




Redis简介
Redis 拥有高性能的数据读写功能,被我们广泛用在缓存场景,一是能提高业务系统的性能,二是为数据库抵挡了高并发的流量请求。
把 Redis 作为缓存组件,需要防止出现以下问题,否则可能会造成生产事故。
- Redis 缓存满了
- 缓存穿透、缓存击穿、缓存雪崩
- Redis 数据过期了
- Redis 突然变慢了
- Redis 与 MySQL 数据一致性问题
在本文正式开始之前,需要大家先取得以下两点共识:
- 缓存必须要有过期时间;
- 保证数据库跟缓存的最终一致性即可,不必追求强一致性。
什么是数据库与缓存一致性?
数据一致性指的是:
- 缓存中存有数据,缓存的数据值 = 数据库中的值;
- 缓存中没有该数据,数据库中的值 = 最新值。
反推缓存与数据库不一致:
- 缓存的数据值 ≠ 数据库中的值;
- 缓存或者数据库存在旧的数据,导致线程读取到旧数据。
为何会出现数据一致性问题呢?
把 Redis 作为缓存的时候,当数据发生改变我们需要双写来保证缓存与数据库的数据一致性。
数据库跟缓存毕竟是两套系统,如果要保证强一致性,势必要引入 2PC 或 Paxos 等分布式一致性协议,或者分布式锁等等。这个在实现上是有难度的,而且一定会对性能有影响。
如果真的对数据的一致性要求这么高,那引入缓存是否真的有必要呢?
缓存的使用策略
在使用缓存时,通常有以下几种缓存使用策略用于提升系统性能:
- Cache-Aside 模式(旁路缓存,业务系统常用)
- Read-Through 模式(直读)
- Write-Through 模式(同步直写)
- Write-Behind 模式
Cache-Aside (旁路缓存)
