







引言
MTD(memory technology device内存技术设备)是用于访问memory设备(RAM、ROM、flash)的Linux的子系统。MTD的主要目的是为了使新的memory设备的驱动更加简单,为此它在硬件和上层之间提供了一个抽象的接口。MTD主要就是为Nor Flash和Nand Flash设计的,其余像接口映射、RAM、ROM等都是辅助功能
MTD设备通常可分为四层,从上到下依次是:设备节点、MTD设备层、MTD原始设备层、硬件驱动层。其框图如下图所示:
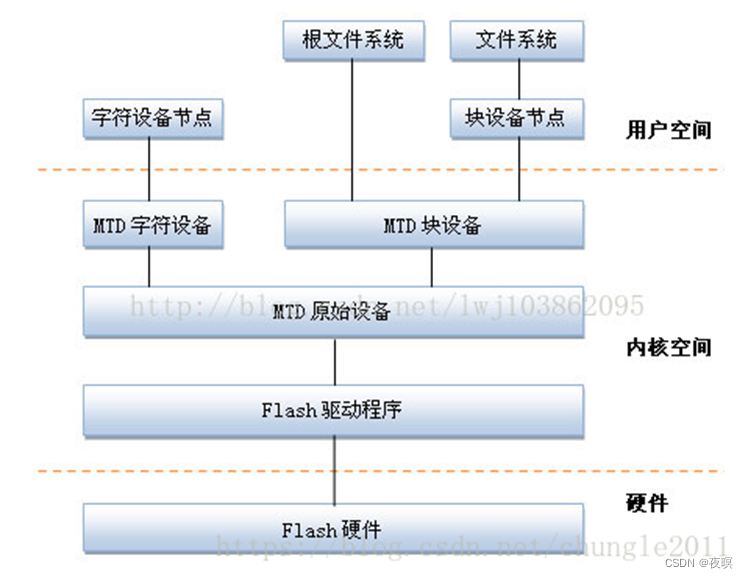
设备节点:在/dev子目录下建立MTD块设备节点(主设备号为31)和MTD字符设备节点(主设备号为90),通过访问此设备节点即可访问MTD字符设备和块设备
MTD设备层:基于MTD原始设备,linux系统可以定义出MTD的块设备(主设备号31)和字符设备(设备号90)
- mtdchar.c : MTD字符设备接口相关实现
- mtdblock.c : MTD块设备接口相关实现
MTD原始设备层:用于描述MTD原始设备的数据结构是mtd_info,它定义了大量的关于MTD的数据和操作函数
- mtdcore.c : MTD原始设备接口相关实现
- mtdpart.c : MTD分区接口相关实现
硬件驱动层:Flash硬件驱动层负责对Flash硬件的读、写和擦除操作。MTD设备的Nand Flash芯片的驱动则drivers/mtd/nand/子目录下,Nor Flash芯片驱动位于drivers/mtd/chips/子目录下
- drivers/mtd/chips : CFI/JEDEC接口通用驱动
- drivers/mtd/nand : NAND通用驱动和部分底层驱动程序
- drivers/mtd/maps : NOR Flash映射关系相关函数
- drivers/mtd/devices : NOR Flash底层驱动
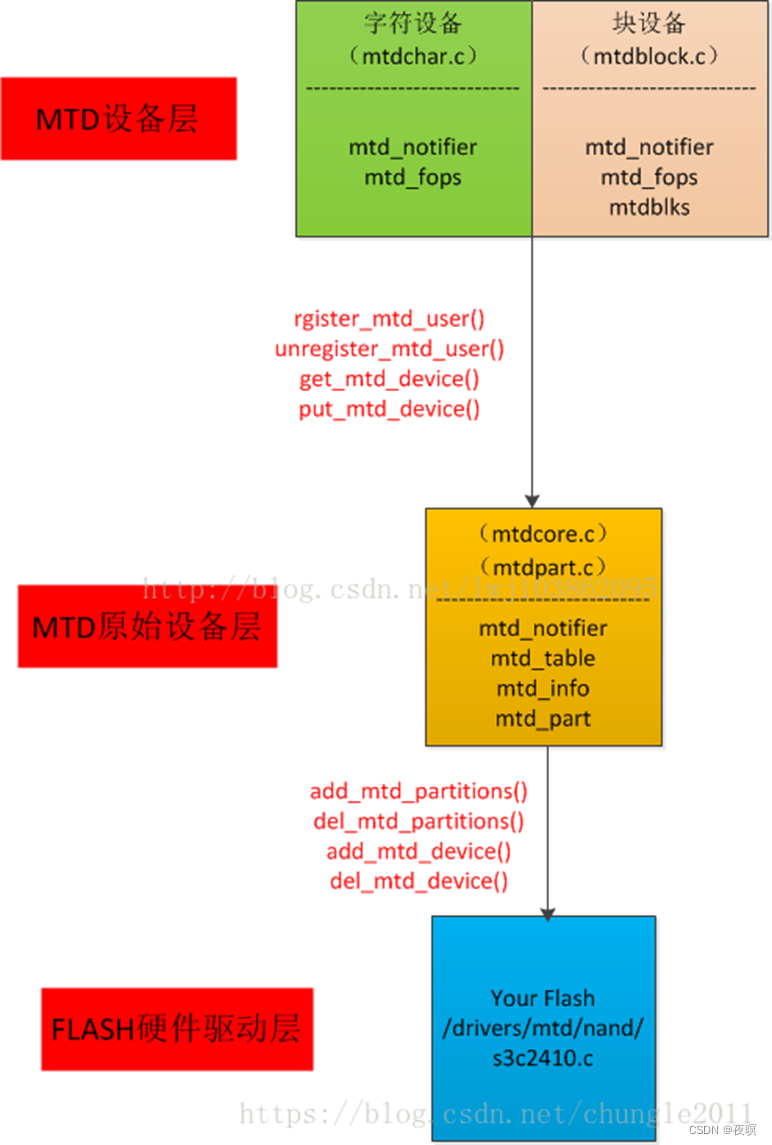
文件系统基于mtd原始设备层,直接调用mtd相关接口读写。向上提供接口给VFS,VFS调用设备节点或直接文件系统自身完成。MTD是一个承上启下的重要中间层
OOB简介
Nand Flash,每一个页,对应一个空闲区域(OOB),这个区域是基于Nand Flash的硬件特性,数据在读写的时候容易出错,为了保证数据的正确性,就产生了这样一个检测和纠错的区域,用来放置数据的校验值。OOB的读写操作,一般都是随着页的操作一起完成,也就是在读写页的时候,对应的OOB就产生了
目前比较常见NAND Flash每一页大小为(2048+64)字节(还有其他格式的NANDFlash,比如每页大小为(256+8)、(512+16)、(2048+128)等),其中的2048字节就是一般存储数据的区域,64字节称为OOB(Out OfBand)区。
标记是否存在坏块
为什么会出现坏块?由于NAND Flash的工艺不能保证NAND的Memory Array在其生命周期中保持性能的可靠,因此,在NAND的生产中及使用过程中会产生坏块。坏块的特性是:当编程/擦除这个块时,会造成Page Program和Block Erase操作时的错误,相应地反映到Status Register的相应位。
坏块的分类
总体上,坏块可以分为两大类:
(1)固有坏块:这是生产过程中产生的坏块,一般芯片原厂都会在出厂时都会将每个坏块第一个page的oob的第6个byte标记为不等于0xff的 值。
(2)使用坏块:这是在NAND Flash使用过程中,如果Block Erase或者Page Program错误,就可以简单地将这个块作为坏块来处理,这个时候需要把坏块标记起来。为了和固有坏块信息保持一致,将新发现的坏块的第一个page的 oob的第6个Byte标记为非0xff的值。
坏块管理
根据上面的这些叙述,可以了解NAND Flash出厂时在spare area中已经反映出了坏块信息,因此,如果在擦除一个块之前,一定要先check一下第一页的oob的第6个byte是否是0xff,如果是就证明这是一个好块,可以擦除;如果是非0xff,那么就不能擦除,以免将坏块标记擦掉。 当然,这样处理可能会犯一个错误―――“错杀伪坏块”,因为在芯片操作过程中可能由于 电压不稳定等偶然因素会造成NAND操作的错误。但是,为了数据的可靠性及软件设计的简单化,还是需要遵照这个标准。
坏块处理
使用过程中产生的坏块,就需要将这个块作为坏块来处理,为了与固有的坏块信息保持一致,也需要将新发现的坏块的第一个page的oob的第6个Byte标记为非0xff的值。
可以用BBT:bad block table,即坏块表来进行管理。各家对nand的坏块管理方法都有差异。比如专门用nand做存储的,会把bbt放到block0,因为第0块一定是好的块。但是如果nand本身被用来boot,那么第0块就要存放程序,不能放bbt了。 有的把bbt放到最后一块,当然,这一块坚决不能为坏块。 bbt的大小跟nand大小有关,nand越大,需要的bbt也就越大。
存储ECC校验
ECC(Error Checking and Correction),是一种用于Nand Flash的差错检测和修正的算法。由于操作的时序和电路稳定性等原因,常常会出现一些bit出错,也就是原来的某个位,本来是0而变成了1,或者本来是1而变成0。从现象来看,问题其实看起来并不是特别的严重,但是如果恰好某个重要的文件的某一位发生了变化,那么问题就大了,可能会导致此时文件不能运行,如果这个文件是一个影响系统的程序,那么直接将导致系统会出现问题,所以对于Nand Flash就出现了这样一个机制。它能纠正1个bit的错误和检测出2个bit的错误,对于1bit以上的错误无法纠正,而对于2bit以上的错误不能保证能检测。对于ECC其纠错算法是什么样的呢?
