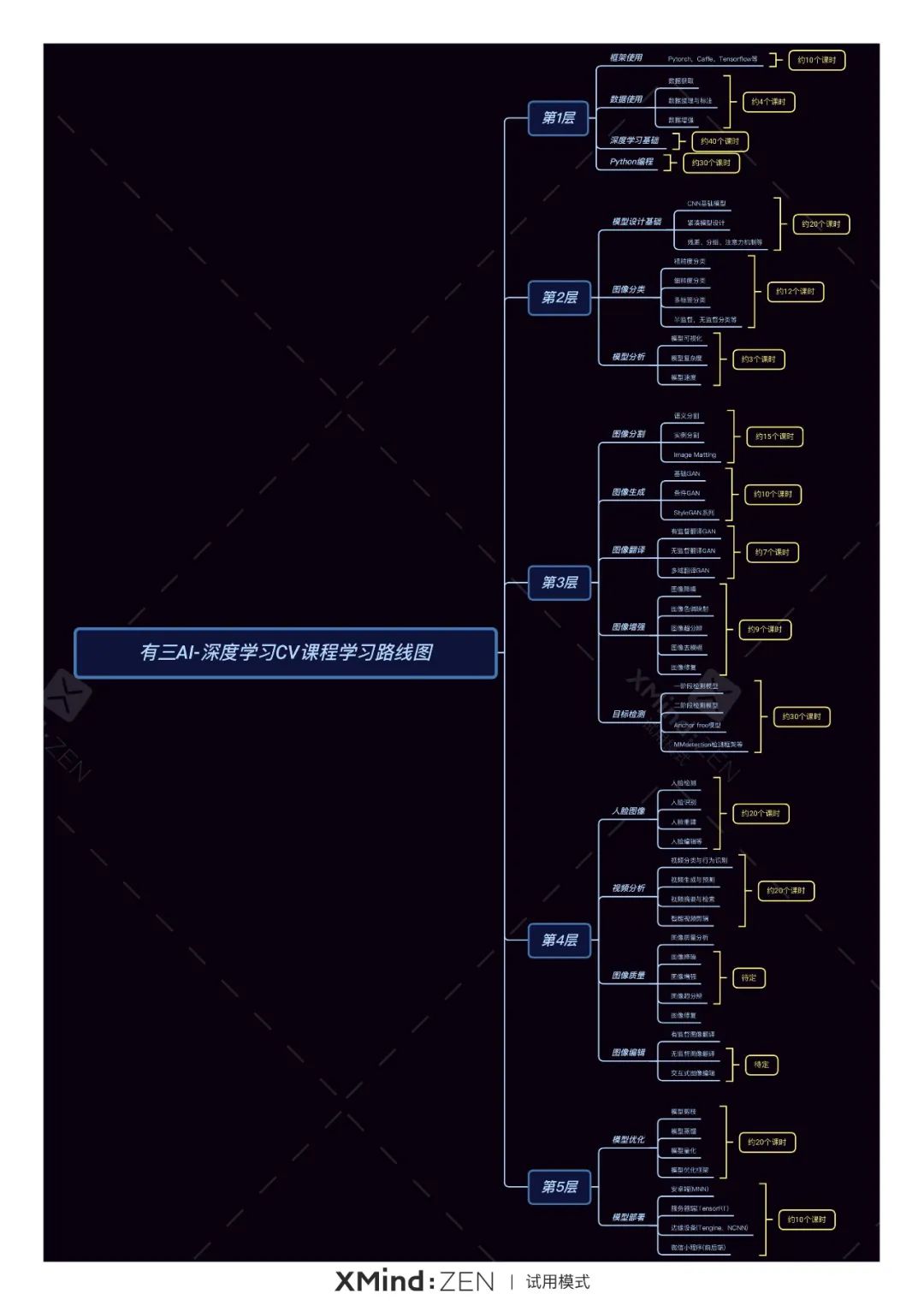
其中部分课程的主体内容已经更新完毕,比如数据使用/模型分析/图像分类/图像分割/目标检测/图像生成/图像翻译/视频分类/模型部署/模型优化/人脸图像检测与识别/人脸图像属性编辑;部分课程正在重制更新中,比如三维人脸重建;部分课程正在计划上线中,比如图像编辑,请大家及时关注!
最新的完整介绍如下:【总结】最专业最系统的CV内容,有三AI所有免费与付费的计算机视觉课程汇总(2022年8月)

