







 本文介绍如何使用Selenium模块爬取京东网站上的商品信息,包括价格、评论数及店铺名称等,并通过Python代码实现数据的抓取与保存。
本文介绍如何使用Selenium模块爬取京东网站上的商品信息,包括价格、评论数及店铺名称等,并通过Python代码实现数据的抓取与保存。
文章目录
前言
个人在家闲来无事,想写个爬虫爬取一下某东的信息,但是一般的简易爬虫无法请求到某东的源代码,加上只是个人练手之作,所以决定用了号称"万物可爬"的selenium模块,力求爬取到自己想要的数据。
提示:以下是本篇文章正文内容,下面案例可供参考
一、selenium是什么?
1.什么是selenium
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法执行javaScript代码的问题。
2.selenium的用途
(1)、selenium可以驱动浏览器自动执行自定义好的逻辑代码,也就是可以通过代码完全模拟成人类使用浏览器自动访问目标站点并操作,那我们也可以拿它来做爬虫。
(2)、selenium本质上是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等…进而拿到网页渲染之后的结果,可支持多种浏览器
二、使用开发步骤
1、引入库
想用这个模块肯定要引入其相应的第三方库了,这就是导入库的代码,没有这个模块的要先装上哦。
代码如下(示例):
import csv
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
2.函数:管理浏览器操作open_brower()
1.实例化浏览器对象(打开浏览器}
首先有些电脑可能会出现浏览器通过驱动打开后又自动关闭的现象,所以我找到了一个防止此情况的方法,如下加上启动配置,但是不要忘了最后加上关闭程序,要不然会占很大后台的,我就是血淋淋的教训…
代码如下:
def open_brower():
# 不自动关闭浏览器
option = webdriver.ChromeOptions()
# option.add_argument(f'--proxy-server=http://{ip}')
option.add_experimental_option("detach", True)
# 实例化1个谷歌浏览器对象
# 注意此处添加了chrome_options参数
driver = webdriver.Chrome(options=option)
# 开始
driver.get('https://www.jd.com/')
# driver.maximize_window() # 全屏
2.搜索商品
定位到搜索输入框,通过代码输入商品名词,然后进行回车操作,成功控制台显示成功字样,否则fail。

# 定位输入框
input_box = driver.find_element_by_xpath('//*[@id="key"]')
time.sleep(0.3)
# 输入关键词:selenium
input_box.send_keys("电脑")
time.sleep(0.3)
# 模拟回车操作
try:
input_box.send_keys(Keys.ENTER)
time.sleep(0.3)
print('成功搜索!!!')
except Exception as e:
print('fail')
3.进行get_data函数操作,并进行翻页
for循环控制点击下一页次数,进行get_data操作,通过xpath定位到翻页按钮,设置点击事件,休眠1s.,最后关闭浏览器
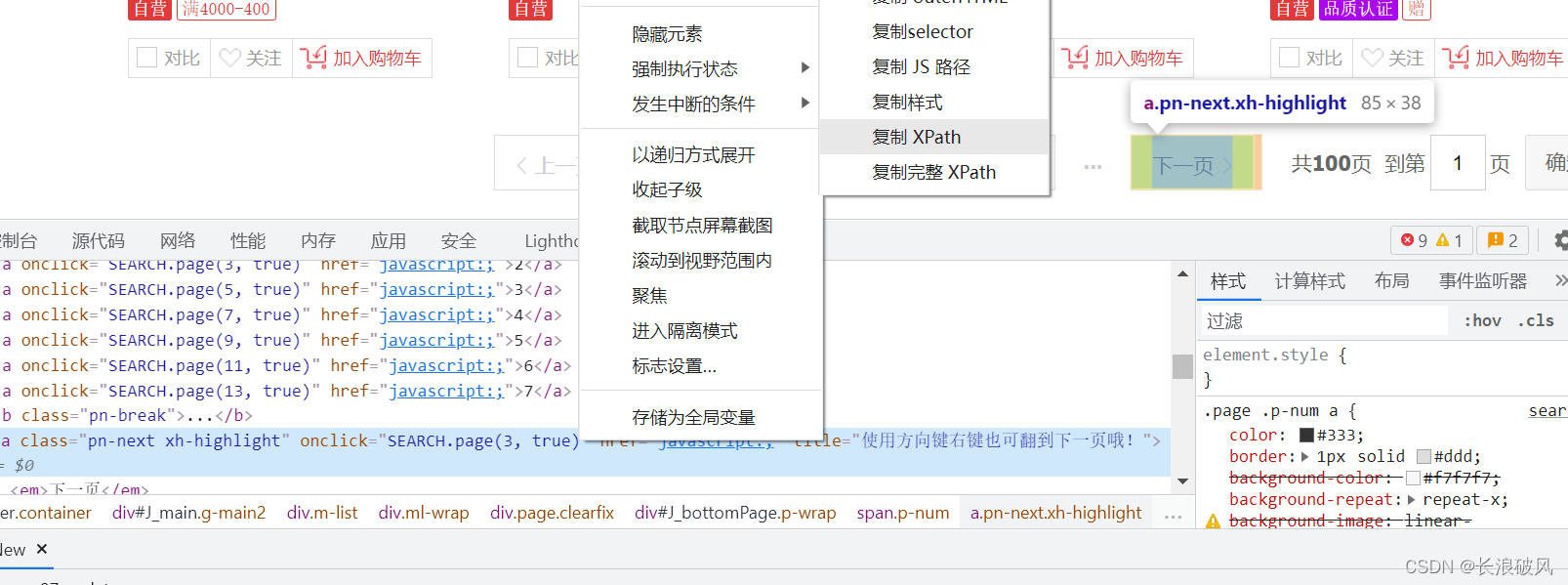
for i in range(1, 10):
get_data(driver)
time.sleep(1)
key = driver.find_element_by_xpath('//*[@id="J_bottomPage"]/span[1]/a[9]')
# key.send_keys(Keys.ARROW_RIGHT)
print(str(key.text) + "第 %s 页" % str(i+1))
# # 定位搜索按钮
# button = driver.find_element_by_xpath('/html/body/div[5]/div[2]/div[2]/div[1]/div/div[3]/div/span[1]/a[9]/em')
# # 执行单击操作
key.click()
time.sleep(1)
driver.close()