- 当往Nand Flash写入数据时候,每256个字节生成一个ECC校验,针对这些数据会生成一个ECC校验码,然后保存到对应的page的OOB数据区。
- 当读取Nand Flash的数据时候,每256个字节就会生成一个ECC校验,那么对于这些数据就会计算出一个ECC校验码,然后将从OOB中读取存储的ECC校验和计算的ECC校验想比较
MTD关键结构
struct mtd_info {
u_char type; /* MTD类型,包括MTD_NORFLASH,MTD_NANDFLASH等(可参考mtd-abi.h) */
uint32_t flags; /* MTD属性标志,MTD_WRITEABLE,MTD_NO_ERASE等(可参考mtd-abi.h) */
uint64_t size; /* mtd设备的大小 */
uint32_t erasesize; /* MTD设备的擦除单元大小,对于NandFlash来说就是Block的大小 */
uint32_t writesize; /* 写大小, 对于norFlash是字节,对nandFlash为一页 */
uint32_t writebufsize; /* MTD使用的写入缓冲区的大小。具有写入缓冲区的MTD设备可以一次写入多个writesize块。例如,当使用2*writesize字节缓冲区将4*writesize字节写入设备时,MTD驱动程序可以执行2次writesize操作,而不必执行4次。目前,所有NAND都具有与writesize(页面大小)相等的writebufsize。某些NOR的writebufsize不大于writesize。*/
uint32_t oobsize; /* OOB字节数 */
uint32_t oobavail; /* 可用的OOB字节数 */
unsigned int erasesize_shift; /* 默认为0,不重要 */
unsigned int writesize_shift; /* 默认为0,不重要 */
unsigned int erasesize_mask; /* 默认为1,不重要 */
unsigned int writesize_mask; /* 默认为1,不重要 */
const char *name;
int index;
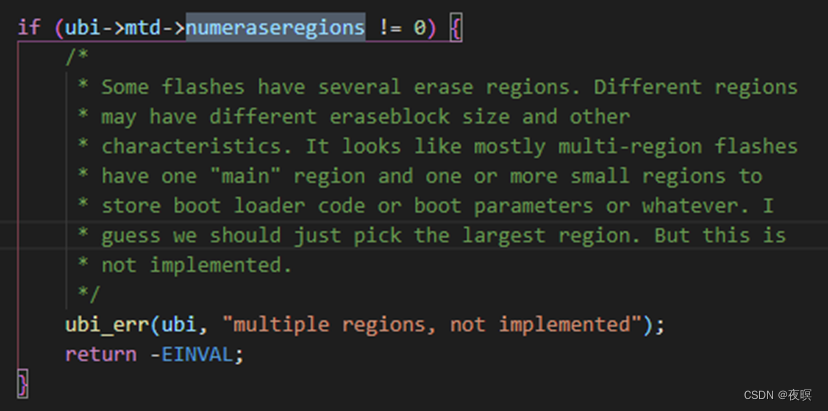
int numeraseregions; /* 通常为0 */
struct mtd_erase_region_info *eraseregions; /* 可变擦除区域 */
/* 擦除函数 */
int (*_erase) (struct mtd_info *mtd, struct erase_info *instr);
int (*_point) (struct mtd_info *mtd, loff_t from, size_t len,
size_t *retlen, void **virt, resource_size_t *phys);
int (*_unpoint) (struct mtd_info *mtd, loff_t from, size_t len);
unsigned long (*_get_unmapped_area) (struct mtd_info *mtd,
unsigned long len,
unsigned long offset,
unsigned long flags);
/* 读写flash函数 */
int (*_read) (struct mtd_info *mtd, loff_t from, size_t len,
size_t *retlen, u_char *buf);
int (*_write) (struct mtd_info *mtd, loff_t to, size_t len,
size_t *retlen, const u_char *buf);
int (*_panic_write) (struct mtd_info *mtd, loff_t to, size_t len,
size_t *retlen, const u_char *buf);
/* 带oob读写Flash函数 */
int (*_read_oob) (struct mtd_info *mtd, loff_t from,
struct mtd_oob_ops *ops);
int (*_write_oob) (struct mtd_info *mtd, loff_t to,
struct mtd_oob_ops *ops);
/* 以下函数指针主要是提供对一些保护数据的访问或正常区域的数据访问。*/
int (*_get_fact_prot_info) (struct mtd_info *mtd, size_t len,
size_t *retlen, struct otp_info *buf);
int (*_read_fact_prot_reg) (struct mtd_info *mtd, loff_t from,
size_t len, size_t *retlen, u_char *buf);
int (*_get_user_prot_info) (struct mtd_info *mtd, size_t len,
size_t *retlen, struct otp_info *buf);
int (*_read_user_prot_reg) (struct mtd_info *mtd, loff_t from,
size_t len, size_t *retlen, u_char *buf);
int (*_write_user_prot_reg) (struct mtd_info *mtd, loff_t to,
size_t len, size_t *retlen, u_char *buf);
int (*_lock_user_prot_reg) (struct mtd_info *mtd, loff_t from,
size_t len);
int (*_writev) (struct mtd_info *mtd, const struct kvec *vecs,
unsigned long count, loff_t to, size_t *retlen);
void (*_sync) (struct mtd_info *mtd);
int (*_lock) (struct mtd_info *mtd, loff_t ofs, uint64_t len);
int (*_unlock) (struct mtd_info *mtd, loff_t ofs, uint64_t len);
int (*_is_locked) (struct mtd_info *mtd, loff_t ofs, uint64_t len);
int (*_block_isreserved) (struct mtd_info *mtd, loff_t ofs);
/* 坏块管理函数 */
int (*_block_isbad) (struct mtd_info *mtd, loff_t ofs);
int (*_block_markbad) (struct mtd_info *mtd, loff_t ofs);
int (*_suspend) (struct mtd_info *mtd);
void (*_resume) (struct mtd_info *mtd);
void (*_reboot) (struct mtd_info *mtd);
/*
* If the driver is something smart, like UBI, it may need to maintain
* its own reference counting. The below functions are only for driver.
