







 本文介绍了2017年Google和Facebook提出的两个Seq2Seq任务的创新成果,它们分别是《Attention Is All You Need》和《Convolutional Sequence to Sequence Learning》。两者都不依赖于RNN模型,而是使用Attention机制或CNN结构进行序列到序列的转换。
本文介绍了2017年Google和Facebook提出的两个Seq2Seq任务的创新成果,它们分别是《Attention Is All You Need》和《Convolutional Sequence to Sequence Learning》。两者都不依赖于RNN模型,而是使用Attention机制或CNN结构进行序列到序列的转换。
今天我要讲的是2017年的两篇seq2seq任务中最新的两个科研成果,分别参考了2017年Google团队在NIPS上的论文《Attention Is All You Need》和2017年Facebook团队在ICML上的论文《Convolutional Sequence to Sequence Learning》。目前业界主流方法在解决seq2seq任务的时候往往采取的是encoder-decoder架构,由于是序列的编码和生成,因此RNN系列模型(如LSTM、GRU)等被看出是解决该问题的最好方法。但是,由于RNN模型包含有循环的结构,这个循环结构特性给它的训练速度优化带来了很大的困难(很难像CNN等模型一样采用分布式并行的优化策略)。因为为了摆脱seq2seq任务对RNN的依赖,工业界的两个大牛公司Google和Facebook提出了两个非RNN系列的模型。
首先要介绍的是Google的《Attention Is All You Need》,从题目也可以看出来,这篇论文完全没有利用到任务目前主流的深度学习框架(比方说RNN、CNN等),巧妙的使用Attention技术完成了对source目标和target目标的编解码工作。整个模型的整体架构如下:
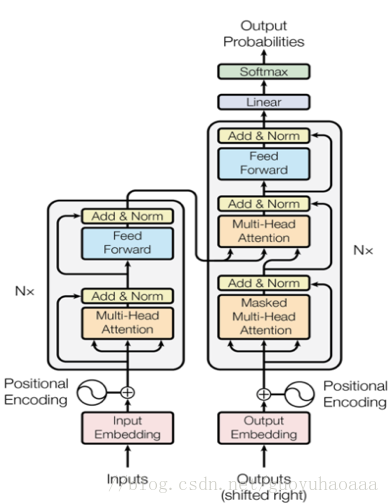
从图中可以很清楚地看出左边部分是encoder,右边是decoder。下面我们分别来讲解一下encoder和decoder。
Encoder:
从下往上看,首先Input Embedding就是普通的词向量矩阵,在进入正式的网络结构之前会加上一个positional Encoding,这个结构我也是第一次接触。其实它加入的主要目的是为了加入句子中的词序信息,这个positional Encoding就是对词语序列的编码(脱离了RNN的架构,词语序列信息只能通过这种方式加进去)。具体做法是,按照词语从左到右的出现顺序,给每一个绝对的位置分配一个对应的Embedding向量,这个向量随机初始化然后随着模型一起训练。但是Google这篇论文,除了这种方式又提出了一种自己的方式,具体生成方式如下:
PE(pos,2i)=sin(pos/100002i/dmodel)PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}})PE(pos,2i)=sin(pos/100002i/dmodel)
PE(pos,2i+1)=cos(pos/100002i/dmodel)PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}})PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中pospospos就代表了词语在原始句子中的序号,iii值的是当前生成标量在词向量中的维度编号。Google这样做的目的是在进行位置编码的时候不仅仅考虑了词语在原始句子中的绝对位置,而且考虑了词语之间的相对位置信息,根据高中时期的三角函数知识,PEpos+kPE_{pos+k}PEpos+k可以写成PEposPE_{pos}PEpos的线性组合形式。最后Google的几个研究员也证明了这种方式比随着模型训练出来的稍微好一点。
(但是我对于这种直接把位置向量和词向量相加的方式感到怀疑,总感觉这样的方式并不能有效地引入位置信息,具体效果以后可以通过实验测试一下)
当词向量信息加入位置信息之后,就会通过一个由N词操作串联而成的网络结构,可以看到这个大结构由两个小的部分组成,一个叫做“Multi-Head Attention”,另一个叫做“Feed Forward”。同时从图中不难看出这两个部分都引入了残差结构,并使用了Layer Normalization技术(注:Layer Normalization不同于Batch Normalization技术,具体的细节我将在下一篇博客详细论述)。下图就是Multi-Head Attention的结构图:
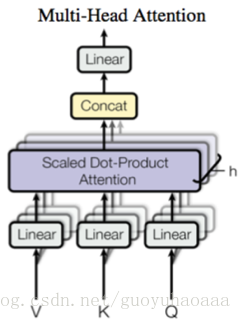
其中VKQVKQVKQ分别代表了value,key和query,这里就涉及对attention机制的本质解释,key和value是一一对应的,Attention计算一般分为三个步骤:1 将query和key进行相似度计算得到权重,常用的相似计算函数有点积,拼接和感知机等;2 使用softmax函数对这些权重进行归一化;3 使用归一化得到的权重对value进行加权求和,得到最后的attention表征。在NLP任务中,key和value往往是一样的。
Attention(Q,K,V)=softmax(QKTdk)VAttention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})VAttention(Q,K,V)=softmax(dkQKT)V
之所以除了一个常数dk\sqrt{d_k}dk,是为了避免softmax中的乘积过大导致结果过多向softmax的s型函数的两端偏移。实现multi-head的具体方式就是将QKVQKVQKV分别乘以不同的参数矩阵,然后对每一个变换后的副本进行attention操作,对所有multi的结果进行concat操作,具体的操作变换如下:
MultiHead(Q,K,V)=concat(head1,head2,.....headh)WoMultiHead(Q,K,V)=concat(head_1,head_2,.....head_h)W^oMultiHead(Q,K,V)=concat(head1,head2,.....headh)Wo
headi=Attention(QWiQ,KWiK,VWiV)head_i=Attention(QW_i^Q,KW_i^K,VW_i^V)headi=Attention(QWiQ,KWiK,VWiV)
讲了这么多,还没有对encoder模块中的multi-attention具体操作步骤进行论述,其实简单来讲就是一句话:在Google提出的模型中QKVQKVQKV都是一样的,都是当前输入句子中的词语,multi-Attention的目的是使用句子中其他词语的加权求和来表征当前的词语。
下面的模块Feed Forward其实是一个非常简单的结构,其公式如下所示:
FFN(x)=max(0,xW1+b1)W2+b2FFN(x)=max(0,xW_1+b_1)W_2+b_2FFN(x)=max(0,xW1+b1)W2+b2
虽然Feed Forward的形式非常简单,但是我想强调一点的是这个Feed Forward是poistion-wise的操作,因为一句话中的每一个词语都会经过该单元,由于句子的长度nnn是一个变量,所以这个操作不是针对整个句子矩阵的,而是针对句子中的每一个词语,在词语的级别上进行相同的变换操作。(poistion指的就是句子中的不同词语)
Decoder:
接下来就会通过decoder模块,从图中不难看出decoder由三个部分组成,第一个部分的Masked multi-head Attention结构整体来说和encoder的multi-head是基本一样的,唯一不同的是在进行解码的时候只能知道该时刻之前生成的词语,所以这里的attention只使用了当前词之前时刻的词语信息。接下来的decoder中的multi-head Attention中的query是来自自己的上一层的词语表征,而key和value则是来自于encoder生成的词向量,后面的feed forward和encoder中的就是一致的了。
Google提出的这个框架就介绍完了,可以看出他完全没有使用CNN和RNN等基础的系列模型架构,只是使用了attention机制,计算所有词语之间的相似度,不但大大加快了模型的训练速度,而且更加适合提取句子内部的结构性的依赖关系。
接下来要介绍的是Facebook提出的《Convolutional Sequence to Sequence Learning》,他完全利用了CNN结构替代了RNN,整个网络的结构如下:
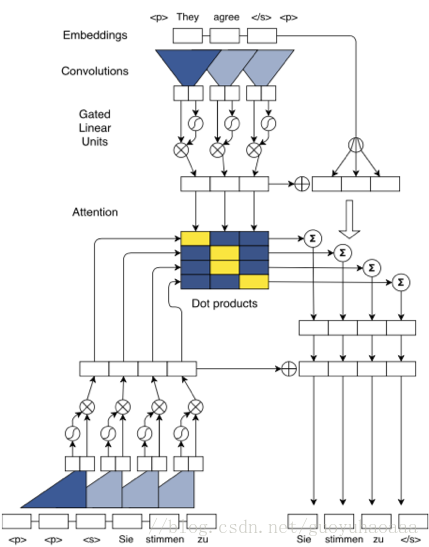
(说实话这个架构图我第一次看也是一脸的懵逼,感觉画的不是很形象。)
为了方便大家的理解,我先把整个模型拆分一下,从整体先讲一下整个模型:
1 输入序列e={e1,e2,.....em}e={\{e_1,e_2,.....e_m}\}e={e1,e2,.....em}和Google提出的模型一样,都是词向量加上位置向量信息得到的;
2 在Decoder每一时刻的输入序列g={g1,g2,.....gm}g={\{g_1,g_2,.....g_m\}}g={g1,g2,.....gm},同样由两部分组成,词向量和对应的位置向量;
3 Decoder 中的第l个block的输出定义为hl=(h11,h2l,....hnl)h^l=(h_1^1,h_2^l,....h_n^l)hl=(h11,h2l,....hnl)
4 Encoder 中的第l个block输出zl=(z1l,z2l,....zml)z^l=(z_1^l,z_2^l,....z_m^l)zl=(z1l,z2l,....zml)
Encoder:
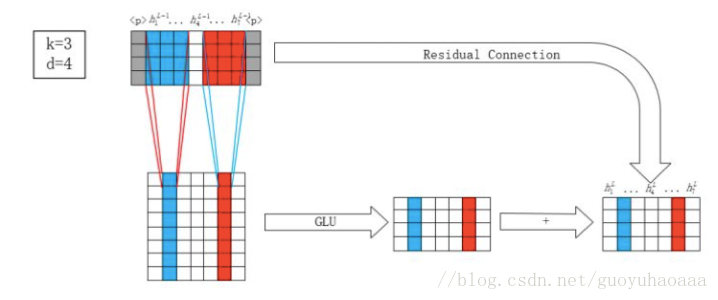
如上图所示,图形的上面部分代表了encoder, 可以看出由一个卷积操作和一个非线性操作组成,同时使用了残差结构来把输入和输出数据进行相加。假设输入的词向量矩阵维度是X∈RL∗dX\in R^{L*d}X∈RL∗d,ddd代表了词向量的维度,L代表了句子中的词语数量,那么卷积操作的维度是W∈R2d∗kdW\in R^{2d*kd}W∈R2d∗kd,其中kd指的是卷积器的宽度,2d指的是卷积器的数量,这样我们对原始的句子处理就得到了维度为S∈R(L−k+1)∗2dS\in R^{(L-k+1)*2d}S∈R(L−k+1)∗2d。不难看出这个时候一个词语所对应向量的维度变成了2d2d2d,好像无法进行残差相加,其实这是因为作者使用了一种被称为GLU(Gated Linear Unit)的激活单元函数,这个激活函数其实本质和LSTM中的门结构是相同的,其函数形式如下:
GLU(x)=(X∗W+b)∗sigmoid(X∗V+b)GLU(x)=(X*W+b)* sigmoid(X*V+b)GLU(x)=(X∗W+b)∗sigmoid(X∗V+b)
在论文中的定义如下:
v([AB])=A∗σ(B)v([A B])=A * \sigma(B)v([AB])=A∗σ(B) 其中A和B维度都是ddd,v([AB])v([A B])v([AB])的维度经过运算也是d。整个encoder操作会循环d次。整个操作示意图如下所示,图中的灰色部分代表了padding:
Decoder:
在解码阶段,使用被称之为“Multi-step Attention”的技术,其实所谓“Multi-step”就说明了这个解码器是由多层操作组成的,那么解码器第l层的计算公式如下所示:
dil=Wdlhil+bdl+gid_i^l=W_d^lh_i^l+b_d^l+g_idil=Wdlhil+bdl+gi
αijl=exp(dil∗zj)∑t=1mexp(dil∗zt)\alpha_{ij}^l=\frac{exp(d_i^l*z_j)}{\sum_{t=1}^mexp(d_i^l*z_t)}αijl=∑t=1mexp(dil∗zt)exp(dil∗zj)
cil=∑j=1mαijl(zj+ej)c_i^l=\sum_{j=1}^m \alpha_{ij}^l(z_j+e_j)cil=∑j=1mαijl(zj+ej)
其中zjz_jzj是encoder最后一层的输出,WdlW_d^lWdl和bdlb_d^lbdl为解码器第l层attention的参数矩阵。在得到clc^lcl之后,将其加到decoder当前层的隐层状态hlh^lhl中,然后再输入到decoder的第l+1l+1l+1层中,按照这样的操作,可以得到最终的隐层状态hLh_LhL。
最后可以使用softmax层来计算decoder在i时刻的输出结果:
p(yi+1∣y1,y2,.....yi,x)=softmax(WohiL+bo)p(y_{i+1} | y_1,y_2,.....y_i,x)=softmax(W_oh_i^L+b_o)p(yi+1∣y1,y2,.....yi,x)=softmax(WohiL+bo)。
可以看出上面的两个模型都没有使用RNN,但是他们都巧妙地利用了Attention机制来成功地对目标句子和原句子进行编码。其实他们的方法给我们提供了另一种处理NLP问题的思路,还是非常值得我们去学习的。

















 1408
1408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