3.函数:定位提取所求信息get_data
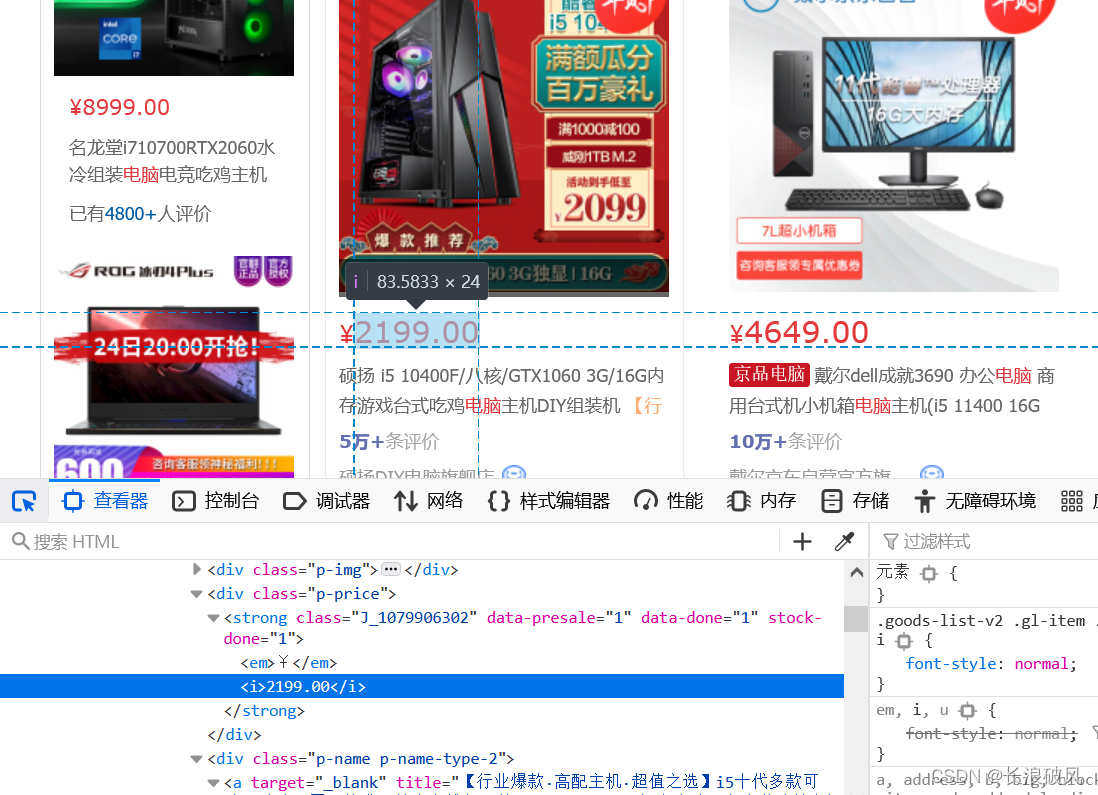
1.在检查页面里成功找出商品数据——“价格” 正确的xpath地址,然后通过“driver.find_elements_by_xpath”方法找出一页上全部此类信息,其他信息同上方法获取,然后将获取的参数传入data_creat函数中,并进行data_creat操作。
def get_data(driver):
prices = driver.find_elements_by_xpath("/html/body/div[5]/div[2]/div[2]/div[1]/div/div[2]/ul/li/div/div[2]/strong/i")
infos = driver.find_elements_by_xpath("/html/body/div[5]/div[2]/div[2]/div[1]/div/div[2]/ul/li/div/div[3]/a/em")
comment_nums = driver.find_elements_by_xpath(
"/html/body/div[5]/div[2]/div[2]/div[1]/div/div[2]/ul/li/div/div[4]/strong")
stores = driver.find_elements_by_xpath("/html/body/div[5]/div[2]/div[2]/div[1]/div/div[2]/ul/li/div/div[5]/span/a")
data_creat(infos, prices, comment_nums, stores)
4.函数:数据保存本地data_creat
设立函数,确定需要参数,for循环分别遍历并保存为列表中,然后进行csv的行写入。
def data_creat(infos, prices, comment_nums, stores):
for i, p, c, s in zip(infos, prices, comment_nums, stores):
li = []
# print(i.text, p.text, c.text, s.text)
li.append(i.text)
li.append(p.text)
li.append(c.text)
li.append(s.text)
csv_writer.writerow(li)
print("-----OK-----")
5.主函数
创建文件对象并写入第一行数据标题为列表头,然后进行open_brower函数运行,此函数调用get_data函数,其中调用data_creat函数;最后关闭文件流。
if __name__ == '__main__':
# 1. 创建文件对象
f = open('JD_data.csv', 'wb', encoding='utf-8')
# 2. 基于文件对象构建 csv写入对象
csv_writer = csv.writer(f)
# 3. 构建列表头
csv_writer.writerow(["信息", "价格/元", "评论数/条", "店铺名称"])
open_brower()
f.close()
程序设计完毕
总结
注意:根据自身的实际情况尽量设置足够的休眠时间等待页面刷新完全。
以上就是今天要讲的内容,本文仅仅简单介绍了selenium的使用,爬取到了某东搜索出现的电脑信息数据,selenium自动化很好用但是效率较慢,毕竟它是依赖于网页刷新的。
以下为本次爬虫全部源码:
import csv
import time
from selenium import webdriver
from selenium.common import exceptions
# selenium异常模块
from selenium.webdriver.common.keys import Keys
def open_brower():
# f = pd.read_csv("ip_list/ip_list.csv")
# ip = f.sample(n=1, random_state=None)
# print(ip)
# 不自动关闭浏览器
option = webdriver.ChromeOptions()
# option.add_argument(f'--proxy-server=http://{ip}')
option.add_experimental_option("detach", True)