本次给大家介绍的课程内容是《深度学习之视觉Transformer模型:理论实践篇》,目标是帮助大家掌握Transformer模型以及各类常见的Vision Transformer模型的原理与实践。
为什么要学习这门课
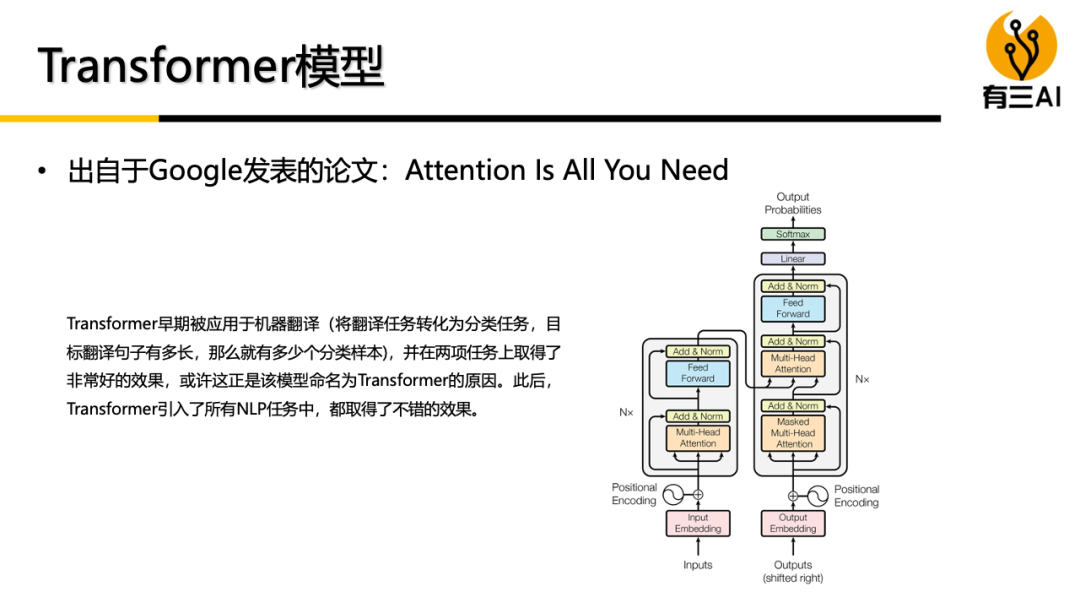
随着Transformer模型的诞生,自然语言处理领域进入了预训练模型时代,随后研究者开始将Transformer模型迁移到计算机视觉领域,并在学术上取得了许多进展,提出了各种各样的Vision Transformer模型,在性能上不输CNN模型。
这两年GPT等大语言模型的进展深刻地改变了行业,国内外涌现出了数以千计的大模型与相关的创业公司,ChatGPT等综合性聊天机器人改变了大家的工作习惯。

ChatGPT工具
在视觉领域,以Stable Diffusion等模型为代表的文生图框架也引领了新一代生成式技术的发展,AI创作的图片和短视频如今遍布互联网,其质量已达到商业化落地水平。