*/
int (*_get_device) (struct mtd_info *mtd);
void (*_put_device) (struct mtd_info *mtd);
/* Backing device capabilities for this device
* - provides mmap capabilities
*/
struct backing_dev_info *backing_dev_info;
struct notifier_block reboot_notifier; /* default mode before reboot */
/* ECC status information */
struct mtd_ecc_stats ecc_stats;
/* Subpage shift (NAND) */
int subpage_sft;
void *priv;
struct module *owner; /* 一般设置为THIS_MODULE */
struct device dev;
int usecount;
};
关于可变擦除区域的解释:有些flash可能具有不同块大小和其他特征,这些区别于一般块大小的区域可能用来存储引导代码或参数。即这类flash需要自行将除了主区域外的其他区域进行自行添加,即需要定义好相对MTD起始的偏移,该区域的擦除大小,有几个擦除块
struct mtd_erase_region_info {
uint64_t offset; /* At which this region starts, from the beginning of the MTD */
uint32_t erasesize; /* For this region */
uint32_t numblocks; /* Number of blocks of erasesize in this region */
unsigned long *lockmap; /* If keeping bitmap of locks */
};
另外,需要说明的是,ubi文件系统不支持flash的可变擦除块,即只能放在“主区域中”
MTD设备层
mtdchar设备
由__register_chrdev进行注册,注册名为mtd,主设备号90,操作函数如下
static const struct file_operations mtd_fops = {
.owner = THIS_MODULE,
.llseek = mtdchar_lseek,
.read = mtdchar_read,
.write = mtdchar_write,
