



 本文介绍了变分自编码器(VAE)的基本原理,包括自编码器的概念、VAE的数学模型及其实现方式,如编码器、解码器的设计,以及重参数技巧的应用。
本文介绍了变分自编码器(VAE)的基本原理,包括自编码器的概念、VAE的数学模型及其实现方式,如编码器、解码器的设计,以及重参数技巧的应用。
最近在学习生成模型的相关知识,这篇文章将介绍一下变分自编码器(Variational Auto-encoder),本文只介绍一些粗浅内容,不会涉及比较深刻的问题。
作者&编辑 | 小米粥
1. 自编码器
自编码器(autoencoder)在深度学习中占有重要地位,它最开始的目的是用于降维或特征学习。一般的自编码器由编码器(encoder)和解码器(decoder)两个神经网络构成,如下图所示:

样本x经过编码器得到它的某种编码表示z,而且z的维度小于x,再将z送入解码器则可得到样本x的重构x'。如果重构的效果比较好,则认为编码器成功地学到了样本的抽象特征,也可以理解为实现了降维。
当编码器学习到数据的抽象特征z后,我们不仅可以用于重构样本,还可以把提取到的抽象特征用于分类问题,只需要在编码器后接一个分类器即可,如下图所示:

到了VAE,则期望构建一个生成模型,它将z视为生成样本的隐变量(隐变量,顾名思义是指不可观测到的变量,但其对模型中可观察变量的输出存在影响),并对编码器和解码器进行了一些修改,最终实现了一个性能卓越的生成模型。
2.VAE的思想
与FVBN和GAN等生成模型不同,我们希望通过定义一个由隐变量“控制”的生成模型:

这个生成模型生成样本的方式将十分简洁优雅:先从隐变量的分布Pθ(z)中采样得到z,然后在条件分布Pθ(x|z)中采样即可得到生成样本,但是这个生成模型无法搭建出来!因为训练生成模型通常需要将对数似然函数极大化来求解模型参数θ,即对训练样本{x(1),x(2),...,x(n)},要求

这里必然要计算Pθ(x),分析Pθ(x)的计算式,积分号内部的计算没有问题,对于隐变量的先验分布Pθ(z)可以将其设计为简单的高斯分布,对Pθ(x|z)可使用一个神经网络来学习,无法解决的地方是遍历所有的隐变量z求积分!而且,隐变量z的后验分布

也是难以求解的(因为其分母无法计算)。
一般的训练生成模型必须先求解对数似然函数(也就是说以似然函数作为损失函数),然后使其最大,VAE的想法是:虽然无法求解准确的对数似然函数,但可以设法得到对数似然函数的下界,然后令下界极大即可,这就相当于近似地令对数似然函数达到极大了。
具体做法是这样的:刚才说到隐变量z的后验分布Pθ(z|x)是难以计算的,VAE引入了一个新的概率分布qφ(z|x)来逼近Pθ(z|x),这时的对数似然函数为

最终的式子由三项组成,前两项是可以计算的,处理细节下面再说,第三项无法计算,但是根据KL散度的性质可知第三项必定大于等于0(这个性质涉及到泛函中的变分,变分自编码器的变分即来源于此),也就是说

我们将上述不等式右侧称为一个变分下界(ELBO),记为L(x(i);θ,φ),这时只需要最大化变分下界即可,即将变分下界作为模型的损失函数:

VAE的最核心的想法已实现,接下来将描述一些细节,如何将数学模型转换到神经网络上?如何计算变分下界EBLO。
3. 编码器
首先关注EBLO的第二项 ,它是计算隐变量的后验分布的近似分布qφ(z|x(i))和隐变量的先验分布Pθ(z)的KL散度。在基于实际中的经验,作出两个假设:1.隐变量的先验分布Pθ(z)为D维标准高斯分布N(0,I),注意这时的Pθ(z)将不包含任何参数,重新记为P(z);2.隐变量的后验分布的近似分布qφ(z|x(i))为各分量彼此独立的高斯分布N(μ,Σ;x(i)),也就是说对每一个样本x(i),均对应一个高斯分布N(μ,Σ;x(i))。现在需要只要再知道μ(x(i)),Σ(x(i))就可以计算KL散度了,我们用两个神经网络(即编码器,参数为φ)来求解均值、方差的对数(因为方差的对数的值域为全体实数,而方差的值域为全体正实数,使用神经网络拟合方差的对数不需要精确设计激活函数的值域,相对方便)。由于D维的隐变量z的每个维度彼此独立,则均值为D维向量,而方差为D维对角矩阵,即

方差其实也只有D个需要学习参数,而不是DxD个。这里所谓的编码器的输入为样本x(i),第一个编码器输出D维向量为

第二输编码器出也为D维向量,即:

即有

由于两个高斯分布每个维度彼此独立,KL散度可分开计算,其中第d维的KL散度值为:

上述计算过程比较简单,在此不展开。由于每个分量彼此独立,易知总KL散度为:

在计算上,通过让编码器学习隐变量后验分布的近似分布的均值和方差,得到了隐变量后验分布的近似分布的表达式,从而可以计算KL散度,本质上,VAE训练编码器是希望KL散度值达到最小,即令后验近似分布趋近于标准正态分布,就是说对每个样本 , qφ(z|x(i)) 都向标准高斯分布靠拢。
4. 解码器
现在关注ELBO的第一项 ,为了计算这一项,需要使用一个经验上的近似

意思是说计算这项时并不需要采样所有不同z再计算log P(x(i)|z)求均值,而只需要从中采样一次即可。这样的做法看似是不合理,但实际效果证明约等于的关系是成立的,联想到普通自编码器中是一一映射的,一个样本x对应一个隐变量z,可想象qφ(z|x(i))是一个非常锐利的单峰分布,故多次采样计算均值和一次采样效果相差不大。
接下来,为了计算log P(x(i)|z),我们再次作出假设,假设Pθ(x|z)是伯努利分布或高斯分布。当假设为伯努利分布时,对应x为二值 、Q个维度彼此独立的向量,而伯努利分布的Q个参数交给神经网络学习,这个神经网络即解码器,它由θ来参数化,输入为隐变量z,输出为:

即
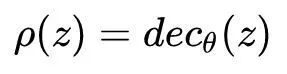
现在可以计算样本的似然为:

相应的对数似然为:

所以只需要把编码器的最后一层激活函数设计为sigmoid函数,并使用二分类交叉熵作为解码器的损失函数即可。
若假设Pθ(x|z)为高斯分布,对应x为实值、Q个维度彼此独立的向量,而高斯分布每个维度的方差固定为某个常数σx σ,Q个均值参数交给神经网络学习,这个神经网络即解码器,它由θ来参数化,输入为隐变量 ,输出为
解码器即

现在可以计算样本的似然函数为:

相应的对数似然为:

所以需要把编码器的最后一层激活函数设计值域为全体实值的激活函数,并使MSE作为损失函数即可。
在计算上,基于经验知识使用了一次采样的近似操作,并依靠编码器学习Pθ(x|z)的参数,最后计算了条件概率下样本的似然。VAE希望将解码器部分对应的损失函数最大,本质上是希望样本的重构误差最小,这在伯努利分布中非常明显,在高斯分布中,MSE损失希望将编码器的输出(高斯分布的均值)与样本接近。
5.重参数
回顾上面的过程,正向推断过程是这样的:将样本x(i)送入编码器可计算得到隐变量后验近似分布的各项参数(即高斯分布的均值和方差),这时需要从分布中采样一个隐变量z,然后将z送入编码器,最后计算损失函数,反向传播更新参数。
其实这里一个小问题,从分布中采样的过程是不可导的,即编码器计算的均值和方差参数在采样得到隐变量后就被“淹没”了,解码器面对的只是一个孤立的不知从哪个高斯分布采样得到的z。需要把μ和Σ告诉编码器,否则反向传播时,梯度传到采样得到的z就会断掉。
重参数技巧(Reparameterization Trick)做了一个简单的处理,采样隐变量时,直接在标准正太分布N(0,I)中采样得到 ,然后考虑编码器学得的均值和方差参数,令

这样,反向传播的环节被打通。为了便于直观理解,整个VAE的正向流程如下图所示:

训练完成后,推断时,直接从标准高斯分布p(z)中采样得到隐变量z,然后送入解码器,在伯努利分布中解码器输出概率值;在高斯分布中解码器输出均值,即生成的样本。
6. 小评
VAE与GAN不同,GAN属于隐式概率生成模型,在GAN中没有显式出现过似然函数,而VAE属于显式概率生成模型,它也力求最大化似然函数,但是不像FVBN模型中存在精确的似然函数以供最大化,VAE得到了似然函数的下界,近似地实现了极大似然。
在图像生成问题上,VAE的优点是多样性好,而一个比较明显的缺点是,生成图像模糊,这可能是使用极大似然的模型的共同问题,因为极大似然的本质是最小化

再深入一些,这个问题的解释设计到KL散度的性质,在此便不再展开。
[1]Kingma, Diederik P., and Max Welling. "Auto-encoding variational bayes." arXiv preprint arXiv:1312.6114 (2013).
总结
这篇文章讲了一下原始的自编码器,然后讲了VAE的基本思想,以及如何构造编码器和解码器,最后简要对VAE的一个缺点进行了评价。
知识星球推荐

有三AI知识星球由言有三维护,内设AI知识汇总,AI书籍,网络结构,看图猜技术,数据集,项目开发,Github推荐,AI1000问八大学习板块。
转载文章请后台联系
侵权必究


往期精选



















 503
503




 到【灌水乐园】发言
到【灌水乐园】发言