# 实例化1个谷歌浏览器对象
# 注意此处添加了chrome_options参数
driver = webdriver.Chrome(options=option)
# 开始
driver.get('https://www.jd.com/')
# driver.maximize_window() # 全屏
# 定位输入框
input_box = driver.find_element_by_xpath('//*[@id="key"]')
time.sleep(0.3)
# 输入关键词:selenium
input_box.send_keys("电脑")
time.sleep(0.3)
# 模拟回车操作
try:
input_box.send_keys(Keys.ENTER)
time.sleep(0.3)
print('成功搜索!!!')
except Exception as e:
print('fail')
# page = input("请输入爬取页面数:"+"\n")
for i in range(1, 10):
get_data(driver)
time.sleep(1)
key = driver.find_element_by_xpath('//*[@id="J_bottomPage"]/span[1]/a[9]')
# key.send_keys(Keys.ARROW_RIGHT)
print(str(key.text) + "第 %s 页" % str(i+1))
# # 定位搜索按钮
# button = driver.find_element_by_xpath('/html/body/div[5]/div[2]/div[2]/div[1]/div/div[3]/div/span[1]/a[9]/em')
# # 执行单击操作
key.click()
time.sleep(1)
driver.close()
def get_data(driver):
prices = driver.find_elements_by_xpath("/html/body/div[5]/div[2]/div[2]/div[1]/div/div[2]/ul/li/div/div[2]/strong/i")
infos = driver.find_elements_by_xpath("/html/body/div[5]/div[2]/div[2]/div[1]/div/div[2]/ul/li/div/div[3]/a/em")
comment_nums = driver.find_elements_by_xpath(
"/html/body/div[5]/div[2]/div[2]/div[1]/div/div[2]/ul/li/div/div[4]/strong")
stores = driver.find_elements_by_xpath("/html/body/div[5]/div[2]/div[2]/div[1]/div/div[2]/ul/li/div/div[5]/span/a")
data_creat(infos, prices, comment_nums, stores)
# print(stores)
# print(prices)
# print(comment_nums)
# print(infos)
def data_creat(infos, prices, comment_nums, stores):
for i, p, c, s in zip(infos, prices, comment_nums, stores):
li = []
# print(i.text, p.text, c.text, s.text)
li.append(i.text)
li.append(p.text)
li.append(c.text)
li.append(s.text)
csv_writer.writerow(li)
print("-----OK-----")
if __name__ == '__main__':
# 1. 创建文件对象
f = open('JD_data.csv', 'wb', encoding='utf-8')
# 2. 基于文件对象构建 csv写入对象
csv_writer = csv.writer(f)
# 3. 构建列表头
csv_writer.writerow(["信息", "价格/元", "评论数/条", "店铺名称"])
open_brower()
f.close()
各位看官大佬,点个关注再走吧😊



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