.unlocked_ioctl = mtdchar_unlocked_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = mtdchar_compat_ioctl,
#endif
.open = mtdchar_open,
.release = mtdchar_close,
.mmap = mtdchar_mmap,
#ifndef CONFIG_MMU
.get_unmapped_area = mtdchar_get_unmapped_area,
.mmap_capabilities = mtdchar_mmap_capabilities,
#endif
};
mtdchar_open
通过get_mtd_device(NULL, devnum)传参次设备号,获取对应mtd设备(至于次设备号涉及到注册mtd设备再mtdcore中再说),然后判断mtd设备类型是否非0以及该mtd设备是否可写(不可写则无法进行open操作),最后将mtd_info这个结构体指针给到file-> private_data
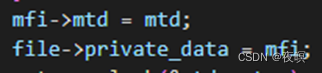
其中mfi结构体如下
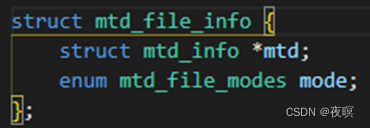
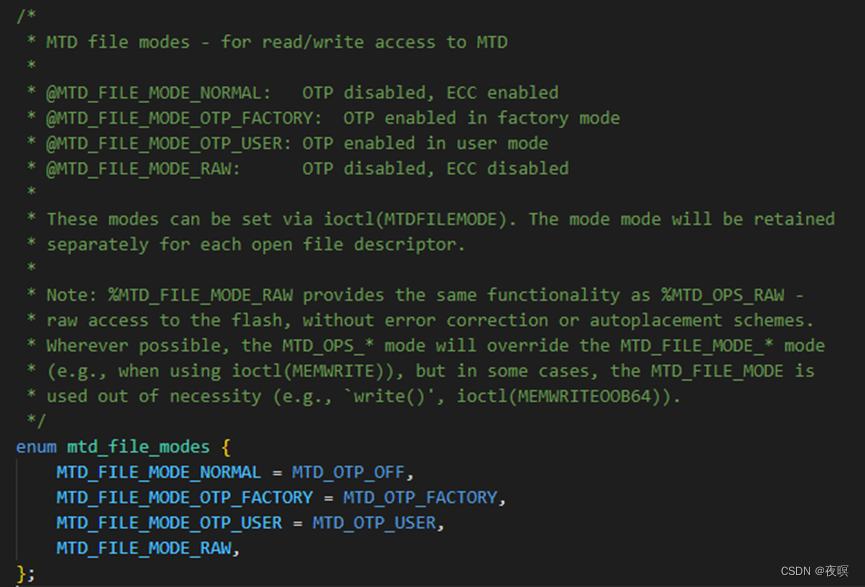
mtdchar_read(write)
读取(写入)自带长度判断,如下所示
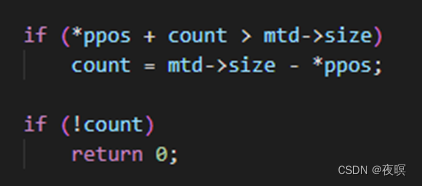
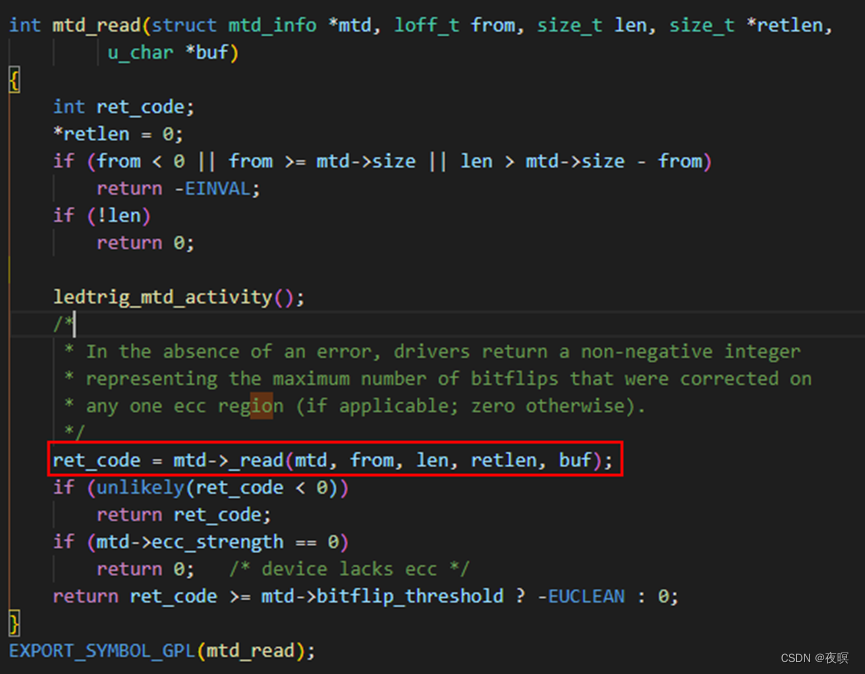
然后申请一个mtd写大小对齐的缓存,之后调用mtd_read(write),其内也自带长度校验,最后调用注册mtd设备时的真正的设备读取(写入)函数
mtdchar_ioctl
常用的几个cmd说明
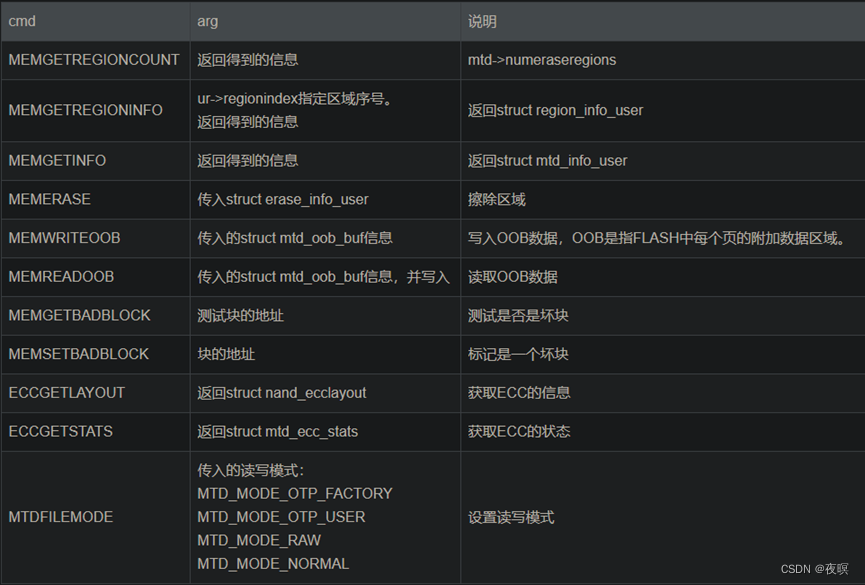
由于FLASH的擦除时间有点长、所以程序中使用了系统调度:
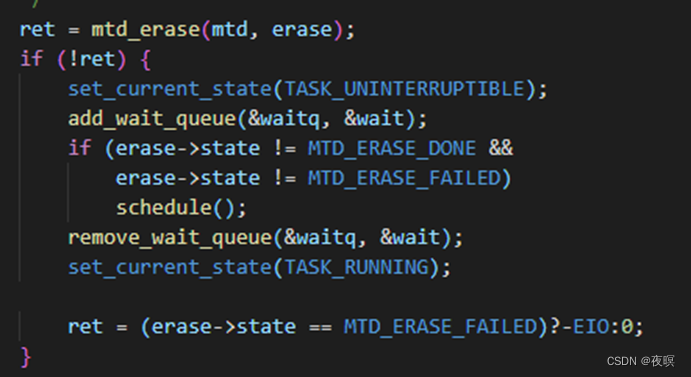
当然,如果想要使用该调度,就需要在驱动中的擦除函数做处理,先发送擦除命令,然后返回非0,在需要使用某种手段,判断出擦写已经完成,然后在调用mtd_erase_callback,告知擦除完成。
最简单的办法就是在擦除函数中不停的查询擦除有没有完成,完成后需要将erase->state置成MTD_ERASE_DONE,之后直接返回0
还有读写oob的操作通读写类似,但是会判断有oob读写函数指针是否被赋值,然后调用对应的oob操作
mtd_blkdevs设备