Stable Diffusion生成效果图
不管是大语言模型还是视觉大模型,其背后不可缺少的核心模型是Transformer。为了帮助大家掌握好Transformer以及Vision Transformer的原理与实践,我们推出了《深度学习之视觉Transformer:理论与实践》系列课程,目前已完成超过了7个小时内容,约450分钟(还在更新中)。
课程内容介绍
本课程内容涵盖了自注意力原理,Transformer的原理与实现,各类Vision Transformer的原理与实现,以及Vision Transformer的训练等内容,既有足够的宽度,也具备有足够的深度。我们会非常详细地讲解算法中的细节,帮助彻底消化算法原理;
下图是已有课程的大纲脑图,共分为5大模块。
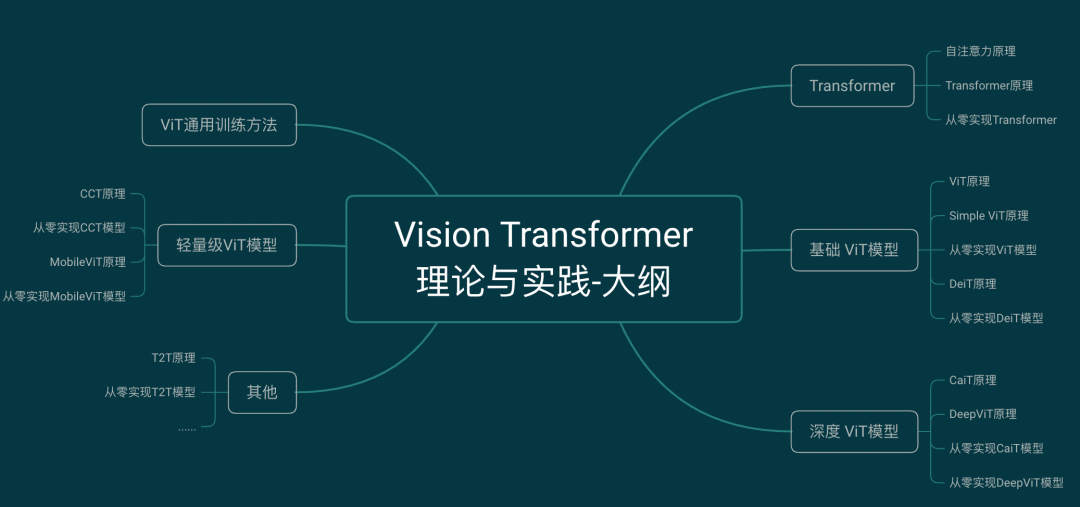
下面简单了解一下各部分的内容:
(1) Transformer,包括自注意力原理,Transformer原理以及从零进行代码实现,约135分钟,超过两个小时,本部分内容可以免费学习。

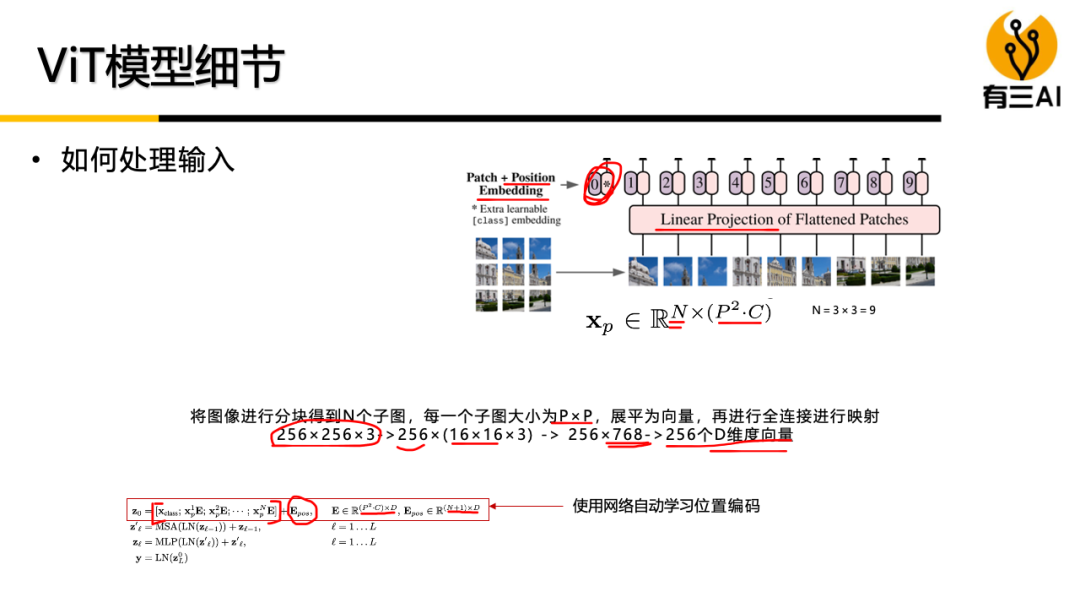
(2) 基础Vision Transformer模型,包括ViT与Simple ViT模型原理,DeiT模型原理,从零实现ViT与Simple ViT模型,DeiT模型,约100分钟。

