






掩码
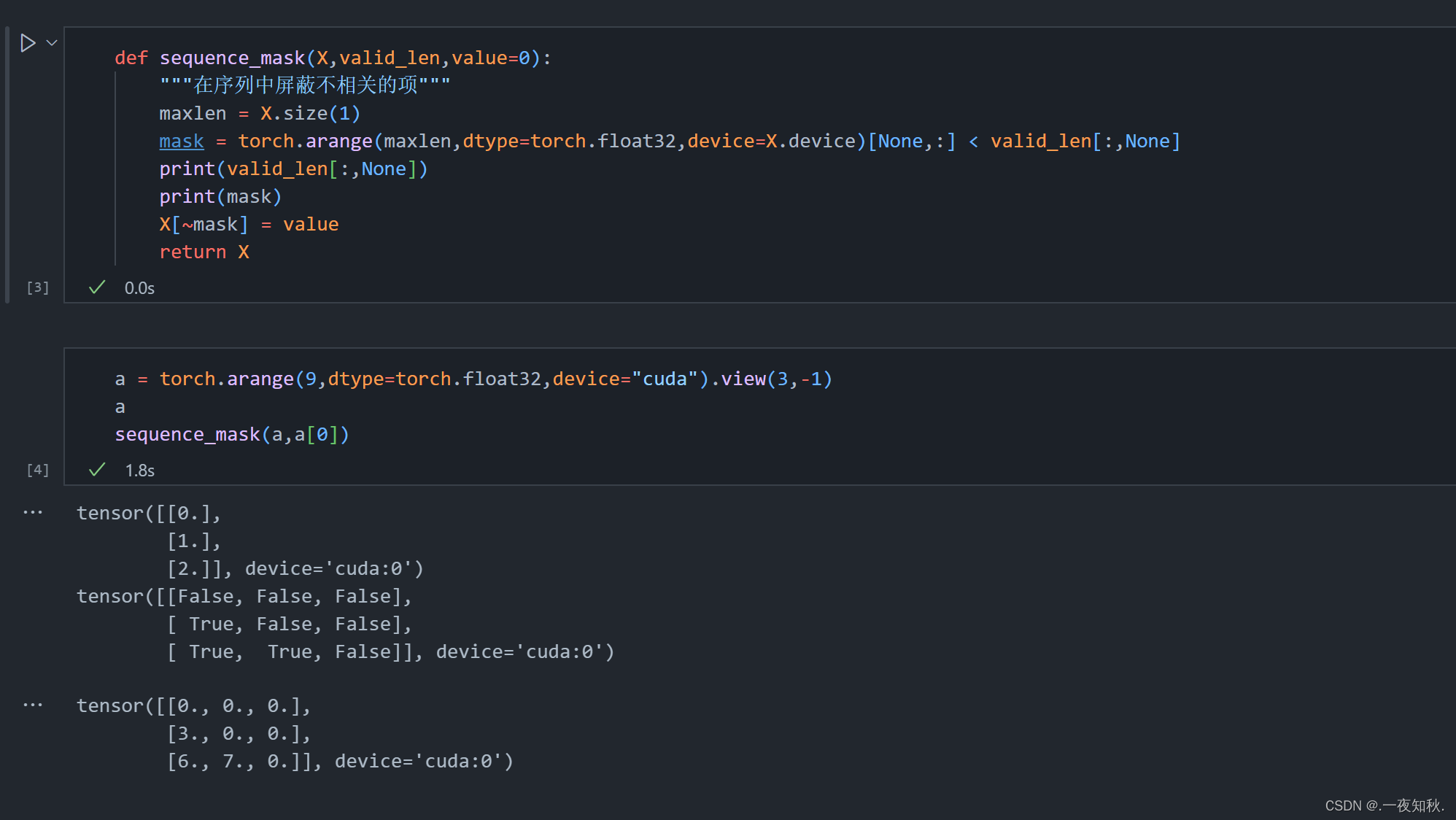
def sequence_mask(X,valid_len,value=0):
"""在序列中屏蔽不相关的项"""
maxlen = X.size(1)
mask = torch.arange(maxlen,dtype=torch.float32,device=X.device)[None,:] < valid_len[:,None]
X[~mask] = value
return XX.size(1) 这里的目的是说获得每一行序列的最大长度maxlen
mask这里,首先说一下torch.arange(maxlen,dtype=torch.float32,device=X.device)
生成一个从0至maxlen-1的一维张量,数据格式为float32,并保存至X当前所在的设备(cpu/gpu)
[None,:] < valid_len[:,None],即mask[None,:] < valid_len[:,None],用了广播,也就是两个一维向量,变成了二维张量,之后再进行比较,假如valid_len是[0,1,2],那么valid_len[:,None]为tensor([[0.], [1.], [2.]], device='cuda:0')
~mask这里是取反的意思,~False=True,即mask中为false的元素,对应X中赋值为value
掩蔽softmax操作
def masked_softmax(X,valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
# X:3D张量,valid_lens:1D或2D张量
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = sequence_mask(X.reshape(-1,shape[-1]), valid_lens, value=-1e6)
return nn.functional.softmax(X.reshape(shape),dim=-1)
1.首先看一下掩蔽的长度,没有的话直接掩蔽
