







二次排序
简单理解,就是先对第一个字段进行排序,如果第一个字段相相等,按照第二个字段排序
案例
对下面的数据进行二次排序
aa 78
bb 98
aa 80
cc 98
aa 69
cc 87
bb 97
cc 86
aa 97
bb 78
bb 34
cc 85
bb 92
cc 72
bb 32
bb 23
代码实现
实现思路
1:读取数据
2:每一行为一个二元组
3:根据key分组,合并value
4:对value进行排序
5:输出结果,一个key,对应一个排序完成的value集合
具体实现
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkAppTemplate {
//scala程序的入口,也是spark application运行Driver
def main(args: Array[String]): Unit = {
//Spark app 配置:应用的名字和Master运行的位置
val sparkConf = new SparkConf()
.setAppName("SparkAppTemplate")
.setMaster("local[2]")
//创建sparkContext对象:主要用于读取需要处理的数据,封装在RDD集合中;调度jobs执行
val sc = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
//第一步:数据的读取(输入)
//每行数据有2列,2个字段之间用空格分割的
// aa 98
val inputRDD: RDD[String] = sc.textFile("file:///E:\\JavaWork\\20190803")
//第二步:数据的处理(分析)
val lines = inputRDD.map(item=>{
val arrs = item.split(" ")
val value = arrs(1).toInt
(arrs(0),value)
})
val second: RDD[(String, Iterable[Int])] = lines.groupByKey()
val third1 = second.map {
case (key: String, values: Iterable[Int]) => {
val comp: List[Int] = values.toList.sortWith(_ > _)
var count = 0
while (count < comp.length){
println(key,comp(count))
count += 1
}
}
}
//第三步:数据的输出(输出)
third1.collect()
//开发测试的时候,为了对每个spark app页面监控查看job的执行情况,
//spark app运行结束4040端口就没了
//关闭资源
sc.stop()
}
}
运行结果
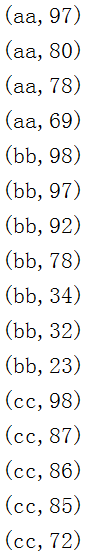
解决数据倾斜问题
建立在上一个案例中,如果数据(aa,value)有100万行
那么执行bb,cc的节点可以很快的跑完任务,而执行aa的节点的任务将会很繁重
整个任务的完成时间将会延长,尽管还有几个“闲人”
解决思路
第一个阶段:局部聚合
在key上添加指定返回的随机数
第二个阶段:
将key前缀随机数给删除
具体实现
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.util.Random
object SparkGroupSortSkewData {
//scala程序的入口,也是spark application运行Driver
def main(args: Array[String]): Unit = {
//Spark app 配置:应用的名字和Master运行的位置
val sparkConf = new SparkConf()
.setAppName("B_SparkGroupSortSkewData")
.setMaster("local[2]")
//创建sparkContext对象:主要用于读取需要处理的数据,封装在RDD集合中;调度jobs执行
val sc = new SparkContext(sparkConf)
//第一步:数据的读取(输入)
//每行数据有2列,2个字段之间用空格分割的
// aa 98
val inputRDD: RDD[String] = sc.textFile("file:///I:/group.data")
//第二步:数据的处理(分析)
//(1)提前字段 (key,value) map
//(2)按照key分组(key,Iterable[Int]) groupbyKey
//(3)遍历所有key,将对应的值进行排序 map
val resultRDD: RDD[(String, List[Int])] = inputRDD
.map(line =>{
val arr = line.trim.split(" ")
(arr(0),arr(1).toInt)
})
//在聚合之前添加随机值
.map(tuple=>{
val random = new Random()
(random.nextInt(2)+"_"+tuple._1,tuple._2)
})
.groupByKey() //RDD[(String, Iterable[Int])]
//先进行一次排序
.map{
case (key:String,iter:Iterable[Int])=>{
val sortedList = iter.toList.sortBy(-_)
(key,sortedList)
}
}
//第二个阶段聚合,去除随机数
.map{ case(key,iter) =>{(key.split("_")(1),iter)}}
.groupByKey()
.map{
case (key,iter)=>{
//再次排序
val sotredList = iter.flatMap(x => x.toList).toList.sorted.reverse
(key,sotredList)
}
}
//第三步:数据的输出(输出)
resultRDD.foreach(tuple2=>{
println(s"${tuple2._1},${tuple2._2.mkString(",")}")
})
//开发测试的时候,为了对每个spark app页面监控查看job的执行情况,
//spark app运行结束4040端口就没了
//关闭资源
sc.stop()
}
}
运行结果
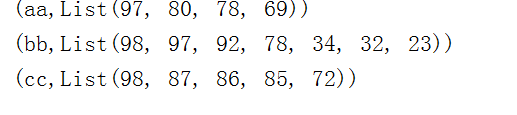
Spark性能优化
以上面的案例为例
可以发现,在任务的两个大的阶段都进行了两次map操作
而且这两个map的操作还是相邻的,那么是否可以将这两个map合并为一个map
答案是可以的
具体实现
package com.huadian.bigdata.spark.groupsort
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.util.Random
/**
* Spark Application开发模板
*/
object SparkGroupSortSkewData {
//scala程序的入口,也是spark application运行Driver
def main(args: Array[String]): Unit = {
//Spark app 配置:应用的名字和Master运行的位置
val sparkConf = new SparkConf()
.setAppName("SparkAppTemplate")
.setMaster("local[2]")
//创建sparkContext对象:主要用于读取需要处理的数据,封装在RDD集合中;调度jobs执行
val sc = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
//第一步:数据的读取(输入)
//每行数据有2列,2个字段之间用空格分割的
// aa 98
val inputRDD: RDD[String] = sc.textFile("file:///E:\\JavaWork\\20190803")
//第二步:数据的处理(分析)
val lines = inputRDD
.map(item=>{
val arrs = item.split(" ")
val value = arrs(1).toInt
val random = new Random()
(random.nextInt(2)+"_"+arrs(0),value)
})
.groupByKey()
.map {
case (key: String, values: Iterable[Int]) => {
val comp: List[Int] = values.toList.sortWith(_ > _).take(3)
(key.split("_")(1),comp)
}
}
.groupByKey()
.map{
case (key,iter)=>{
val sortedList= iter.flatMap(x=>x.toList).toList.sorted.reverse.take(3)
(key,sortedList)
}
}
//第三步:数据的输出(输出)
println("----------------------------------")
lines.collect().foreach(println)
//开发测试的时候,为了对每个spark app页面监控查看job的执行情况,
//spark app运行结束4040端口就没了
//关闭资源
sc.stop()
}
}
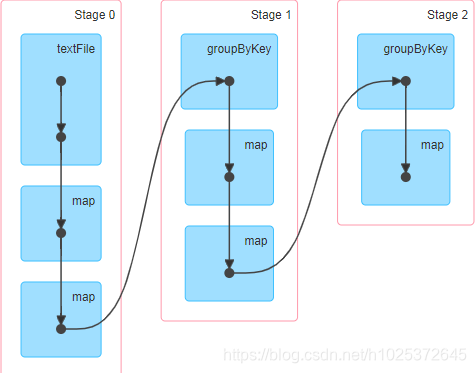
优化前后阶段对比对比
优化前
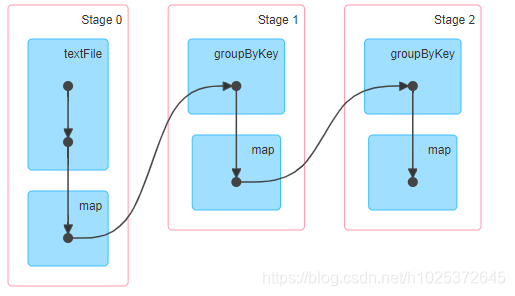
优化后
再次优化Spark性能
针对上面的案例,还可以再次进行优化
针对的点主要是groupByKey操作
查看groupByKey是如何实现的时候
可以看到这样一个函数aggregateByKey
越是接近底层的函数,效率越高
使用aggregateByKey