注册功能和函数主体如下:
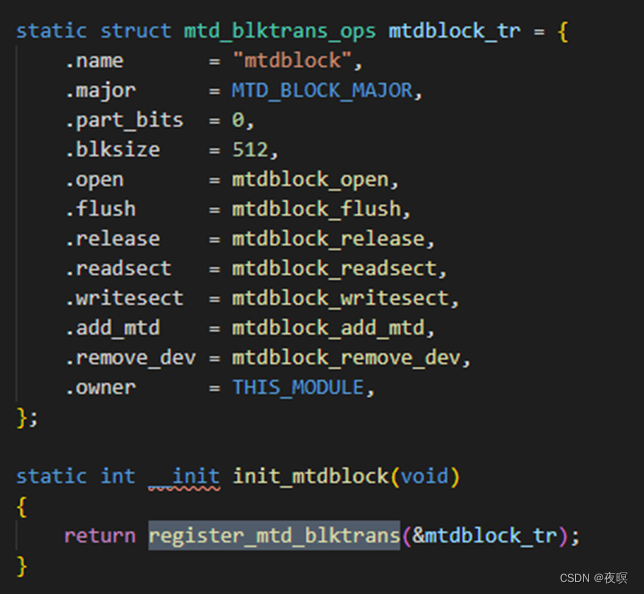
其中在register_mtd_blktrans函数中主要执行如下函数
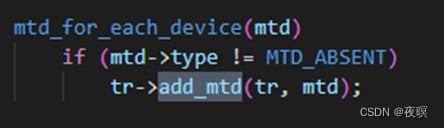
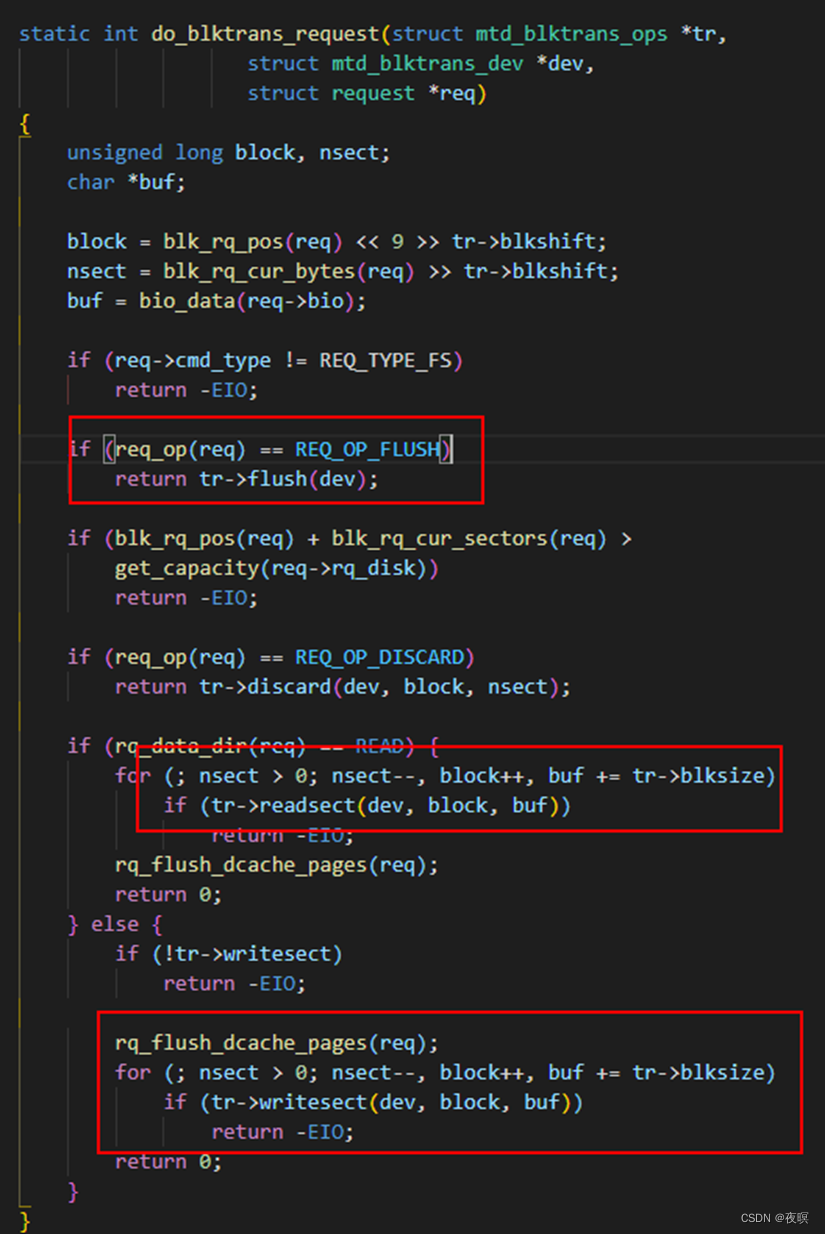
也就是将具体的块设备进行注册,其函数中mtdblock_add_mtd 调用了函数add_mtd_blktrans_dev,在该函数中注册了mtd块设备的文件操作,并建立了一个工作队列(mtd_blktrans_work -> do_blktrans_request)该队列专门用于处理该块设备的读写和同步操作。
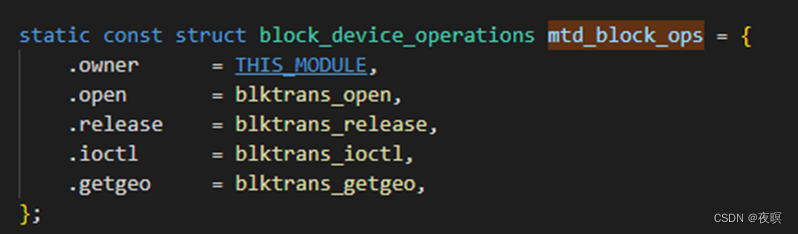
然后blktrans_open 调用 mtdblock_open,blktrans_release调用 mtdblock_release,函数 blktrans_ioctl 只实现了 flush 的操作。
mtdblock_open
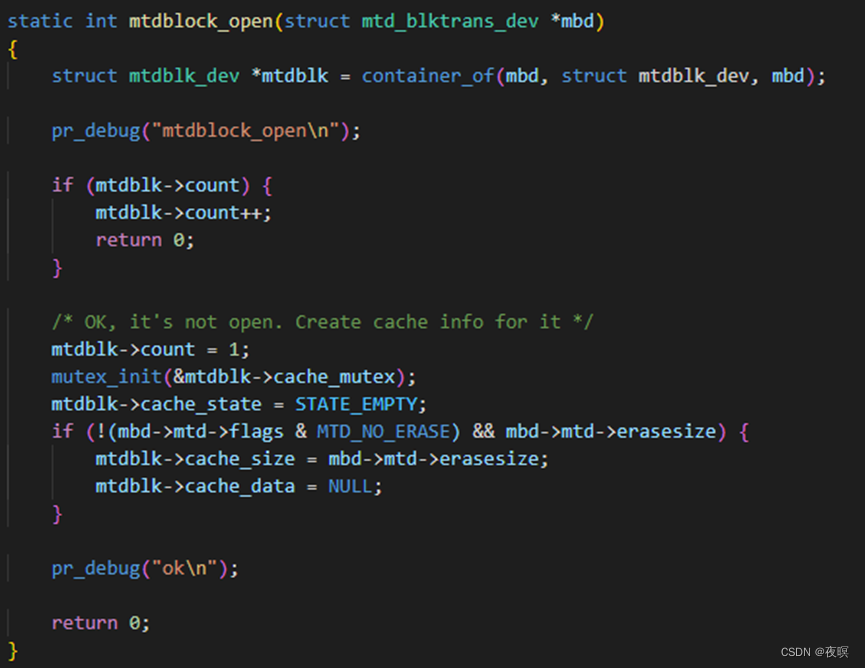
该函数很简单,就是判断有没有打开过,如果没打开,配置一些状态,需要注意的是,如果该MTD设备被标记成MTD_NO_ERASE的话,cache_size就为0,在后续的操作过程中,就不需要执行擦除操作
mtdblock_readsect(writesect)
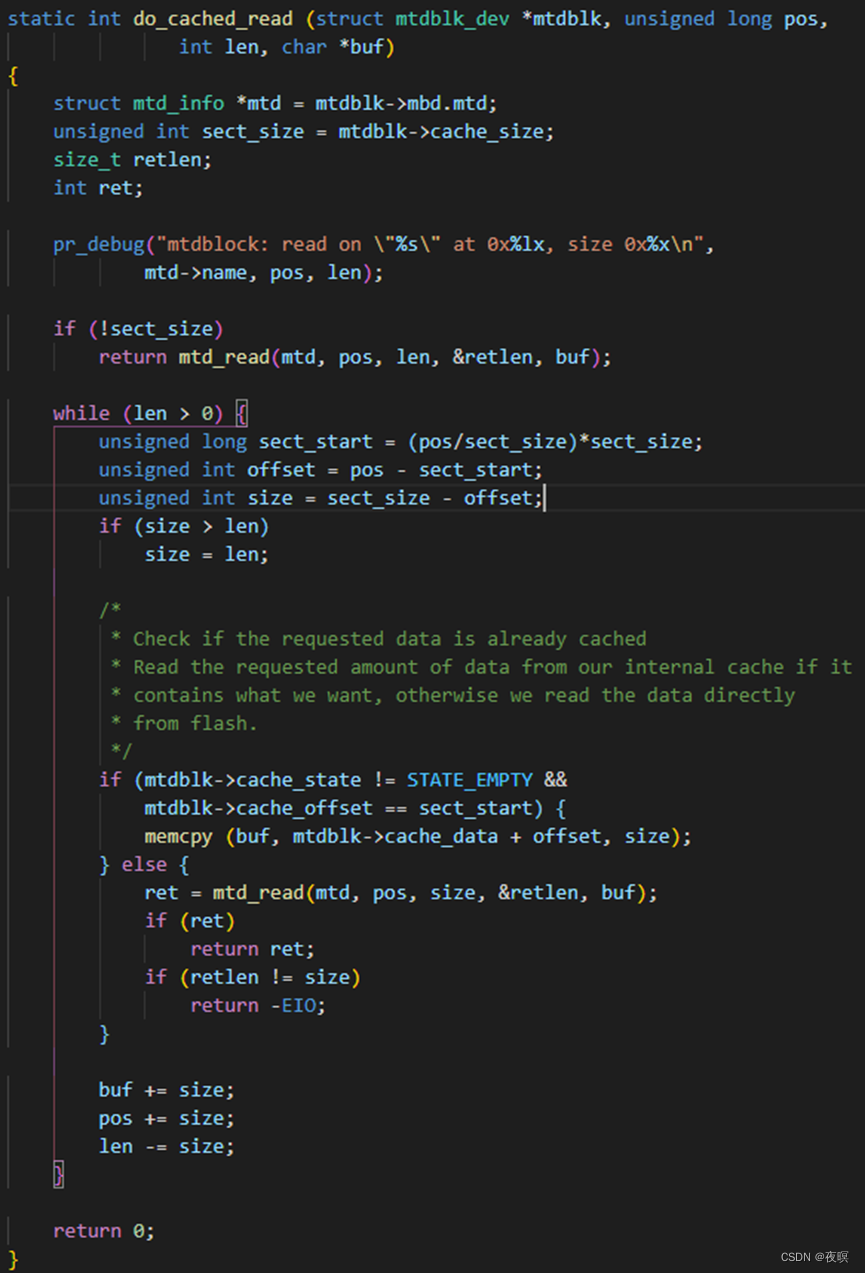
实际调用主体为do_cached_read,可以发现,如果cache如果不是空的状态(也就是之前调用过写函数),那么数据实际上是从内存中读出的,否则从mtd设备中进行读取。
写操作和读操作类似实际调用主体为do_cached_write,在调用之前会对cache_data这个指针进行vmalloc的空间申请,然后如同读取,判断sect_size如果为0则直接写入mtd设备,否则会先擦除在写入。不同于读取操作的是,如果设备需要被擦除,会先从设备中把数据读出,在擦然后再写,这里的写不一定直接写入设备中,可能是写入到cache中的,当写入cache时,state会被标记为dirty,当下次再写入该地址,被标记为dirty的数据才会写入到设备中
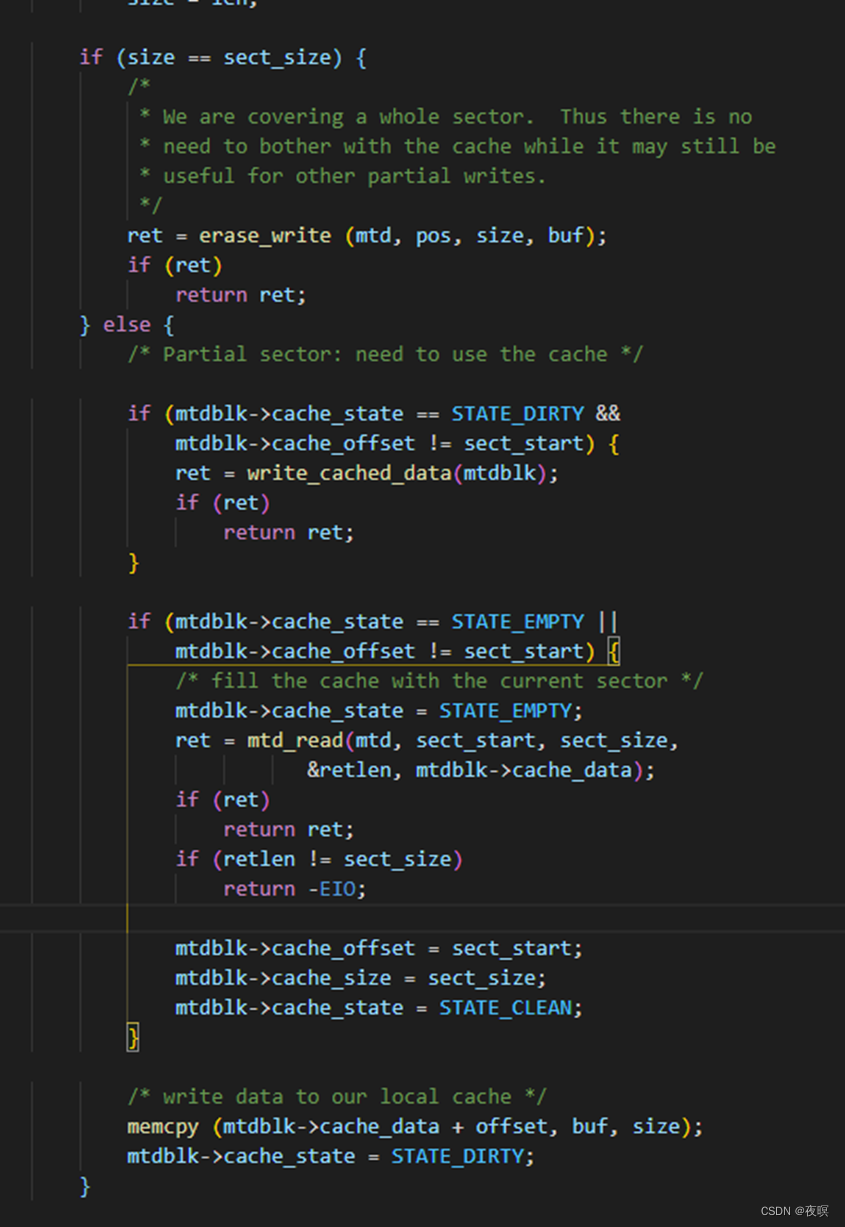
mtdblock_flush
实际上相当于ioctl,该函数实现将cache中的数据直接写入到设备中去
mtdconcat
该函数实现将多个同类型mtd设备合并成一个大分区的mtd设备,并内部计算地址偏移等,实现上层控制驱动层的简单设计,使用