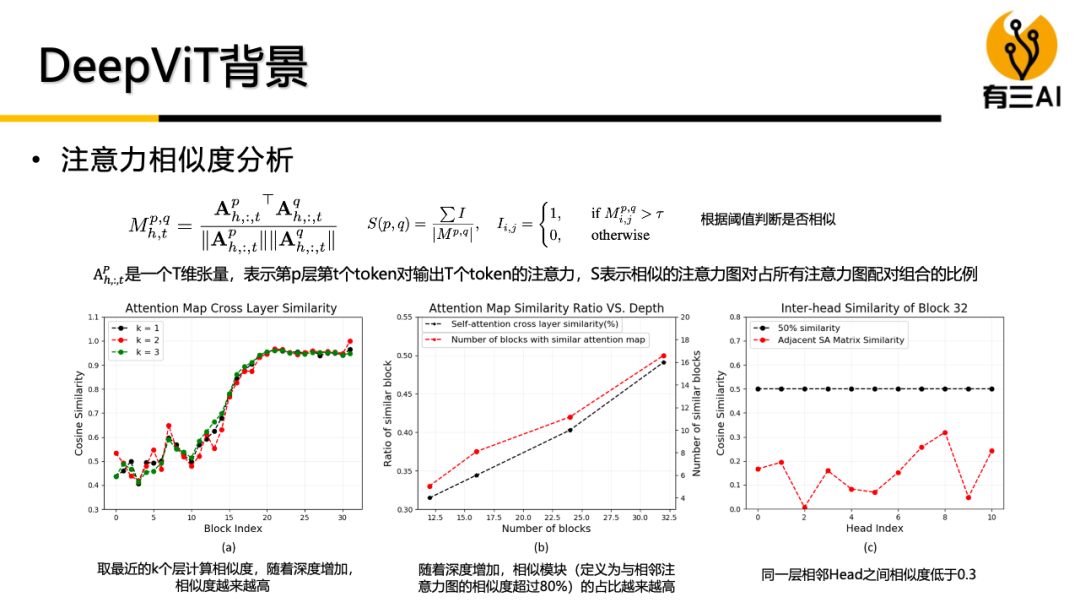
(3) 深度Vision Transformer模型,包括DeepViT原理与实现,CaiT原理与实现,约80分钟。