具体实现
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
object SparkAppTemplate {
//scala程序的入口,也是spark application运行Driver
def main(args: Array[String]): Unit = {
//Spark app 配置:应用的名字和Master运行的位置
val sparkConf = new SparkConf()
.setAppName("SparkAppTemplate3")
.setMaster("local[2]")
//创建sparkContext对象:主要用于读取需要处理的数据,封装在RDD集合中;调度jobs执行
val sc = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
//第一步:数据的读取(输入)
//每行数据有2列,2个字段之间用空格分割的
// aa 98
val inputRDD: RDD[String] = sc.textFile("file:///E:\\JavaWork\\20190803")
//第二步:数据的处理(分析)
val lines = inputRDD.map(item=>{
val arrs = item.split(" ")
val value = arrs(1).toInt
(arrs(0),value)
})
.aggregateByKey(ListBuffer[Int]())(
(u,v)=>{
u += v
u.sortBy(- _).take(3)
},
(u1,u2)=>{
u1 ++= u2
u1.sortBy(- _).take(3)
}
)
lines.coalesce(1).foreachPartition(_.foreach(println))
//第三步:数据的输出(输出)
//开发测试的时候,为了对每个spark app页面监控查看job的执行情况,
//spark app运行结束4040端口就没了
//关闭资源
sc.stop()
}
}
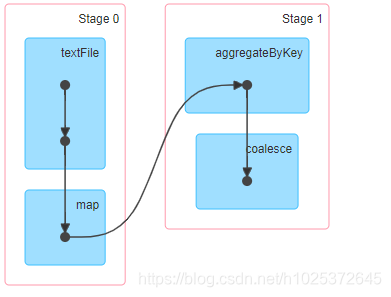
优化效果
优化程度是相当大的



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