所谓「旁路缓存」,就是读取缓存、读取数据库和更新缓存的操作都在应用系统来完成,业务系统最常用的缓存策略。
读取数据
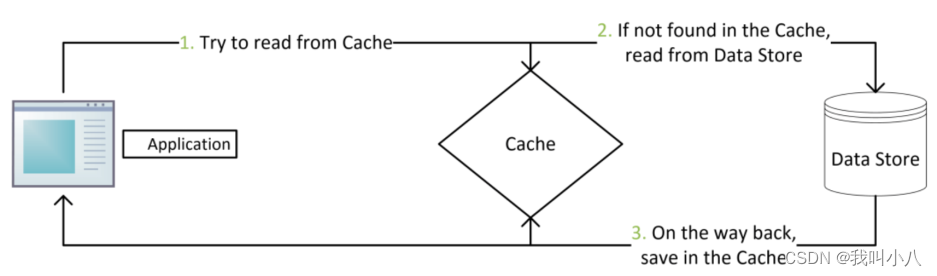
读取数据逻辑如下:
- 当应用程序需要从数据库读取数据时,先检查缓存数据是否命中;
- 如果缓存未命中,则查询数据库获取数据。同时将数据写到缓存中,以便后续读取相同数据会命中缓存。最后再把数据返回给调用者;
- 如果缓存命中,直接返回。
时序图如下:
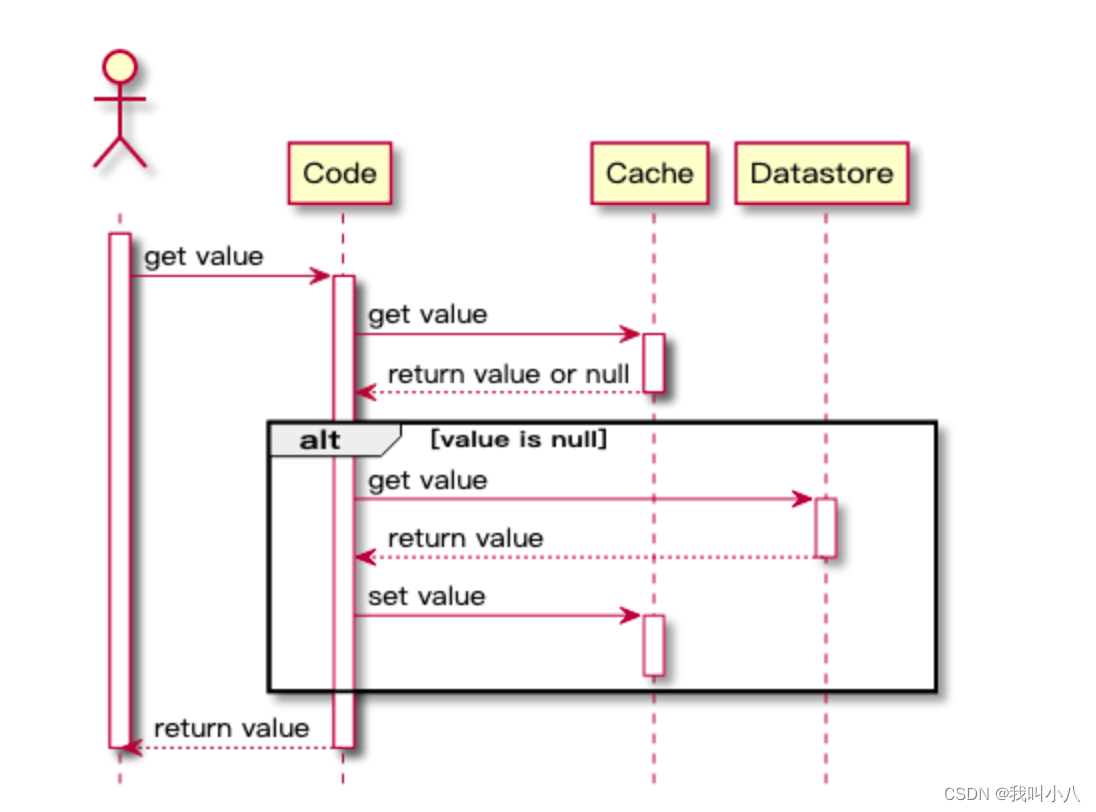
优点
- 缓存中仅包含应用程序实际请求的数据,有助于保持缓存大小的成本效益;
- 实现简单,并且能获得性能提升。
缺点
由于数据仅在缓存未命中后才加载到缓存中,因此初次调用的数据请求响应时间会增加一些开销,因为需要额外的缓存填充和数据库查询耗时。
更新数据
使用 cache-aside 模式写数据时,如下流程。
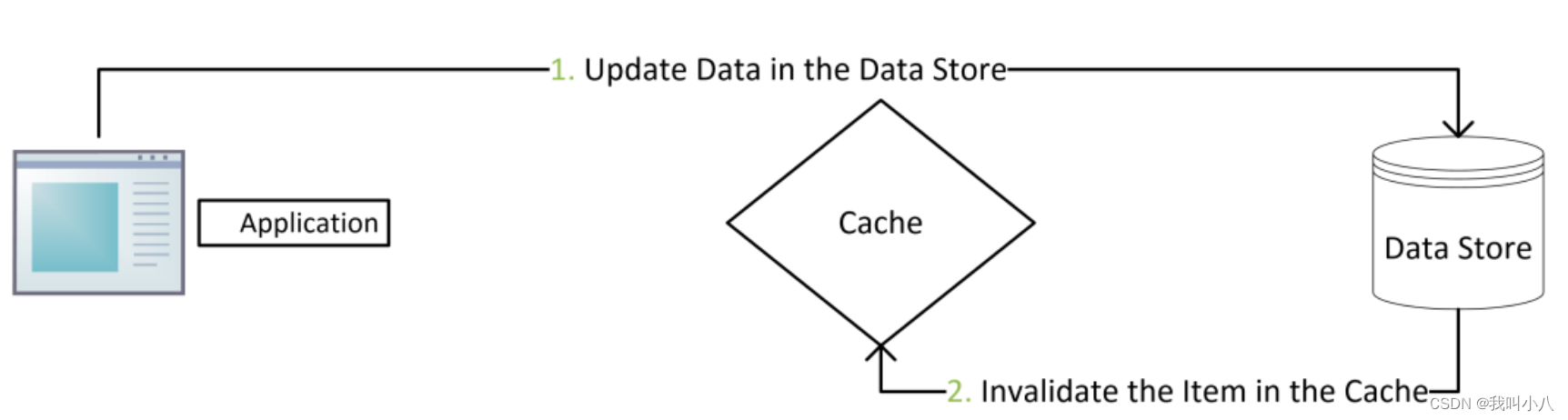
- 写数据到数据库;
- 将缓存中的数据失效或者更新缓存数据。
使用 cache-aside 时,最常见的写入策略是直接将数据写入数据库,但是缓存可能会与数据库不一致。
我们应该给缓存设置一个过期时间,这个是保证最终一致性的解决方案。
如果过期时间太短,应用程序会不断地从数据库中查询数据。同样,如果过期时间过长,并且更新时没有使缓存失效,缓存的数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6447
6447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