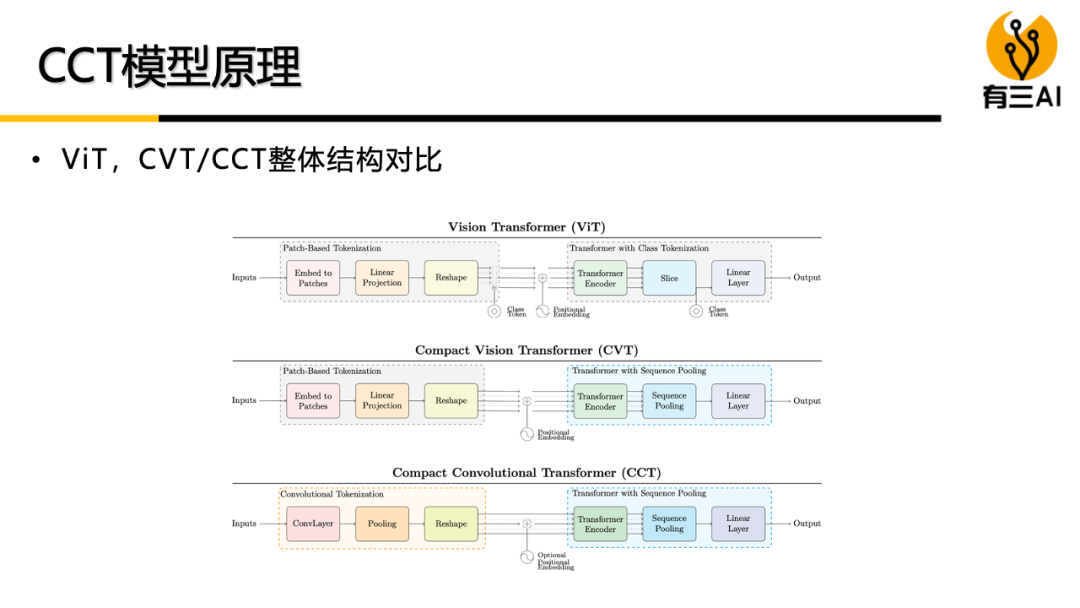
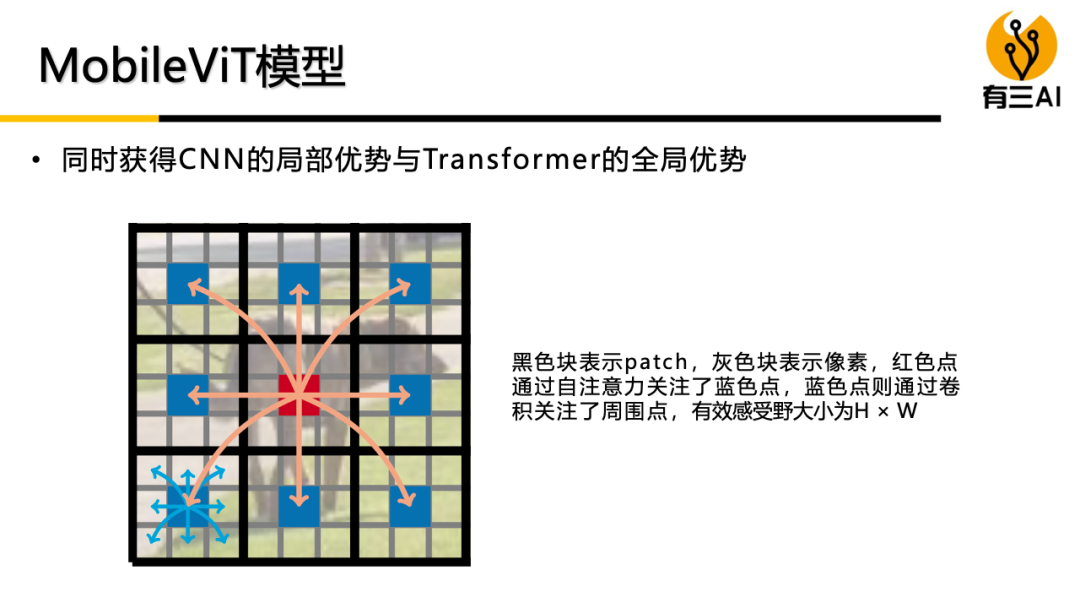
(4) 轻量级ViT模型,包括Compact ViT原理与实现,MobileViT原理与实现,约90分钟。
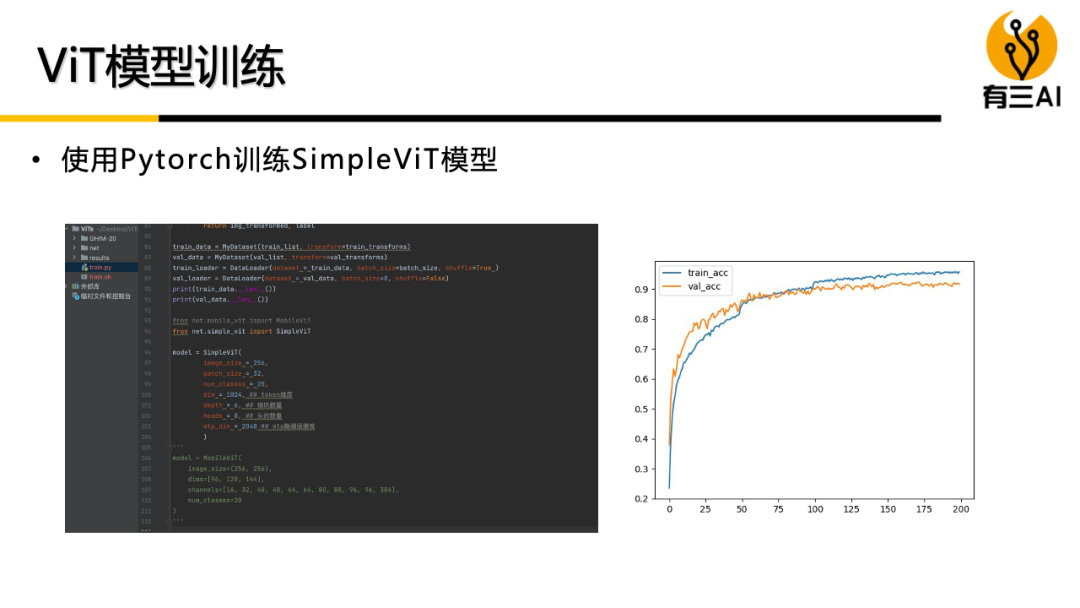
(5) ViT模型训练实战,包括适用于课程中所有ViT模型训练的通用代码模板讲解,约20分钟。