2. else中 看一下valid_lens是不是一维还是二维,一维的话,通过repeat_interleave函数创建符合shape[1]的新的张量。(repeat_interleave的作用是将一维张量中的元素重复多次以创建一个新的一维张量);
如果是valid_lens二维的话则降维成一维
3. 接下俩通过刚才的函数sequence_mask对当前的矩阵进行掩蔽(此时X是3D张量,需要将其变为二维,我们是对最后一个维度进行掩蔽,那么我们可以将前两个维度降维在一起,即为啥是X.reshape(-1,shape[-1])。那么怎么变回来呢? 还记得else下面有个shape = X.shape的代码吗?这里记载的就是刚输入的X的大小,那么通过这个再次reshape就可以恢复了(2D->3D),第一维恢复成原先的前两维)
4.恢复成原状后进行softmax
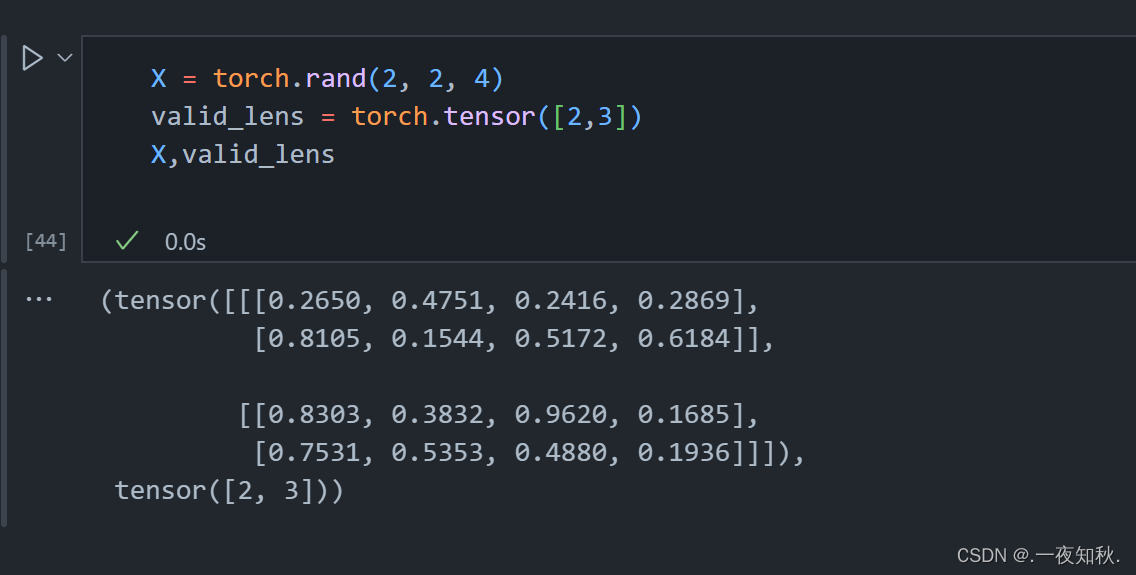
我的学习过程中的一些数据测试
def sequence_mask(X,valid_len,value=0):
"""在序列中屏蔽不相关的项"""
maxlen = X.size(1)
mask = torch.arange(maxlen,dtype=torch.float32,device=X.device)[None,:] < valid_len[:,None]
print(X)
print(mask)
X[~mask] = value
return X
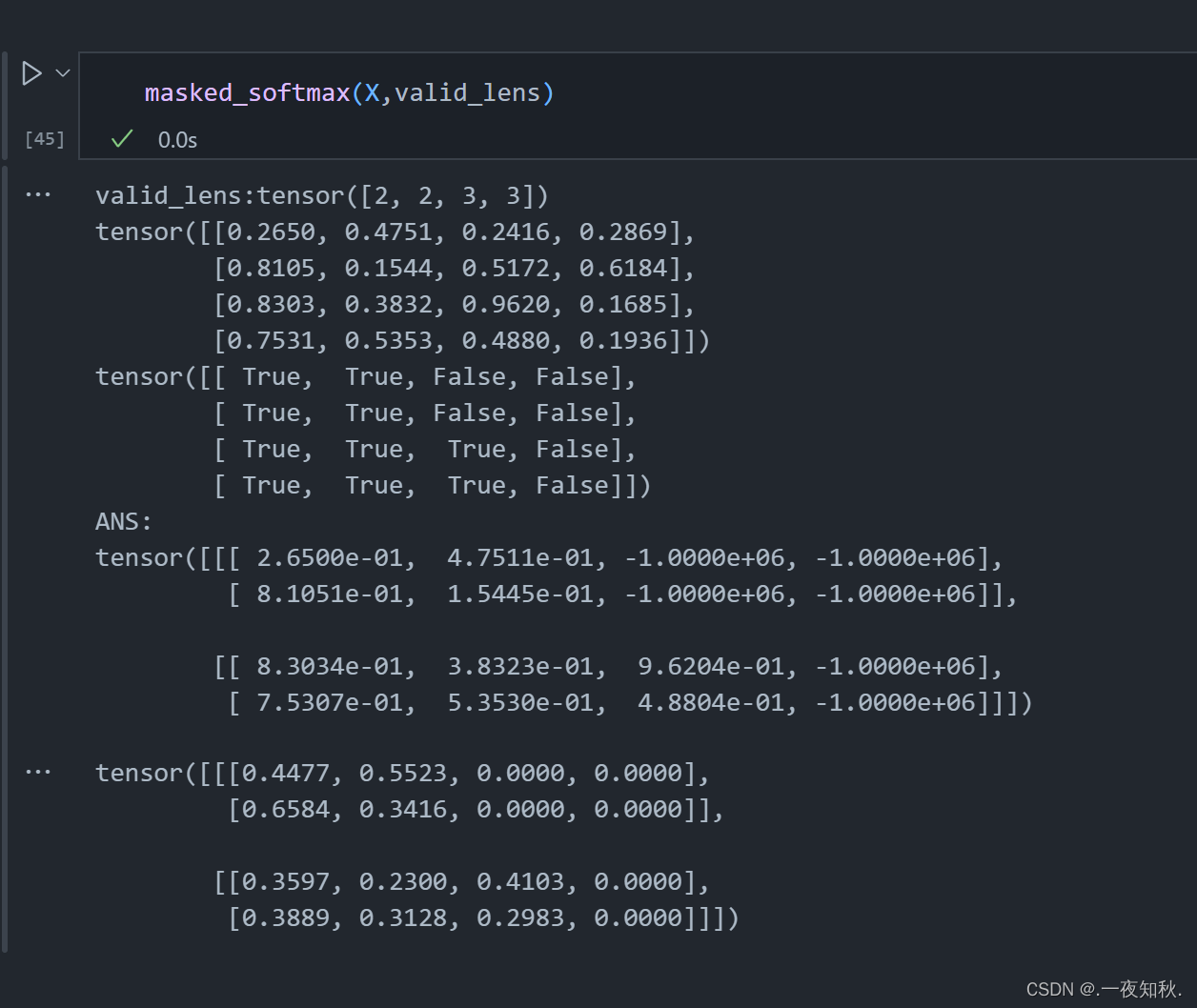
def masked_softmax(X,valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
# X:3D张量,valid_lens:1D或2D张量
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
print(f"valid_lens:{valid_lens}")
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = sequence_mask(X.reshape(-1,shape[-1]), valid_lens, value=-1e6)
print(f"ANS:")
print(f"{X.reshape(shape)}")
return nn.functional.softmax(X.reshape(shape),dim=-1)
缩放点积注意力
#缩放点击注意力
class DotProductAttention(nn.Module):
def __init__(self, dropout,**kwargs):
super(DotProductAttention,self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# queries的形状:(batch_size,查询的个数,d)
# keys的形状:(batch_size,“键-值”对的个数,d)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
# 设置transpose_b=True为了交换keys的最后两个维度
scores = torch.bmm(queries,keys.transpose(1,2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores,valid_lens)
return torch.bmm(self.dropout(self.attention_weights),values)
这里主要是forward中,torch.bmm用于执行批量矩阵乘法,transpose是将查询张量与键张量的转置相乘,最后生成注意力分数张量。
关于sqrt(d):
如果d不是很大的话,除不除都没关系,但是如果d很大的话(两个向量很长),点积之后的数值可能会很大或很小,这就导致很大的数值softmax后更加靠近于1,而同时剩下的数值会趋近于0,也就是数值们会向两端靠拢,这会导致我们算梯度的时候梯度变小,所以对d开根号
--未完待续,先去读论文了,后面再写



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