MTD原始设备层
mtdcore
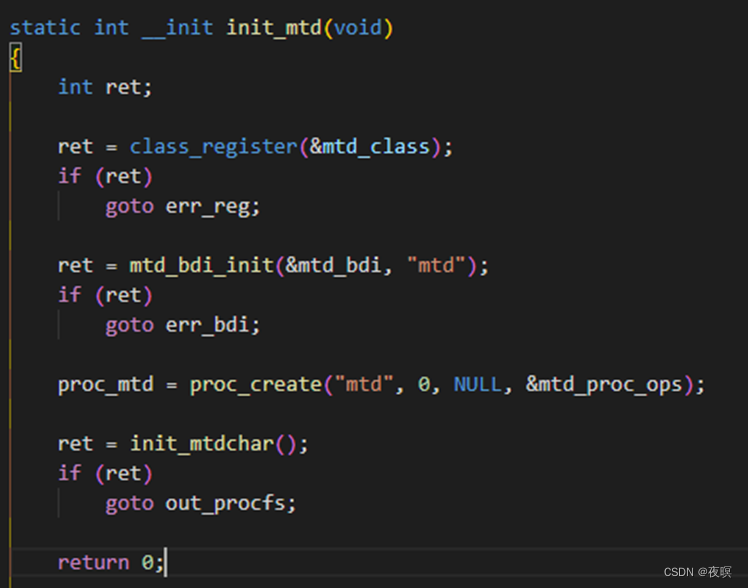
mtdcore的注册,这里注册了bdi回写机制,就是定期看cache中是否有dirty数据,进行数据写入,然后注册了一个proc文件,方便mtd设备查看,然后直接注册mtd字符设备
再mtdcore中有很多 static DEVICE_ATTR 的定义,如下所示。使用DEVICE_ATTR,可以在sys fs中添加“文件”,通过修改该文件内容,可以实现在运行过程中动态控制device的目的
DEVICE_ATTR(_name, _mode, _show, _store)
_name:名称,也就是将在sys fs中生成的文件名称。
_mode:上述文件的访问权限,与普通文件相同,UGO的格式。
_show:显示函数,cat该文件时,此函数被调用。
_store:写函数,echo内容到该文件时,此函数被调用。
add_mtd_device
mtd设备添加的核心函数,其中有设置部分默认值和某些校验,最核心部分如下,就是对mtd设备进行注册,然后再注册一个只读设备
mtd->dev.type = &mtd_devtype;
mtd->dev.class = &mtd_class;
mtd->dev.devt = MTD_DEVT(i);
dev_set_name(&mtd->dev, "mtd%d", i);
dev_set_drvdata(&mtd->dev, mtd);
of_node_get(mtd_get_of_node(mtd));
error = device_register(&mtd->dev);
if (error)
goto fail_added;
device_create(&mtd_class, mtd->dev.parent, MTD_DEVT(i) + 1, NULL,
"mtd%dro", i);
pr_debug("mtd: Giving out device %d to %s\n", i, mtd->name);
/* No need to get a refcount on the module containing
the notifier, since we hold the mtd_table_mutex */
list_for_each_entry(not, &mtd_notifiers, list)
not->add(mtd); /* 在这里找注册链表注册所有链表里注册的方式 */
实际上在上述add函数中倍注册的就是块设备的注册方式如下所示
