







 本文详细介绍了Linux中的基本I/O原理,包括用户态与内核态的区别,以及BIO、NIO和EPOLL三种I/O模型的工作机制。BIO是阻塞I/O,每次循环处理多个文件描述符,而NIO引入了I/O多路复用,通过select、poll或epoll系统调用来监听多个fd。其中,epoll使用红黑树和事件驱动,提供更高的效率和无限制的连接数。总结了select、poll和epoll在操作方式、底层实现、IO效率和最大连接数等方面的比较。
本文详细介绍了Linux中的基本I/O原理,包括用户态与内核态的区别,以及BIO、NIO和EPOLL三种I/O模型的工作机制。BIO是阻塞I/O,每次循环处理多个文件描述符,而NIO引入了I/O多路复用,通过select、poll或epoll系统调用来监听多个fd。其中,epoll使用红黑树和事件驱动,提供更高的效率和无限制的连接数。总结了select、poll和epoll在操作方式、底层实现、IO效率和最大连接数等方面的比较。
基本io原理
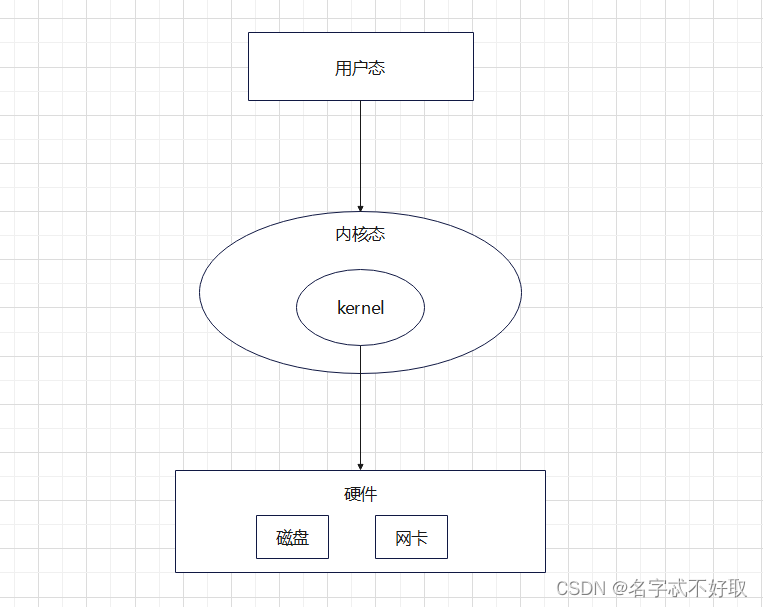
linux操作系统分为用户态和内核态
用户态
用户程序运行在用户态,用户态下有许多限制。比如无法直接操作硬件、创建和切换线程、开辟内存等操作(安全),这些操作都需要通过内核态完成
内核态
可直接操作系统硬件资源等,用户态可通过系统调用转换为用户态。比如用户态的io操作、切换线程都是通过系统调用进入内核态通过kernel(内核)完成的
linux中进入内核态的几种方式:系统调用、中断、异常
BIO
顾名思义是阻塞的,比如有100个fd,用户程序会一直循环掉系统调用read() 100个fd就会调用100个read系统调用,并且read还是阻塞的
NIO
补充:网络io中客户端与服务器两端都是通过socket进行连接的,socket在linux操作系统中有对应的文件描述符(fd),我们的读写操作都是以该文件描述符为单位进行操作的。
每次循环遍历都进行读写操作,我们以读操作为例:大部分读操作都是在数据没有准备好的情况下进行读的,相当于执行了一次空操作。我们要想办法避免这种无效的读取操作,避免内核态和用户态之间的频繁切换。
所谓I/O多路复用指的是这样一个过程:
1、我们拿到了一堆文件描述符(不管是网络相关的、还是磁盘文件相关等等,任何文件描述符都可以)
2、通过调用某个函数告诉内核:“这个函数你先不要返回,你替我监视着这些描述符,
3、当这堆文件描述符中有可以进行I/O读写操作的时候你再返回”当调用的这个函数返回后我们就能知道哪些文件描述符可以进行I/O操作了。
select / epoll
它的模式是这样的:程序端每次把文件描述符集合交给select的系统调用,select遍历每个文件描述符后返回那些可以操作的文件描述符,然后程序再次遍历可以操作的文件描述符进行读写。
缺点
select 使用固定长度的 BitsMap,表示文件描述符集合
一次传输的文件描述符集合有限,只能给出1024个文件描述符(32位机),poll在此基础上进行了改进,没有了文件描述符数量的限制。
poll中文件描述符集合没有限制
poll以链表来存储文件描述符集合
select和poll弊端
1、它们需要在内核中对所有传入的文件描述符进行遍历,这也是一项比较耗时的操作
2、(这点是否存在优化空间有待考证)每次要把文件描述符从用户态的内存搬运到内核态的内存,遍历完成后再搬回去,这个来回复制也是一项耗时的操纵。
和bio的区别
bio如果有100个fd,就会调用100次系统调用;nio一次系统调用把fd集合传到内核
nio不会阻塞
epoll
epoll首先是在内核中维护了一个红黑树,以及一些链表结构,当数据到达网卡拷贝到内存时会把相应的文件描述符从红黑树中拷贝到链表中,这样链表存储的就是已经有数据到达的文件描述符,这样当程序调用epoll_wait的时候就能直接把能读的文件描述符返回给应用程序
第一点,epoll 在内核里使用红黑树来跟踪进程所有待检测的文件描述字,把需要监控的 socket 通过 epoll_ctl() 函数加入内核中的红黑树里,红黑树是个高效的数据结构,增删查一般时间复杂度是 O(logn),通过对这棵黑红树进行操作,这样就不需要像 select/poll 每次操作时都传入整个 socket 集合,只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。
第二点, epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中,当用户调用 epoll_wait() 函数时,只会返回有事件发生的文件描述符,不需要像 select/poll 那样轮询扫描整个 socket 集合,大大提高了检测的效率。
select、poll、epoll比较
| select | poll | epoll | |
|---|---|---|---|
| 操作方式 | 遍历 | 遍历 | 回调 |
| 底层实现 | 数组 | 链表 | 红黑树、链表 |
| IO效率 | 每次调用都进行线性遍历,时间复杂度为O(n) | 每次调用都进行线性遍历,时间复杂度为O(n) | 事件通知方式,每当fd就绪,系统注册的回调函数就会被调用,将就绪fd放到链表里面,时间复杂度O(1) |
| 最大连接数 | 1024(x86)或2048(x64) | 无上限 | 无上限 |
| fd拷贝 | 每次调用select,都需要把fd集合从用户态拷贝到内核态,再拷贝回用户态 | 每次调用poll,都需要把fd集合从用户态拷贝到内核态,再拷贝回用户态 | 调用epoll_ctl时拷贝进内核并保存,之后每次epoll_wait不拷贝 |

















 503
503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