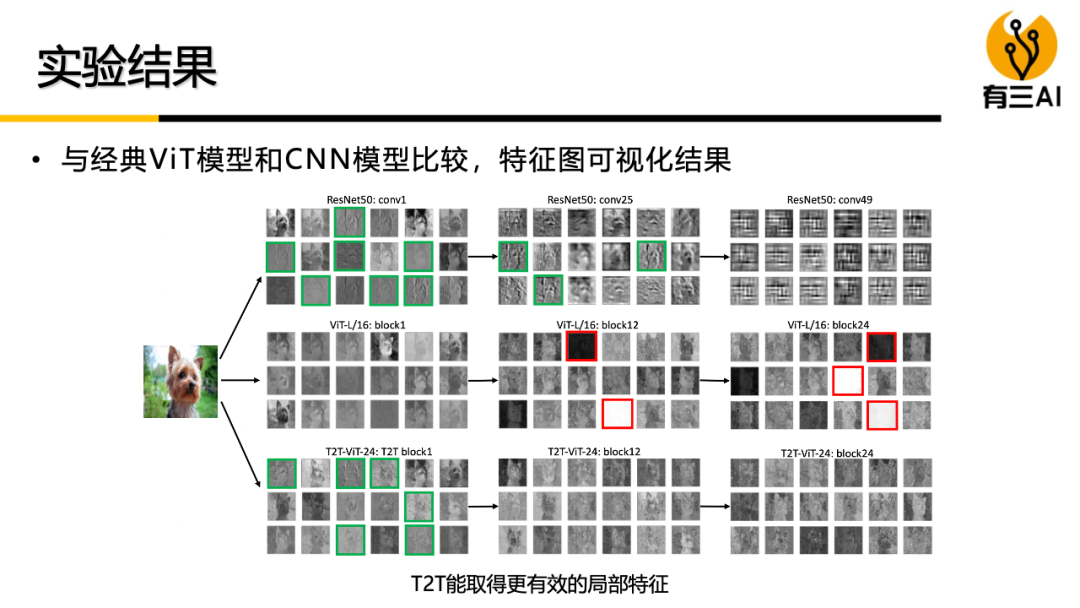
(6) 其他内容,如Token2Token模型原理讲解与从零实现等,时长约30分钟。

本课程讲师为言有三,讲师简介如下:

龙鹏,笔名言有三,技术社区《有三AI》创始人。先后就读于华中科技大学(2008-2012),中国科学院半导体研究所神经网络实验室(2012-2015),先后就职于奇虎360人工智能研究院(2015-2017),陌陌科技深度学习实验室(2017.5-2019.3),深度学习算法专家,阿里云MVP,华为云MVP。
拥有超过7年的深度学习领域从业经验,著有书籍《深度学习之图像识别:核心技术与案例实战》(机械工业出版社2019.4),《深度学习之模型设计:核心算法与案例实践》(电子工业出版社2020.6),《深度学习之人脸图像处理:核心算法与案例实战》(机械工业出版社2020.7),《深度学习之摄影图像处理:核心算法与案例精粹》(人民邮电出版社2021.4),《生成对抗网络GAN:原理与实践》(机械工业出版社2022.10),《深度学习之图像识别:核心算法与实战案例(全彩色版)》(清华大学出版社2023.8)。

如何获取课程
订阅本课程的方法有两个:
其一:订阅《深度学习之视觉Transformer—理论与实践》专栏,链接如下:
已有的课程目录如下:

其二:参加有三AI-CV中阶-模型算法组,模型算法组可以获得所有模型分析,设计,优化与部署相关的内容,其介绍如下:
【一对一小组】2024年有三AI-CV中阶-模型算法组发布,如何循序渐进地学习好模型原理与部署落地
学习资料是死的,但在学习过程中会源源不断地遇到问题,这些不是录制好的音视频能解决的,后续的课程答疑服务更加重要,尤其是对于新手学习者而言。在订阅后课程后,请添加弹出的联系方式,验证课程权限后进入相关答疑群进行交流,本课程讲师将负责在群内相关课程内容答疑。



往期相关


















 529万+
529万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