static struct mtd_notifier blktrans_notifier = {
.add = blktrans_notify_add,
.remove = blktrans_notify_remove,
};
static void blktrans_notify_add(struct mtd_info *mtd)
{
struct mtd_blktrans_ops *tr;
if (mtd->type == MTD_ABSENT)
return;
list_for_each_entry(tr, &blktrans_majors, list)
tr->add_mtd(tr, mtd);
}
/* 在块设备中进行注册的 */
static struct mtd_blktrans_ops mtdblock_tr = {
.name = "mtdblock",
.major = MTD_BLOCK_MAJOR,
.part_bits = 0,
.blksize = 512,
.open = mtdblock_open,
.flush = mtdblock_flush,
.release = mtdblock_release,
.readsect = mtdblock_readsect,
.writesect = mtdblock_writesect,
.add_mtd = mtdblock_add_mtd, /* 最后实际调用add_mtd_blktrans_dev */
.remove_dev = mtdblock_remove_dev,
.owner = THIS_MODULE,
};
其他执行函数
如mtd_erase,mtd_write,mtd_read,mtd_read_oob,mtd_write_oob等,实际上就是在mtd设备驱动传参函数指针的基础上,增加一些校验,本质还是调用真正的mtd设备驱动中的读写函数
mtdpart
核心函数有两个,一个是parse_mtd_partitions该函数能够解析MTD设备的分区,另一个是allocate_partition该函数用于申请MTD分区。
在分析上述两个函数之前需要先分析以下在mtdcore中的mtd_device_parse_register函数
mtd_device_parse_register
mtd设备注册时都要调用该函数,实际上该函数进行两个核心操作,一个是上面提到的add_mtd_device,另一个是allocate_partition

如上图,是调用的宏,可以看到其传参中type=NULL,parser_data=NULL,parts是MTD设备驱动中的分区情况,nr_parts=分区数
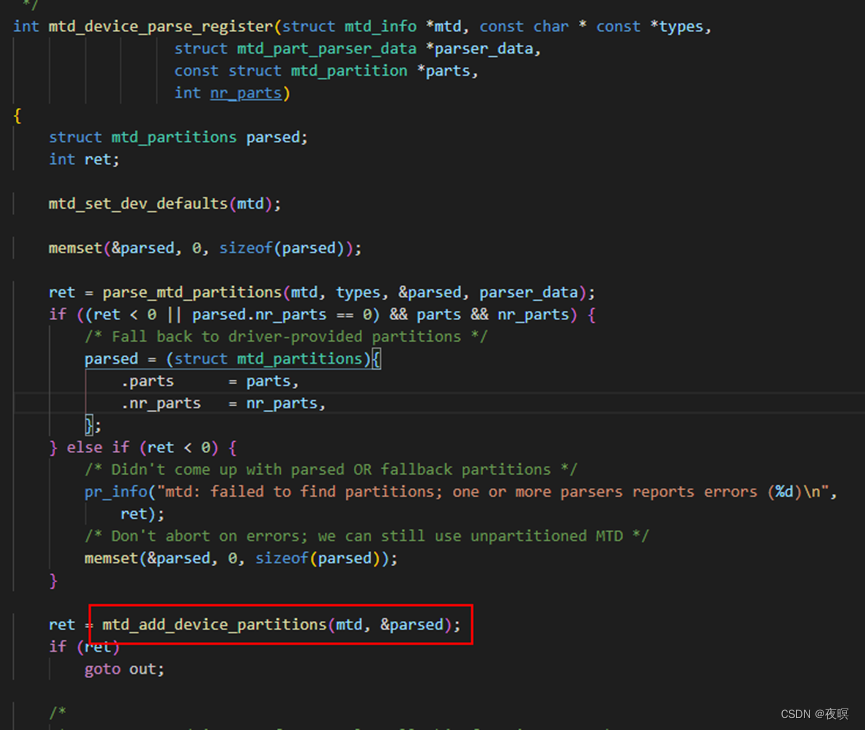
上图为函数源码,当type=NULL时,parse_mtd_partitions就不重要了(从设备树进行解析),也就是说,主体是mtd_add_device_partitions。正常情况下,要想MTD能够使用,都应该有分区,也就是nr_parts>0,即调用add_mtd_partitions
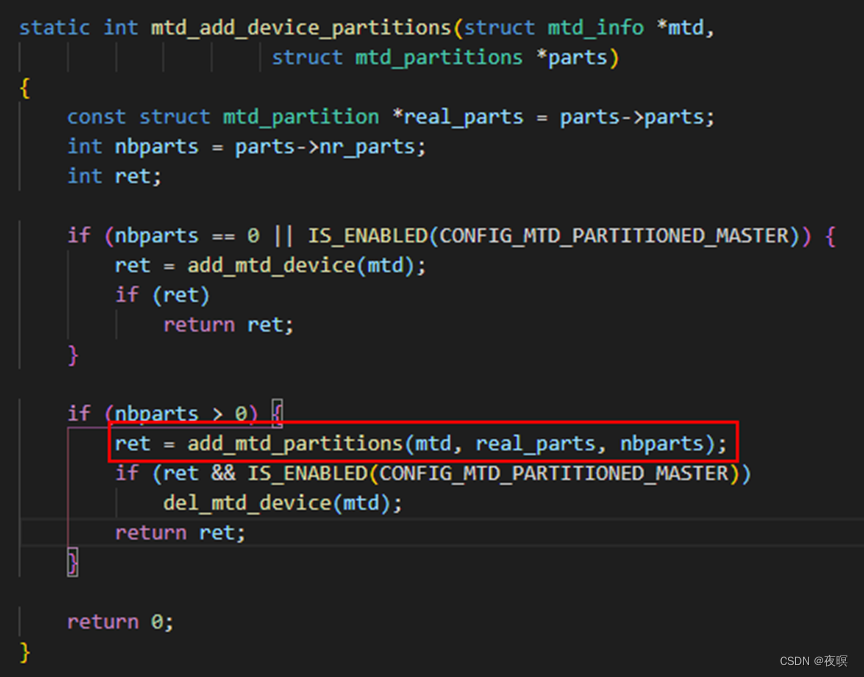
然后该函数调用两个关键函数,一个是上面提到的add_mtd_device,用于添加mtd设备节点,另一个是对分区进行申请
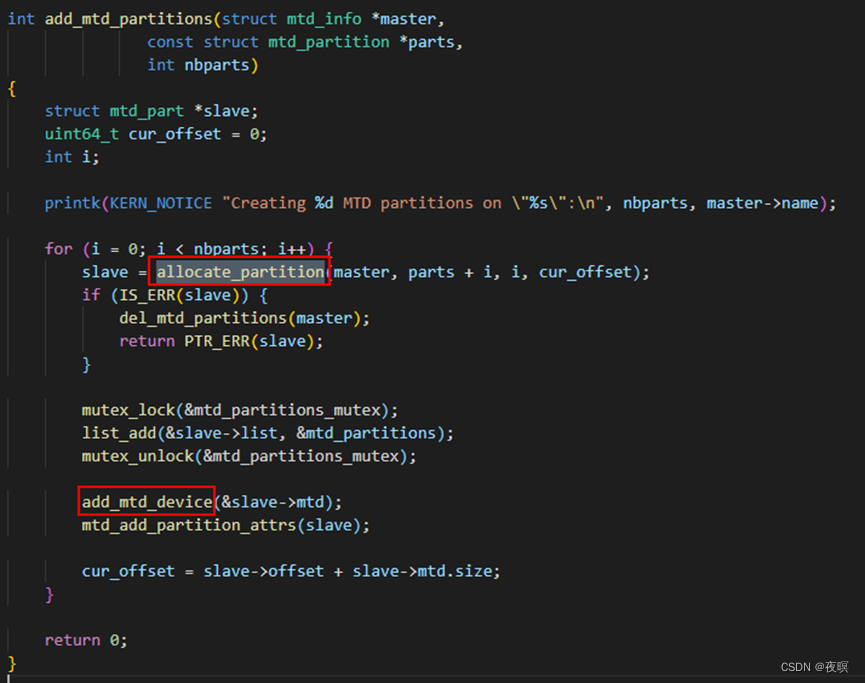
parse_mtd_partitions
其源码如下,正常情况在通过mtd_device_parse_register函数调用时,传参分别为mtd,NULL,&parsed,NULL。即type是个空指针,那么会被置成一个默认的解析类型
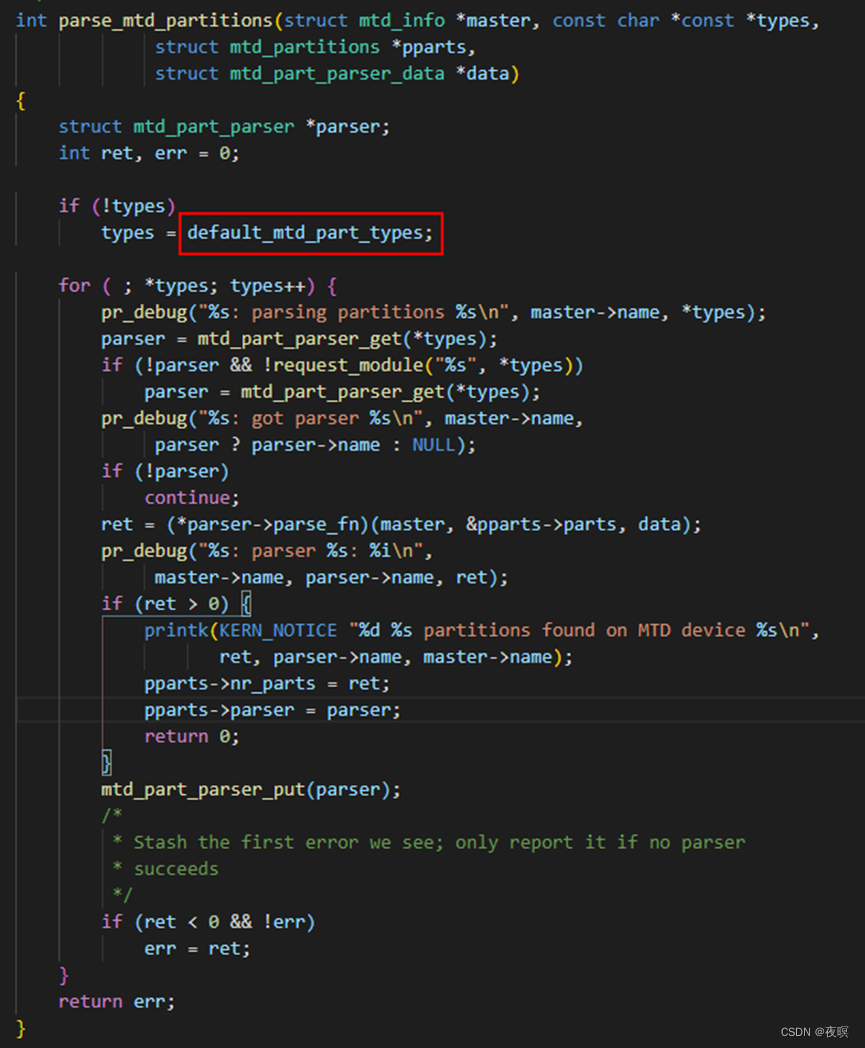
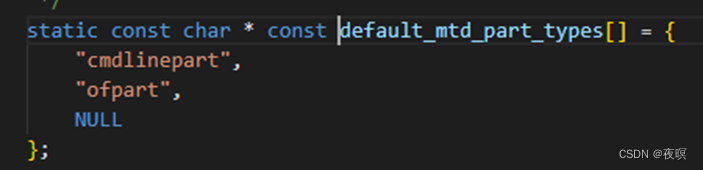
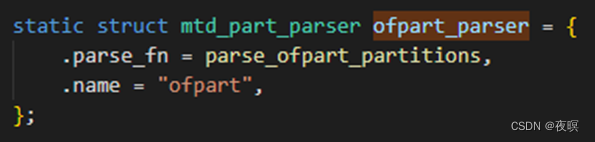
即,最终指向了parse_ofpart_partitions函数,该函数实现从设备树中对mtd分区进行解析,如果设备树中没有对应参数,就不解析了。
allocate_partition
调用该函数时的传参分别为:mtd结构体指针,当前分区信息,当前分区数,以及当前偏移,该函数主要就是为当前分区申请一个分区mtd结构体,最终给该分区注册成mtd设备(也就是说,一个mtd设备可以有多个分区,然后分别注册成不同的mtd设备节点),其中关键就在于分区起始和偏移的计算在该函数中已经计算完成
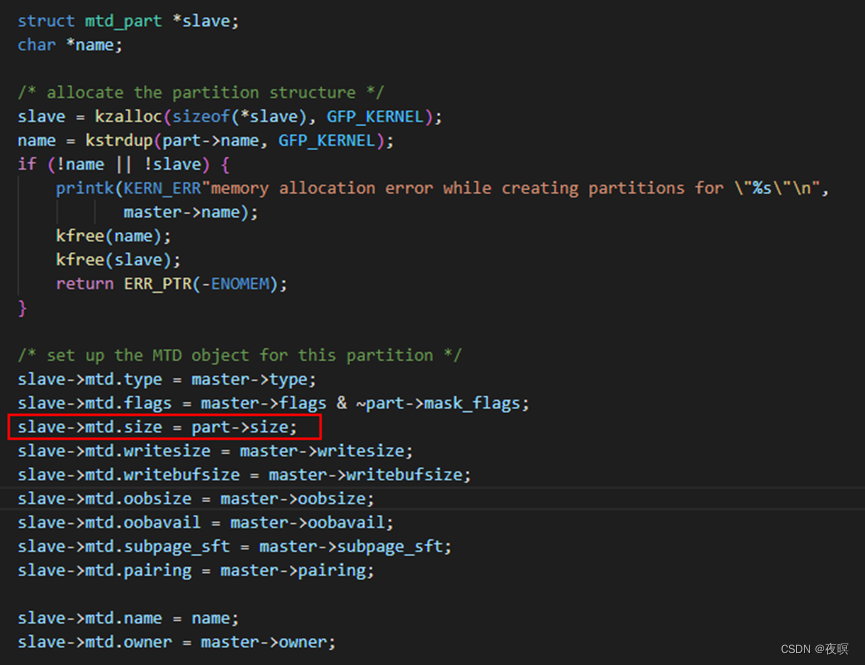
分区会获取mtd设备的主要信息,并额外配置属于分区自身的信息
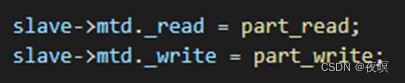
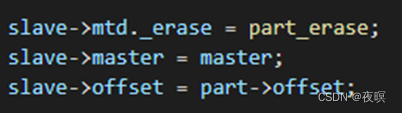
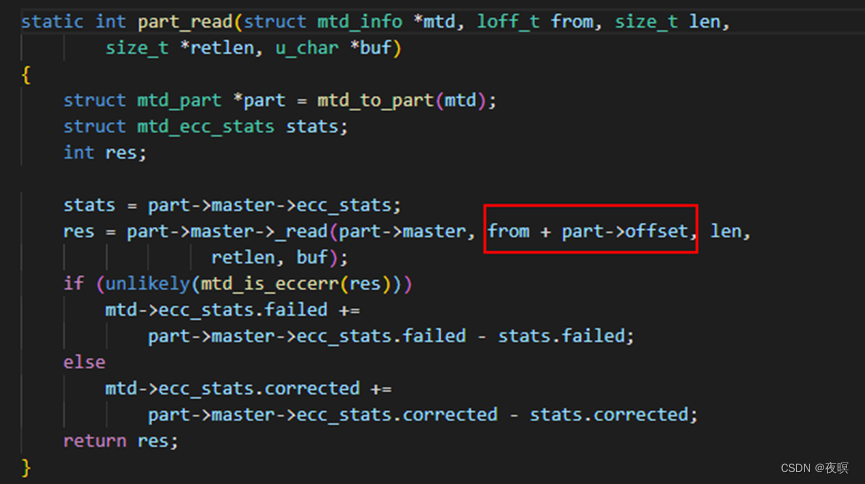
可以看出part_xxx实际上就是在地址的基础上加上一个偏移(分区的起始地址)进行读写擦除的操作。这样一来就直接屏蔽掉了设备驱动那边的地址偏移计算,mtd层都已经做好了


















 121
121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











